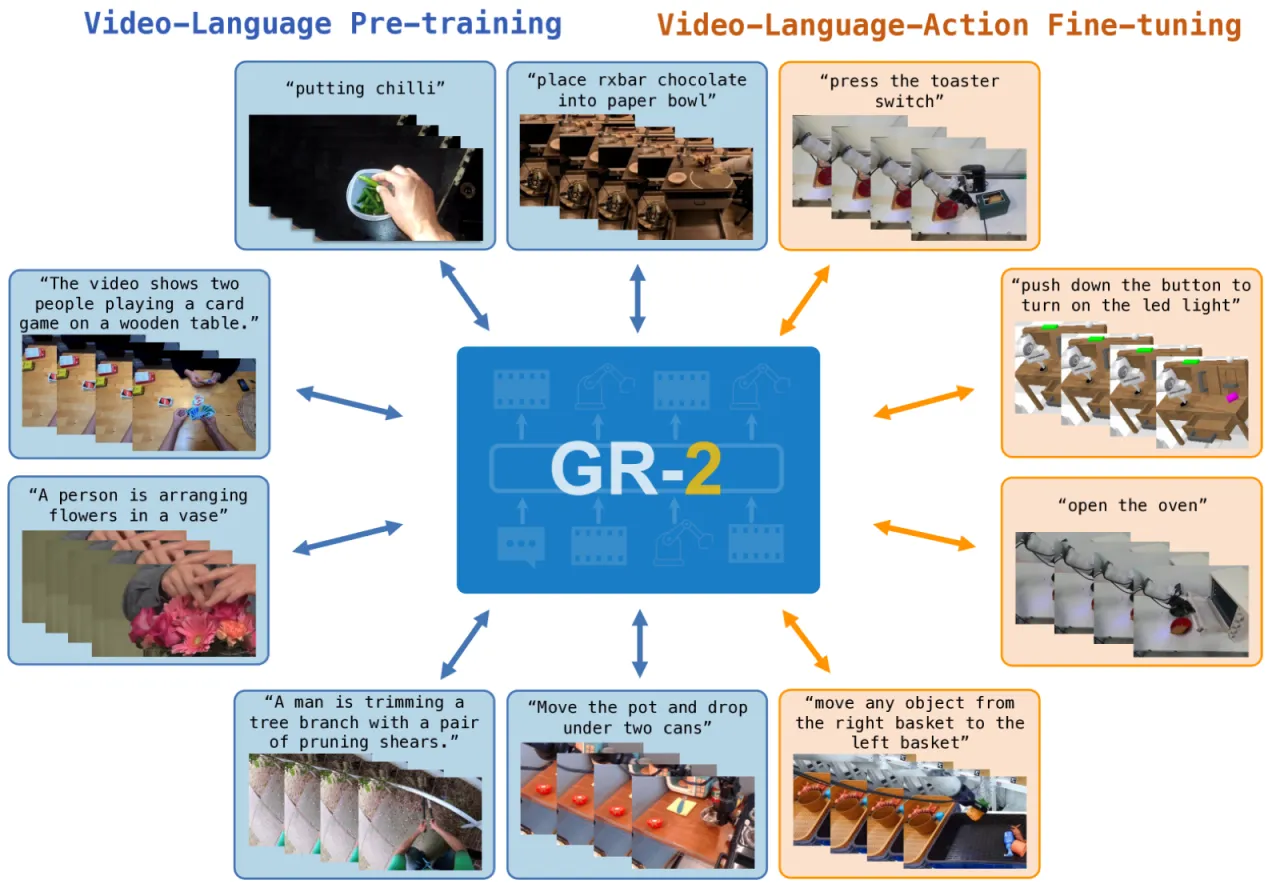
01 动机
机器人操作数据的采集代价高昂,限制了策略学习的规模化。互联网上大量的视频数据蕴含丰富的物体交互知识——如何将这些"免费"的视觉先验有效迁移到机器人策略学习?
"Pre-training on video generation can effectively transfer knowledge to robot policy learning, enabling a generalist robot agent to perform diverse manipulation tasks and generalize to novel environments."

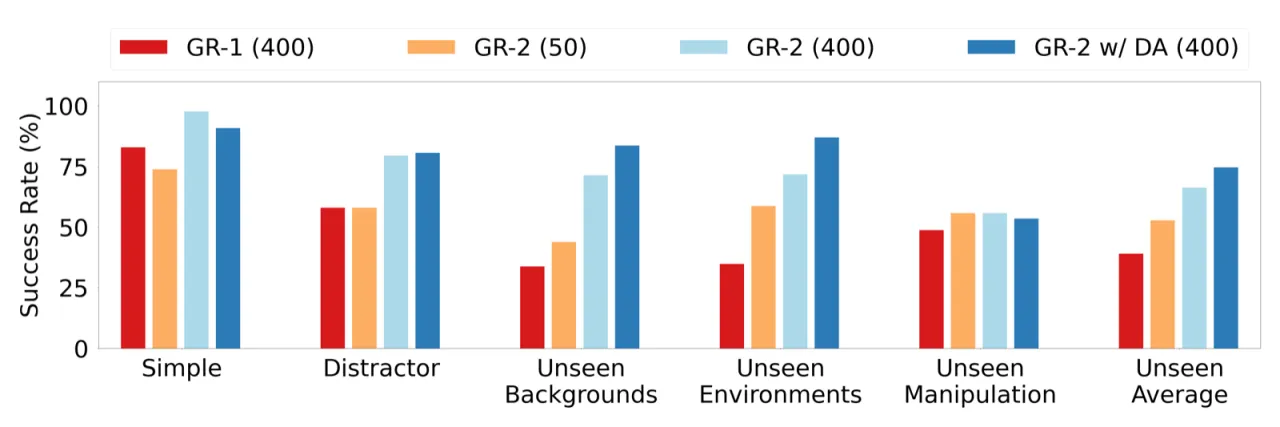
97.7%100+ 任务平均成功率(Simple setting)
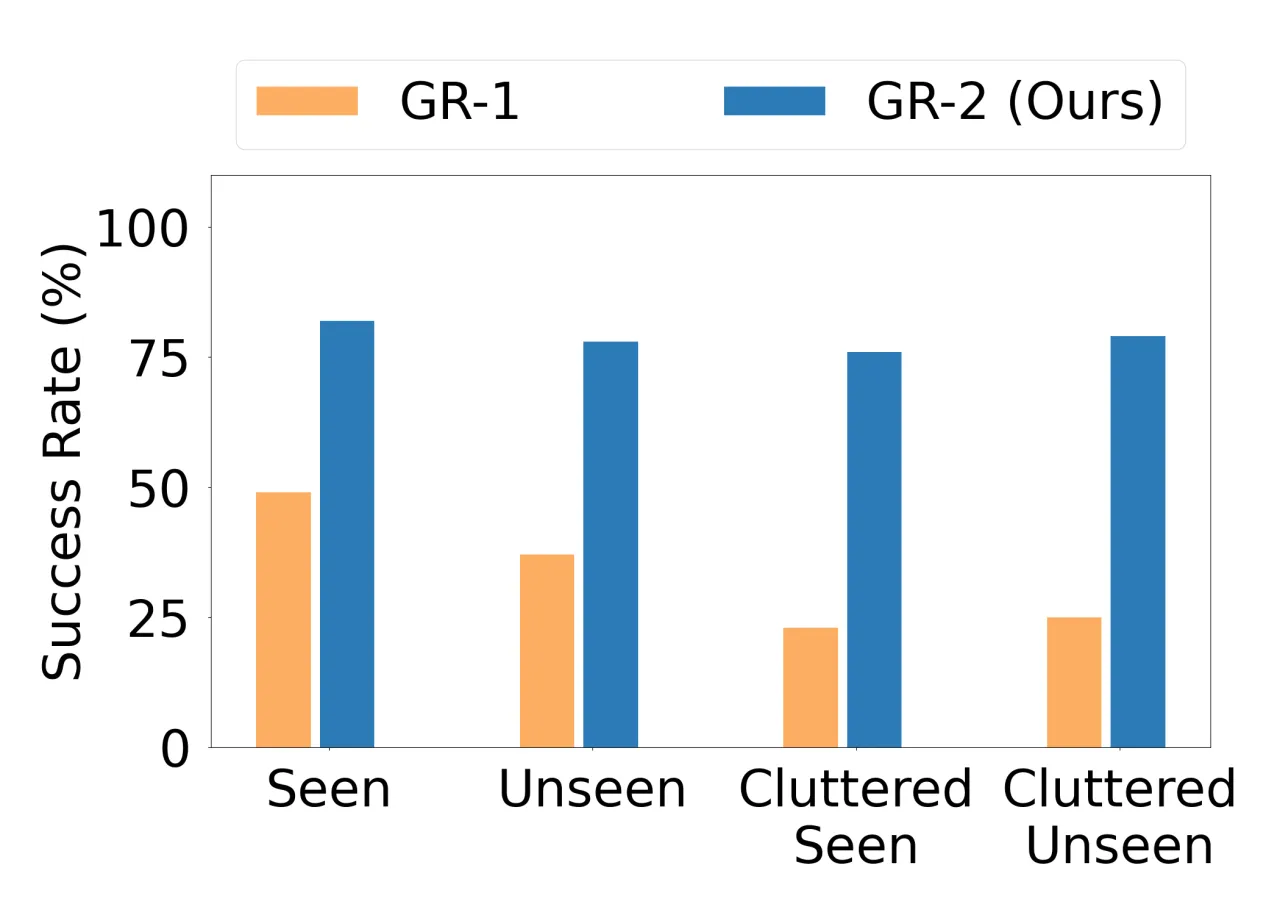
79.0%Bin Picking 平均成功率(GR-1 仅 33.3%)
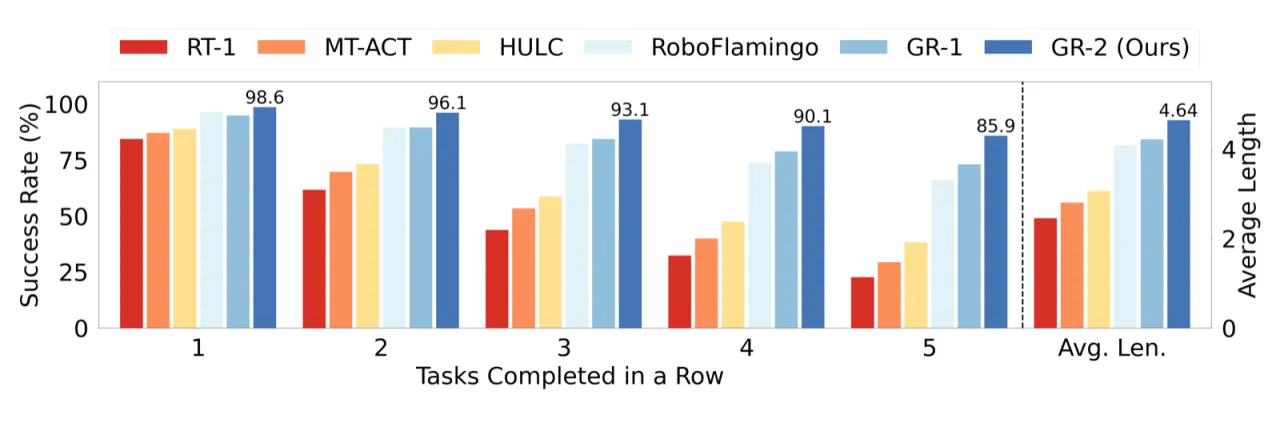
4.64CALVIN 平均连续完成任务数(avg length)
38M预训练视频剪辑数量