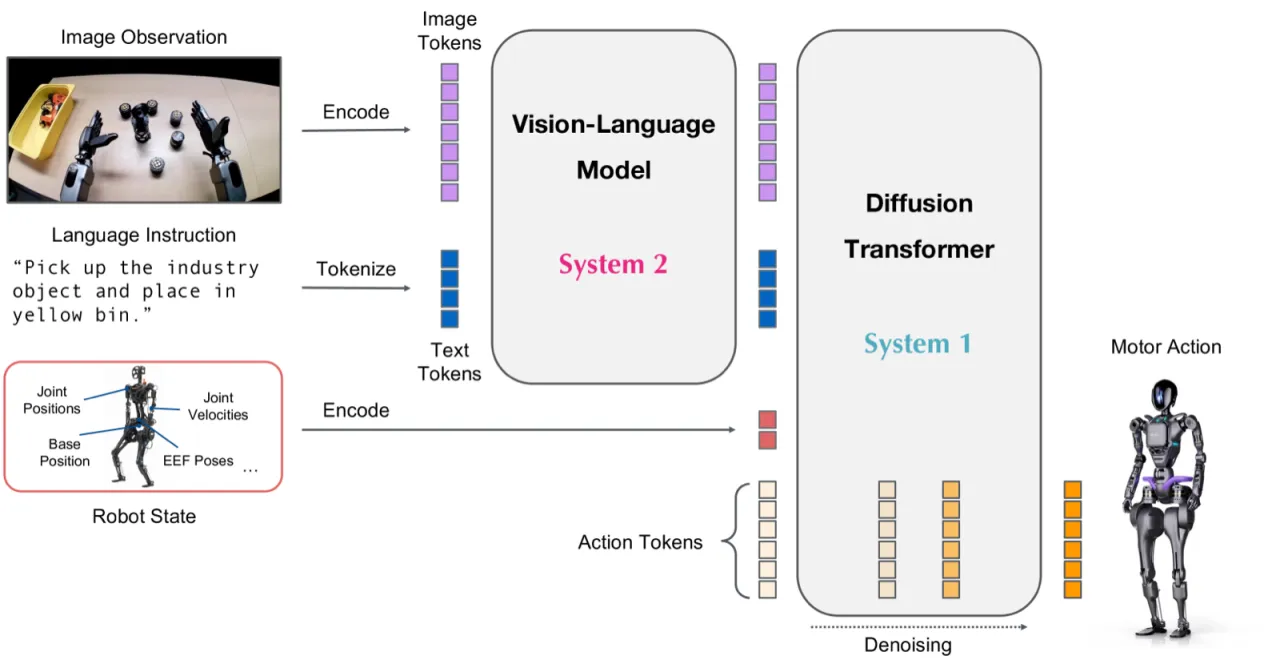
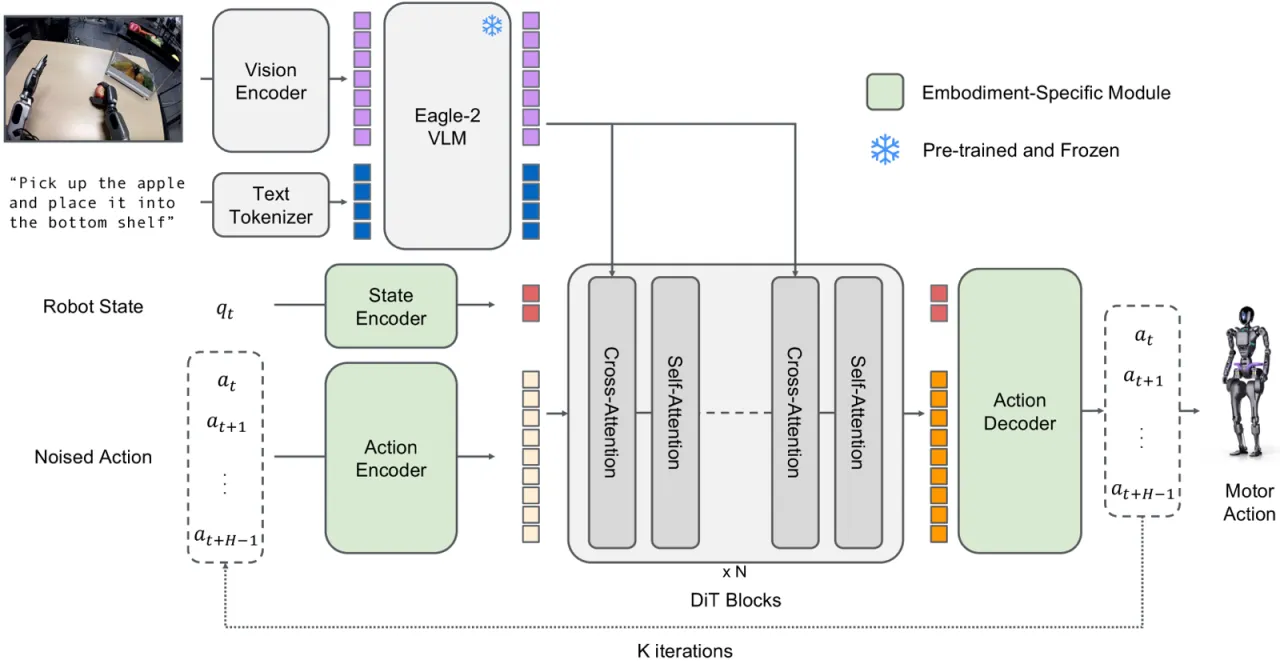
"We introduce GR00T N1, a generalist model for humanoid robots. GR00T N1 adopts a dual-system architecture inspired by cognitive science—a vision-language model as the high-level reasoning (System 2) and a diffusion transformer as the low-level action (System 1)."
"GR00T N1 model focuses primarily on short-horizon tabletop manipulation tasks. In future work, we aim to extend its capabilities to tackle long-horizon loco-manipulation, which will require advancements in humanoid hardware, model architecture, and training corpora."
合成数据生成在物理真实性与多样性上仍有瓶颈
"existing methods still face challenges in generating diverse and counterfactual data, while adhering to the laws of physics, limiting the quality and variability of synthetic datasets." 当前视频生成模型无法保证精确的物理一致性,合成数据可能引入分布偏移。