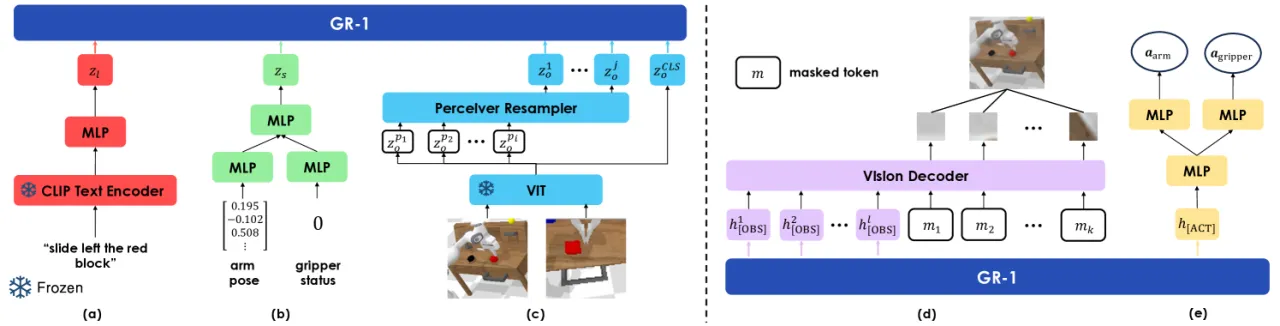
01 动机
大规模生成预训练模型(GPT、DALL-E 等)在语言和视觉领域表现出卓越的效果,但视觉机器人操作领域尚未从中受益。核心障碍在于:机器人数据量稀少、且包含图像、状态、动作、语言等多模态信息,难以直接套用通用预训练范式。
"Inspired by video prediction models that generate future images conditioned on a sequence of video frames and languages, we observe that a robot trajectory itself contains a video sequence. Therefore, video prediction models could potentially learn from internet videos and leverage the learned knowledge to predict future images and generate robot actions."
机器人轨迹本身就是一段视频序列——这一洞察使得互联网视频预训练与机器人控制形成天然对齐:预测未来帧的能力可以直接迁移为"预测未来动作"的能力。GR-1 将视频预测作为预训练代理任务,填补了大规模预训练与机器人操作之间的鸿沟。
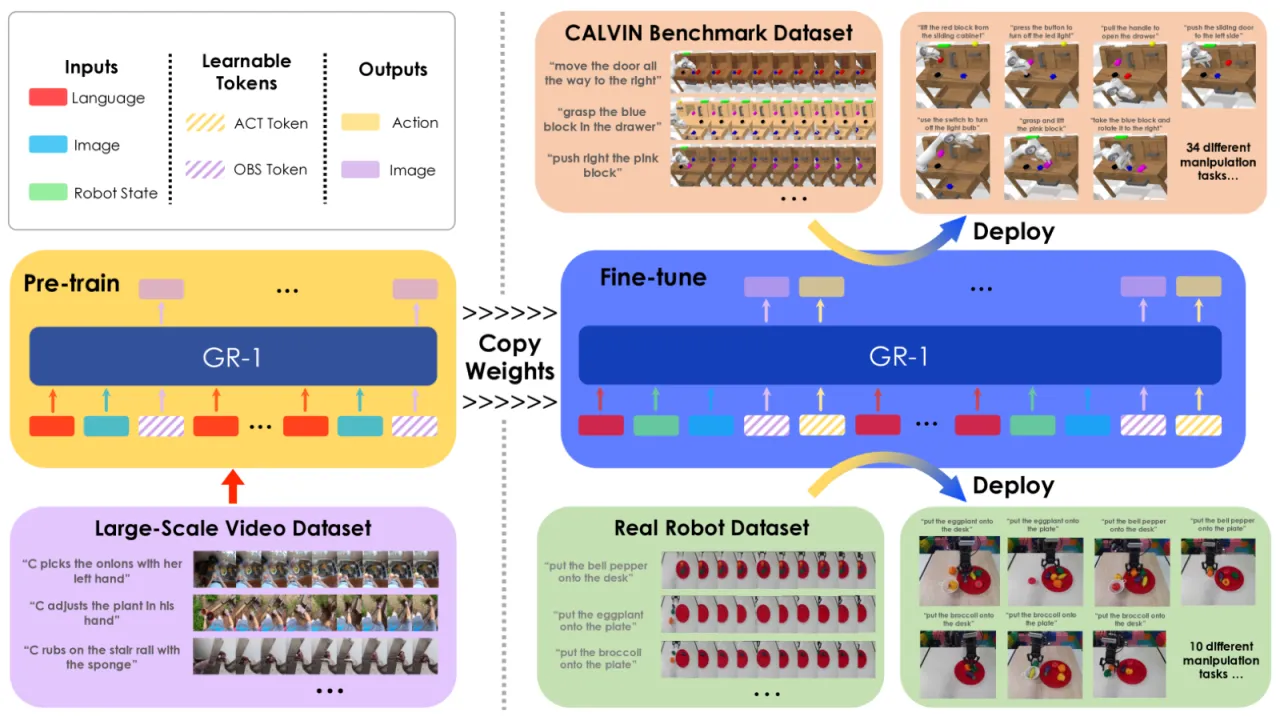
94.9%CALVIN ABCD→D 单任务成功率(前最优 88.9%)
4.21CALVIN 平均连续完成任务数(前最优 3.06)
85.4%零样本未见场景(ABC→D)成功率(前最优 53.3%)
79%真实机器人已见物体搬运成功率(RT-1 仅 27%)