01 动机
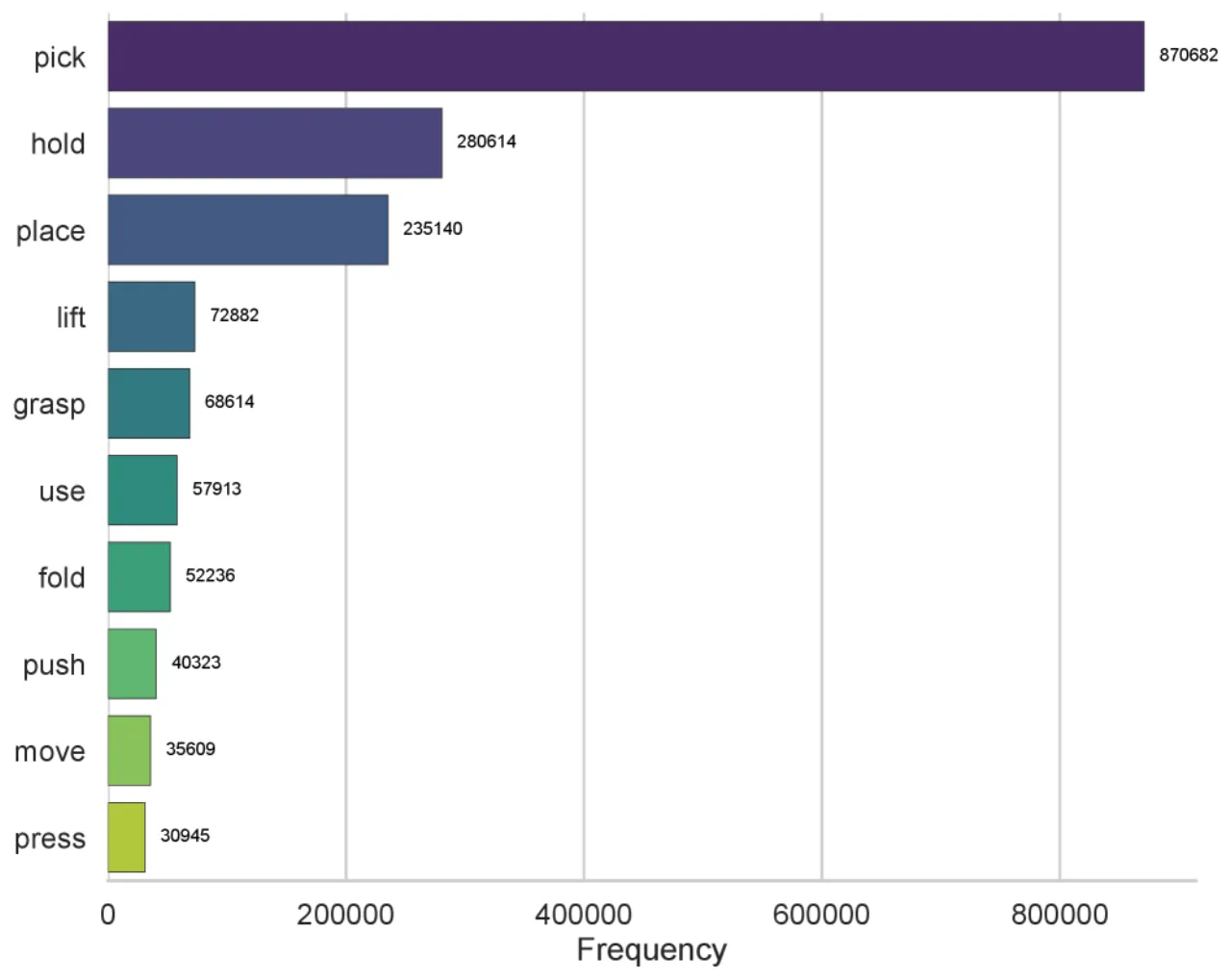
当前机器人学习数据集的任务设计缺乏系统性原则,大量工作集中在少数常见动作(如"pick and hold"),无法有效区分和衡量不同方法的真实能力。
"Do the current datasets and task designs truly advance the capabilities of robotic agents? Do evaluations on a few common tasks accurately reflect the differentiated performance of various methods proposed by different teams and evaluated on different tasks?"
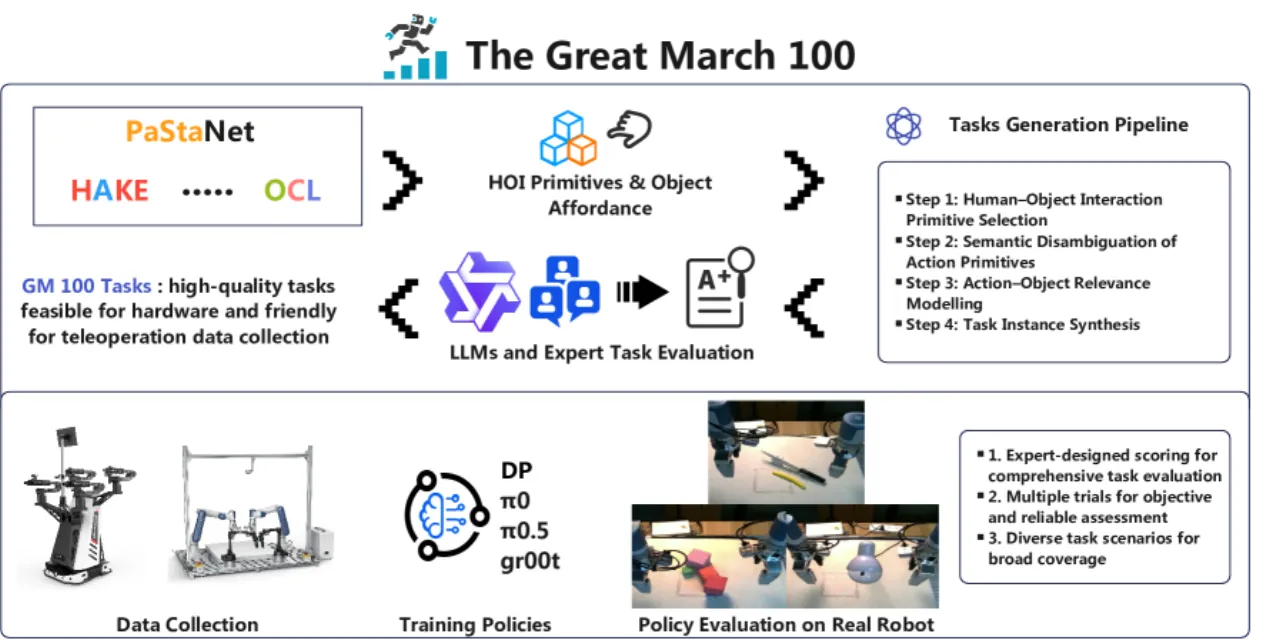
100精细设计任务数
13K+收集轨迹总数
2真实机器人平台
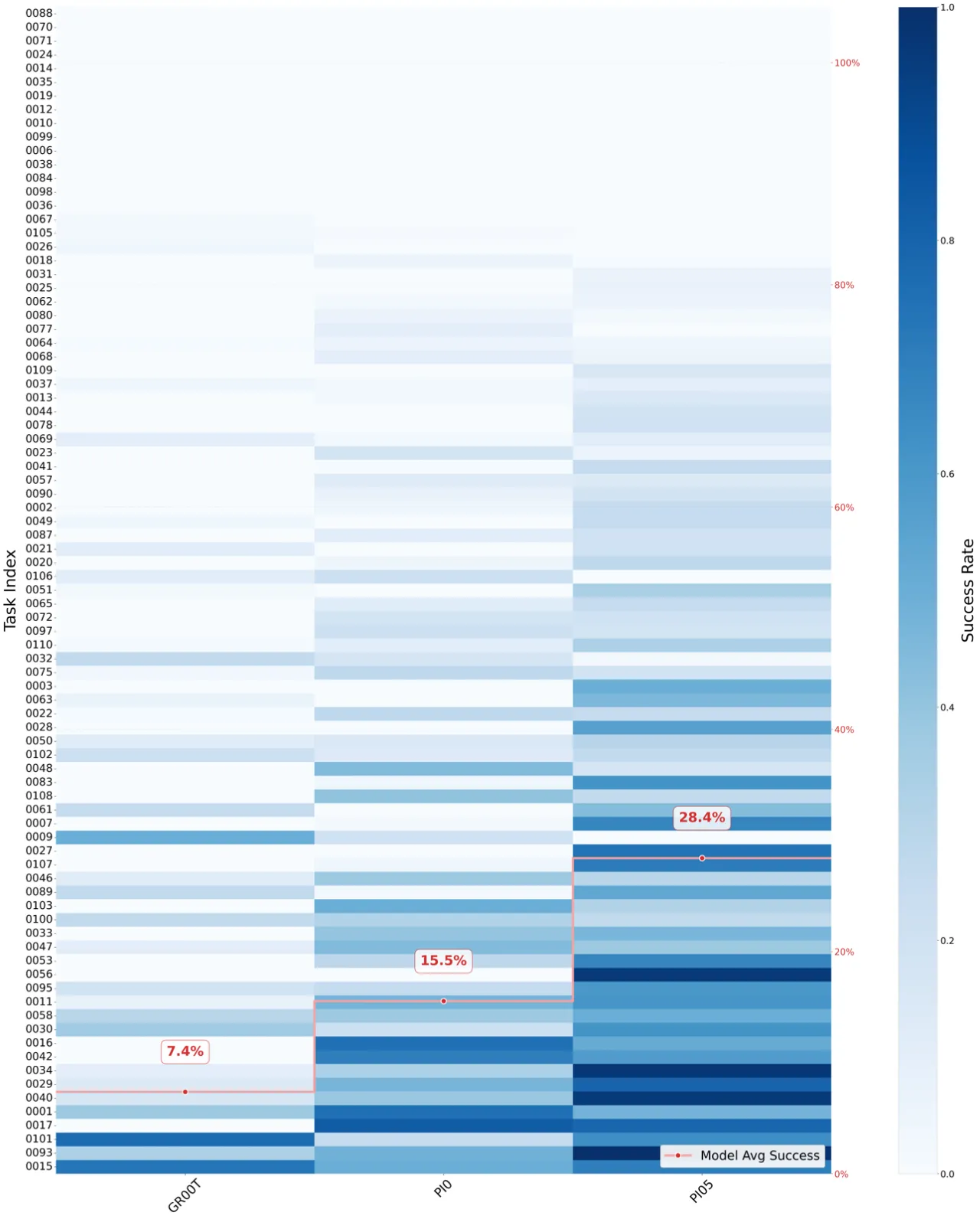
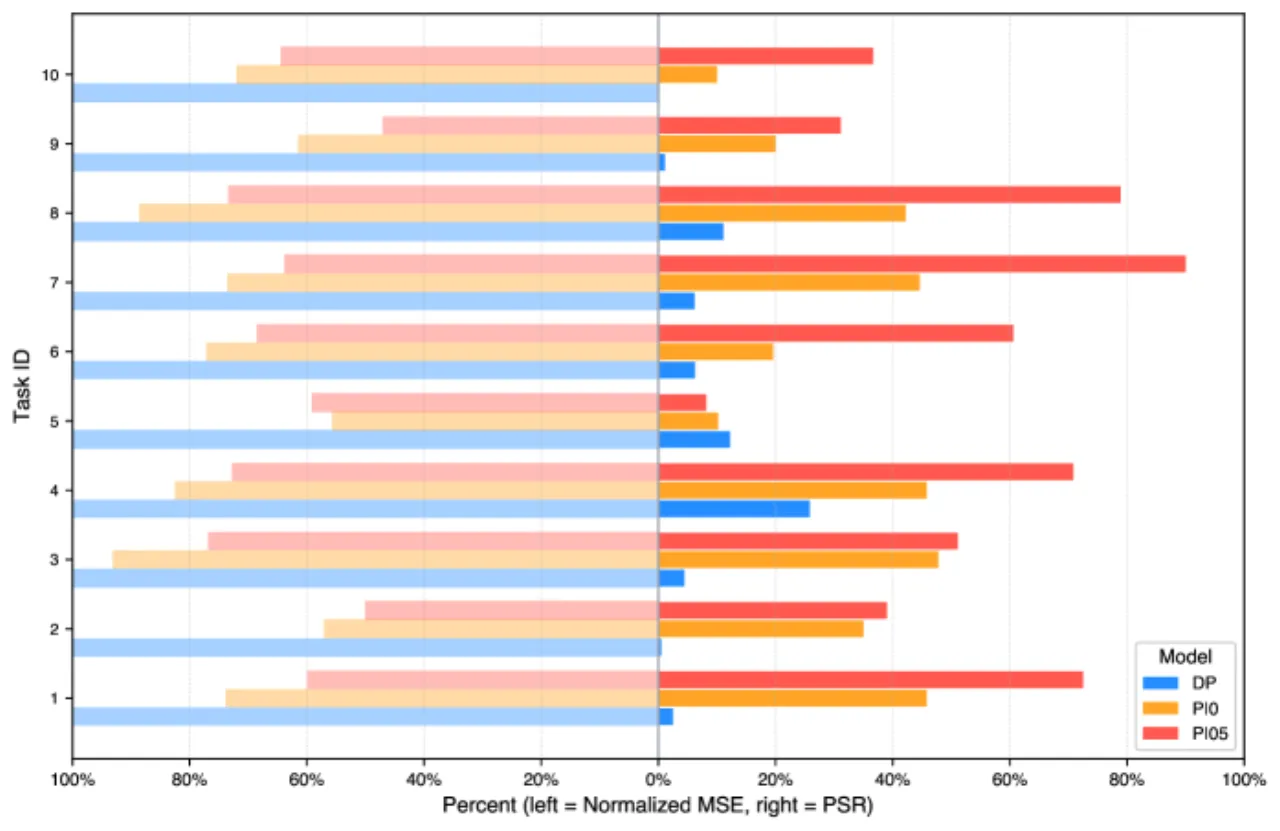
3基线 VLA 模型对比
现有数据集存在"重叠过多、设计随意"的问题——不同团队在各自不同的任务上评估自己的方法,缺乏统一的多样化测试集,难以做到横向对比。GM-100 的目标是成为机器人学习领域的"Olympics":提供标准化、多样化、且具有足够难度的任务集合,让不同方法在同一赛场上同台竞技。