01 动机
当前 VLA 研究过于依赖简单的数据扩展,而忽视了真实部署中的根本障碍:数据异构性、数据质量参差不齐,以及 behavior cloning 的内在局限。
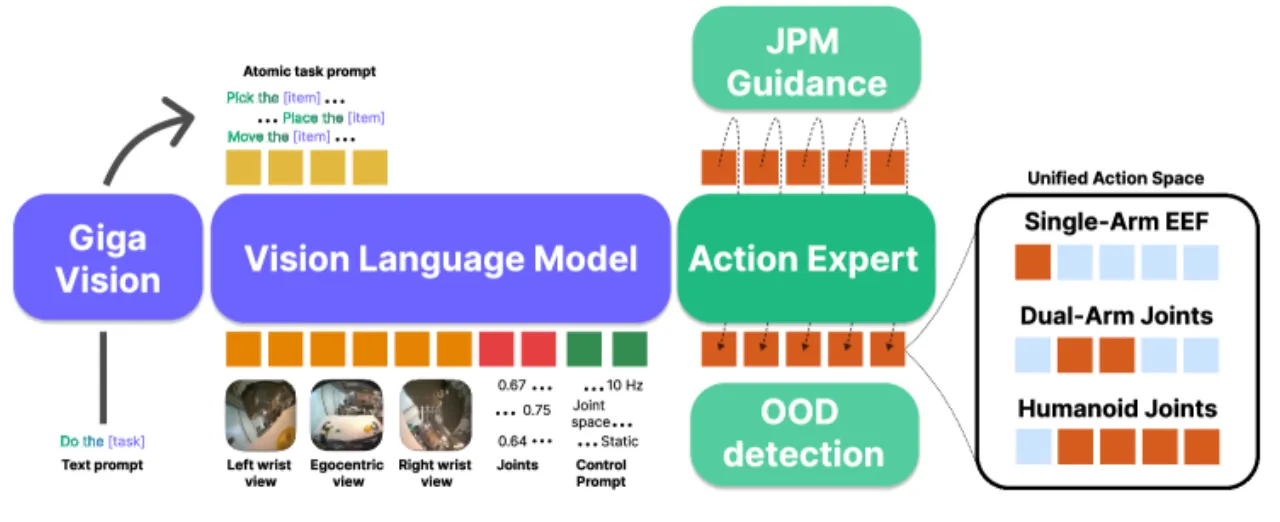
"robotic datasets are inherently heterogeneous in terms of observations, action spaces, and sampling rates"
——数据层面的异构使得跨机器人泛化极为困难。
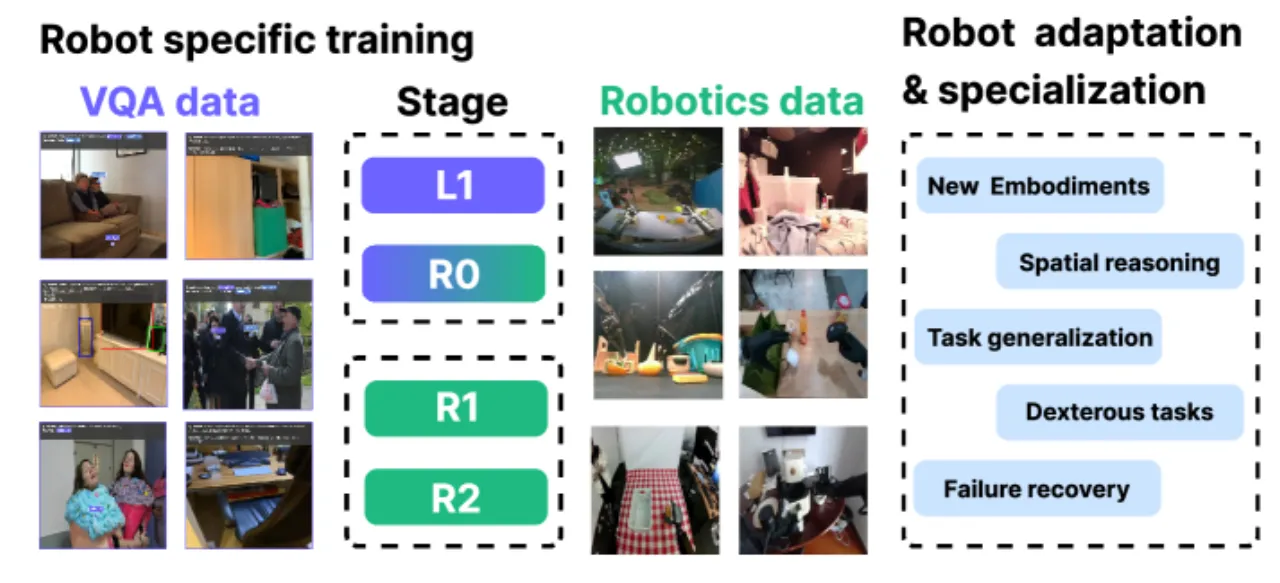
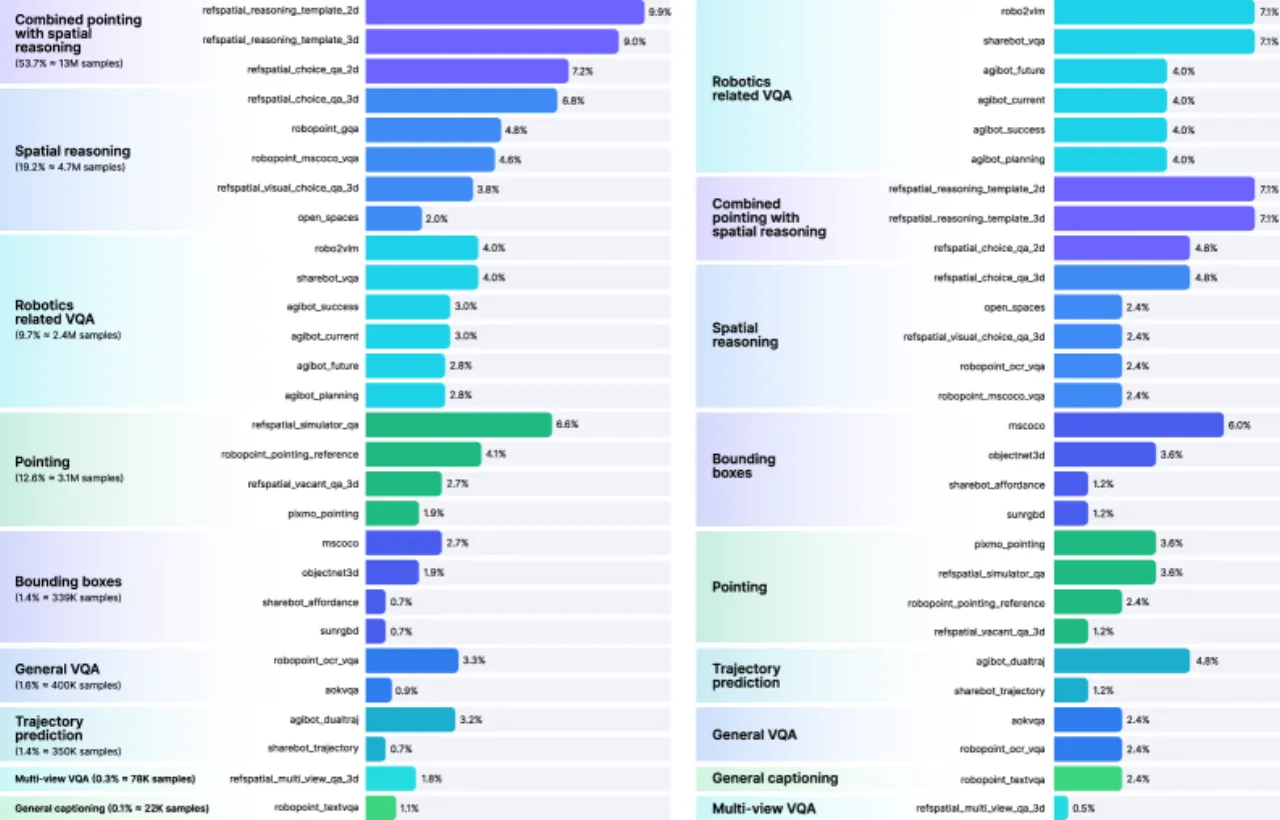
3,000+小时演示数据 (R0 训练)
83.1%ALOHA 双臂清理首项成功率
80.5%WidowX 拣选成功率 (R2)
5B参数规模 (Qwen3-VL-4B backbone)
核心问题诊断
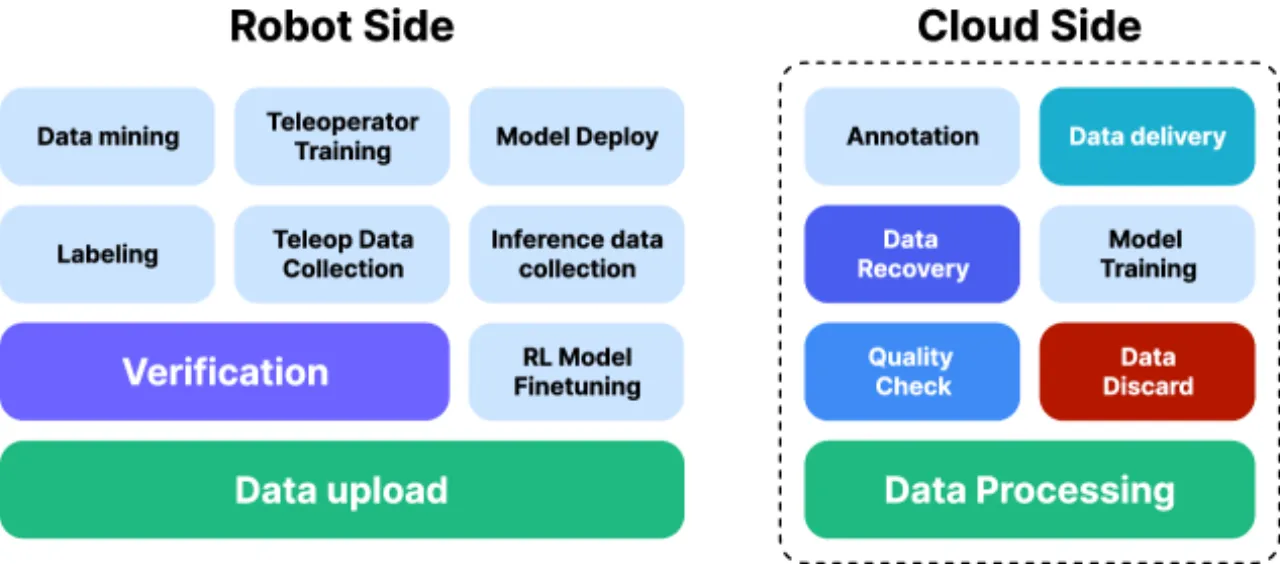
问题一:数据质量
真实机器人数据中大量轨迹存在抖动、模糊帧、执行不一致及场景多样性不足等问题,导致直接扩展数据量收益递减。
问题二:Behavior Cloning 的瓶颈
"the predominant training paradigm remains behavior cloning (BC)…this approach quickly saturates and fails to align policies to long-horizon objectives."
问题三:异构动作空间
不同机器人本体(人形、移动操作臂、固定臂)具有不同的动作维度与语义,简单 zero-padding 会"destroys positive transfer"。
核心主张
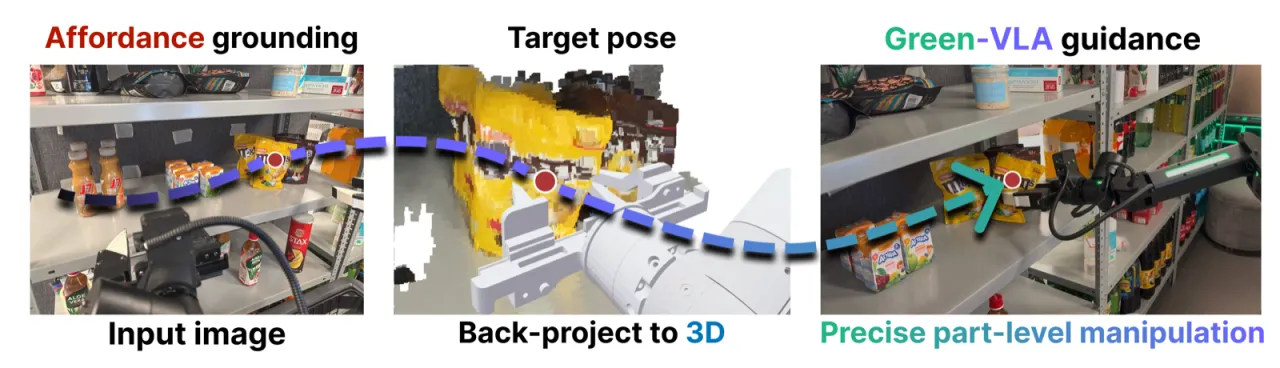
Green-VLA 的方案是"beyond data scaling by emphasizing quality alignment, action unification, and reinforcement learning refinement"。