"Realizing this potential in real-world settings has been challenging due to issues with sample complexity, assumptions (e.g., accurate reward functions), and optimization stability."
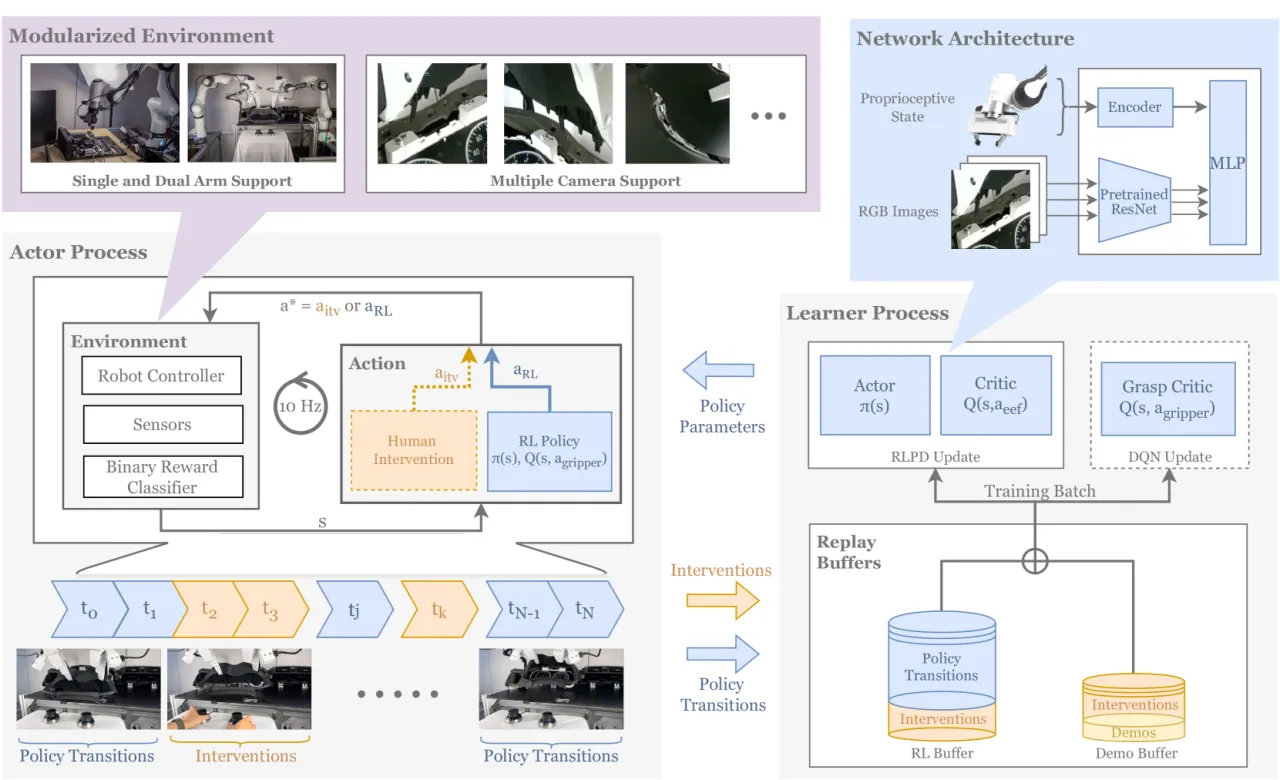
"A human can intervene at any time step ti. When a human intervenes, their action aitv is applied to the robot instead of the policy's action aRL. We store the intervention data in both the demonstration and RL data buffers."
HIL-SERL 针对每个任务独立训练一个策略,需要人工设计观测空间(相机选择与裁剪)、动作空间及奖励分类器。系统尚未展示跨任务的零样本泛化能力。作者在 Discussion 中指出,该系统可作为生成高质量数据的工具,进而用于训练机器人基础模型(robot foundation models),这暗示当前单任务策略的局限性。
仍依赖人类持续参与,难以完全自动化(推断)
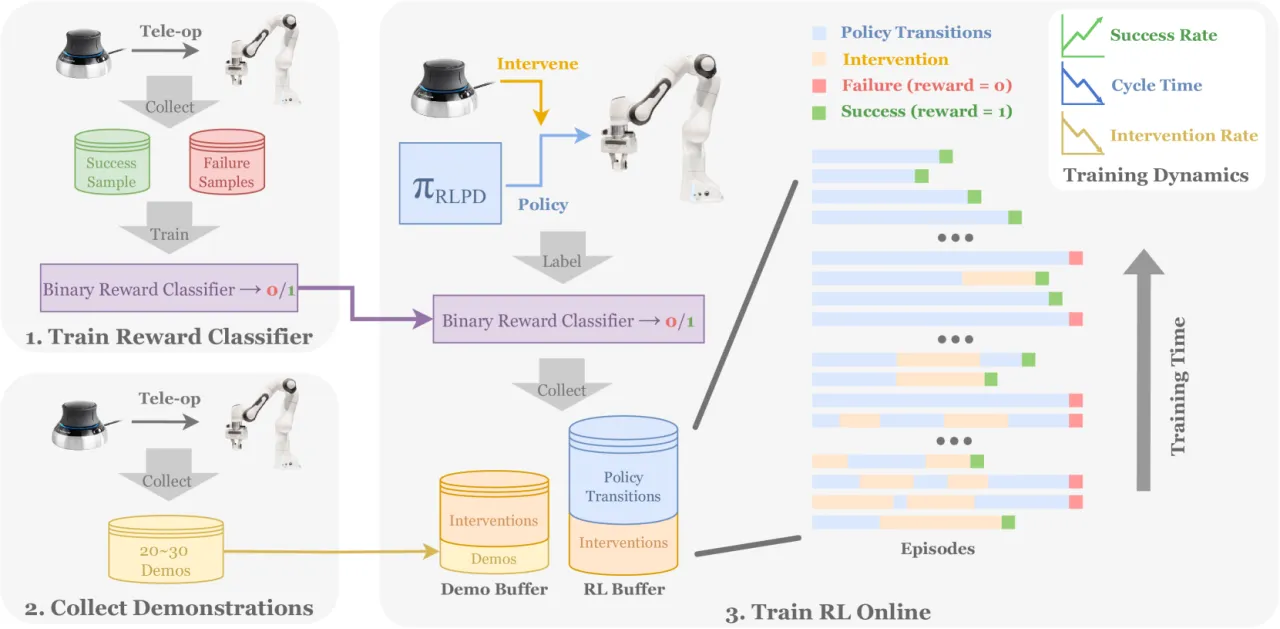
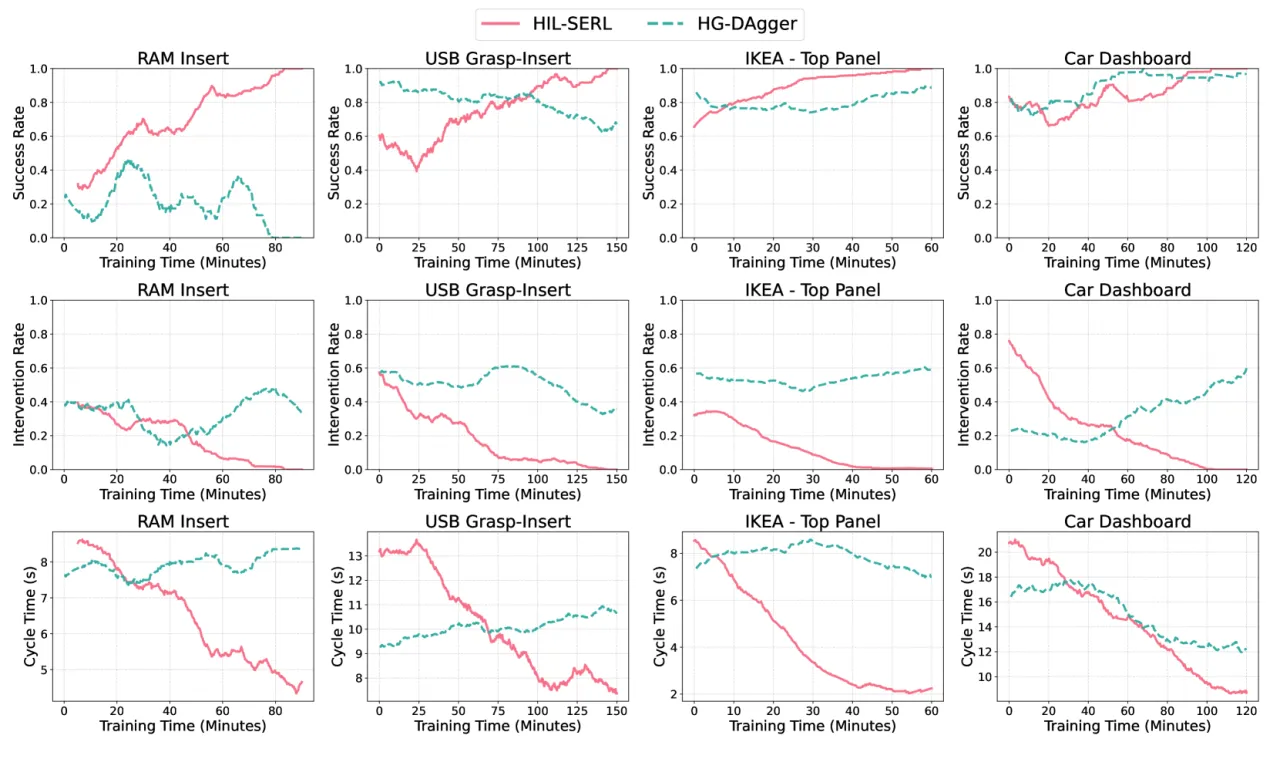
训练过程中需要人类操作员实时监督并提供纠错。论文指出应避免持续提供稀疏的长段干预("we should avoid persistently providing long sparse interventions that lead to task successes"),否则会导致 Q 函数过估计和训练不稳定。对于极端复杂的任务(Timing Belt),训练时长需要 6 小时,仍需大量人工投入。