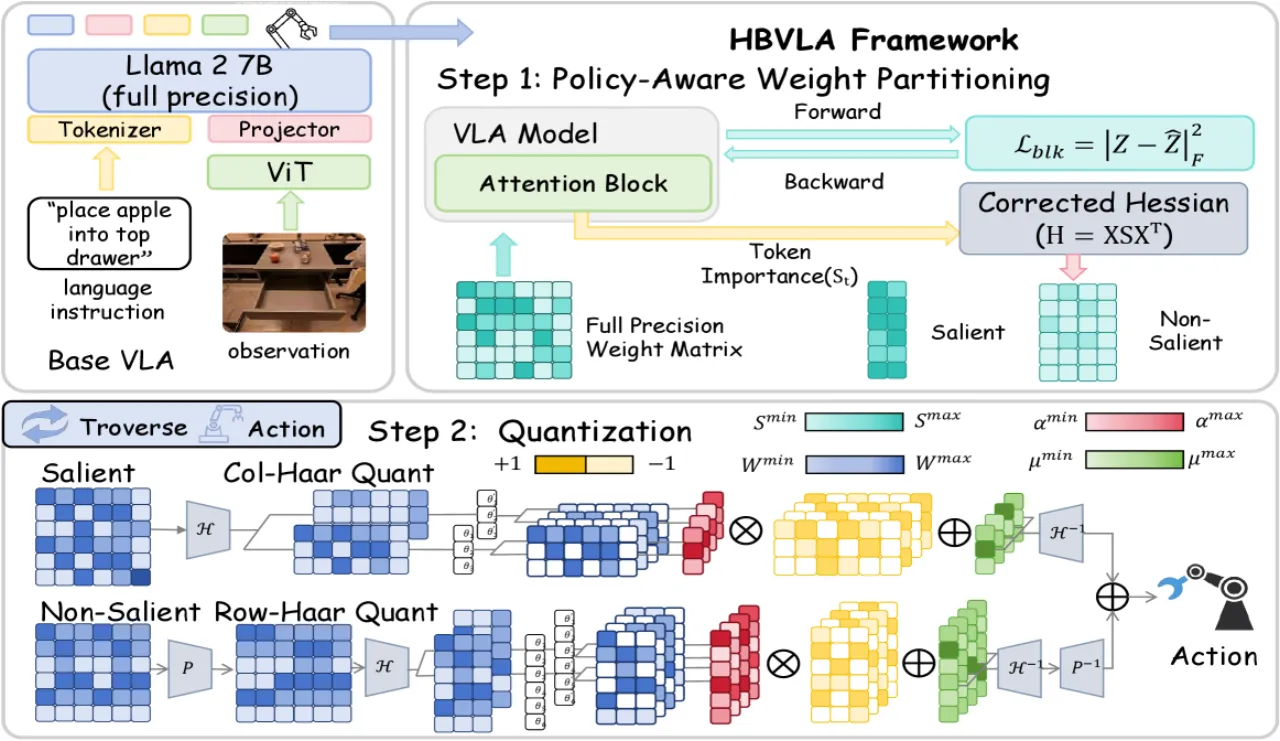
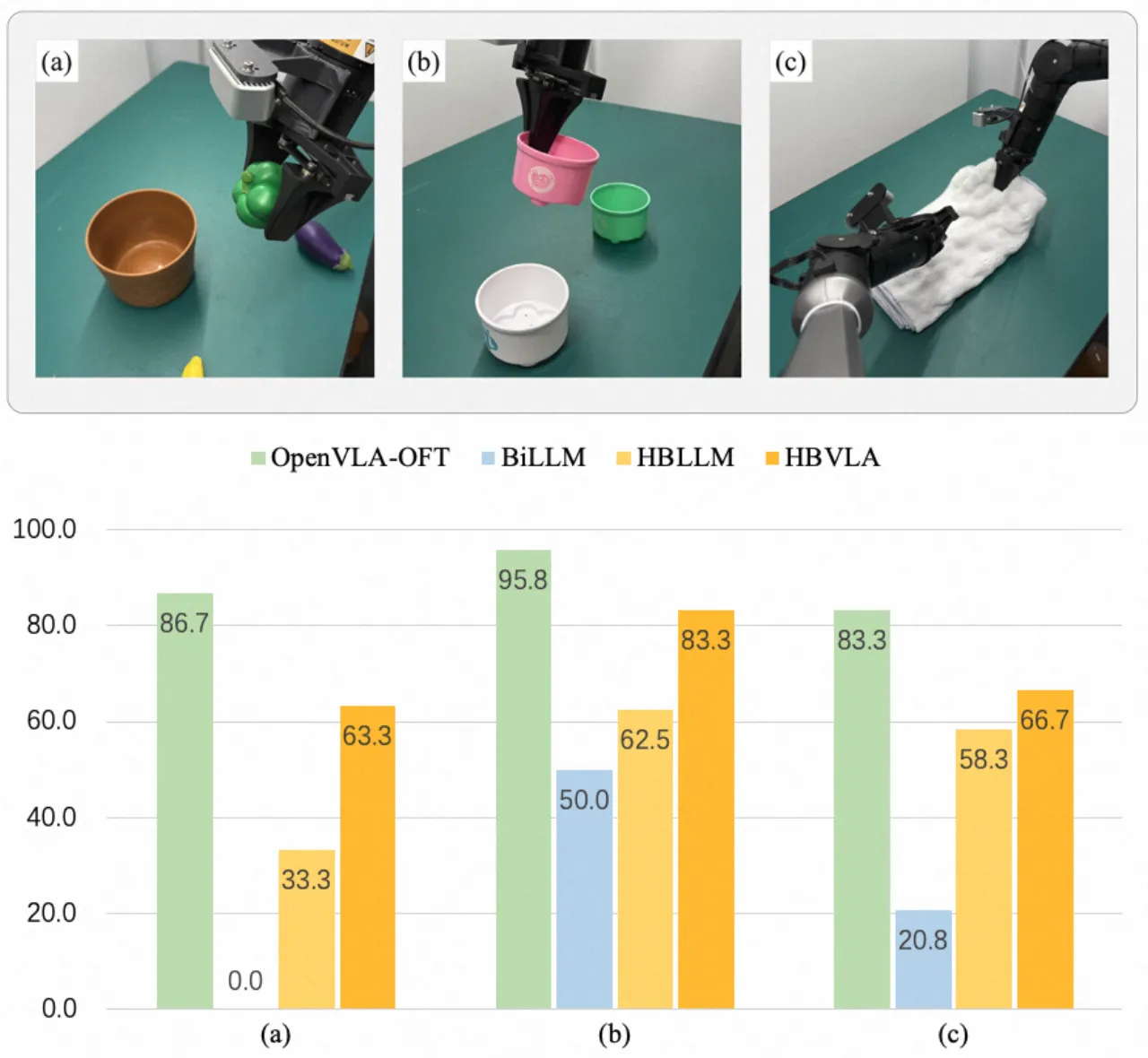
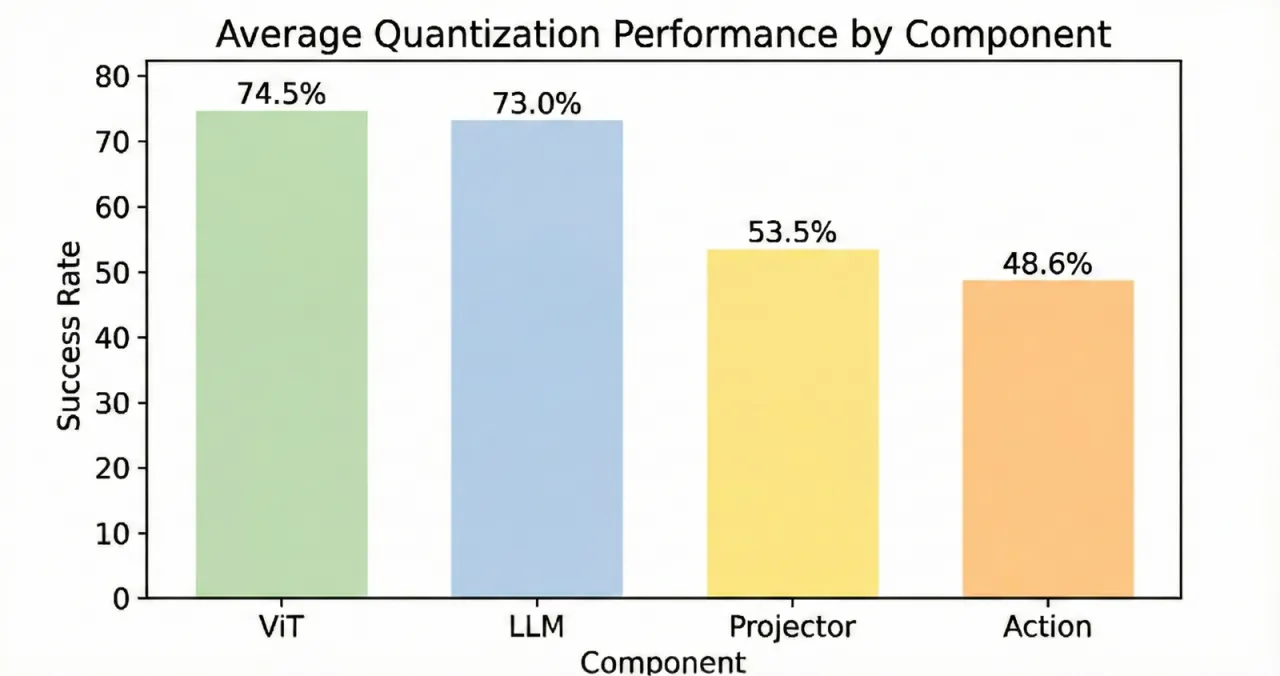
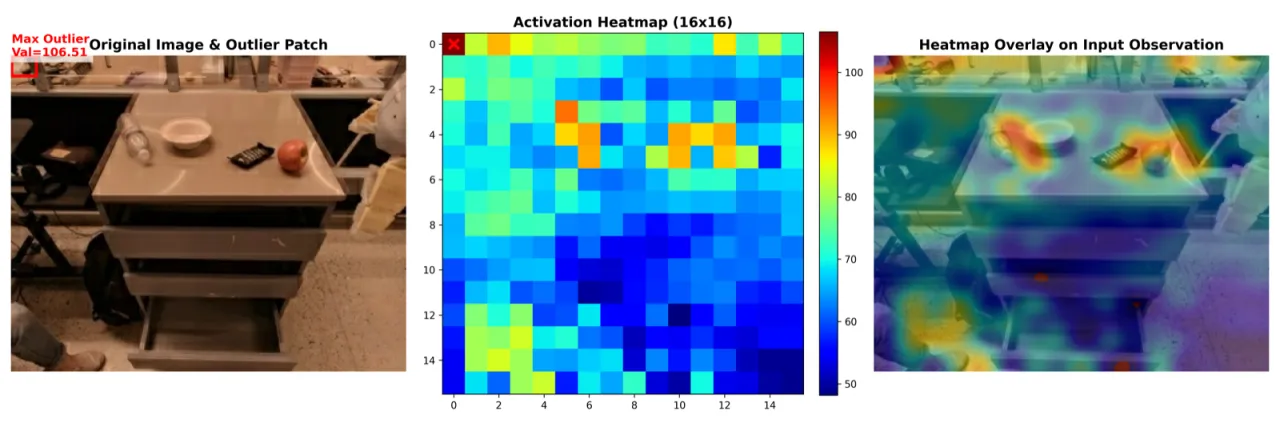
01 动机 Motivation
VLA 模型参数量庞大,难以在资源受限的机器人平台(如移动底座、嵌入式控制器)上实时部署。现有 LLM 二值化方法(BiLLM、BiVLM、HBLLM 等)在 VLA 场景下性能严重下滑,根源在于两类 VLA 特有问题:一是微小量化误差在闭环物理执行中被接触动力学放大、沿长视野任务累积,导致灾难性失败;二是视觉激活存在"双主导"现象(background outliers + visual token 不均衡),遮蔽了任务关键信号。
"Even subtle quantization-induced action deviations can be amplified by contact dynamics and compound over long-horizon execution, leading to catastrophic failures such as unstable grasps or large trajectory drift."
90.3%OpenVLA-OFT 在 LIBERO 保留精度 (1.08 bit)
93.6%CogACT 在 SIMPLER 保留精度 (Visual Matching)
-4.8%CogACT 性能损失 vs. 全精度(Visual Matching 平均)
1.08 bit平均量化位宽(显著低于 INT4/INT8 方案)