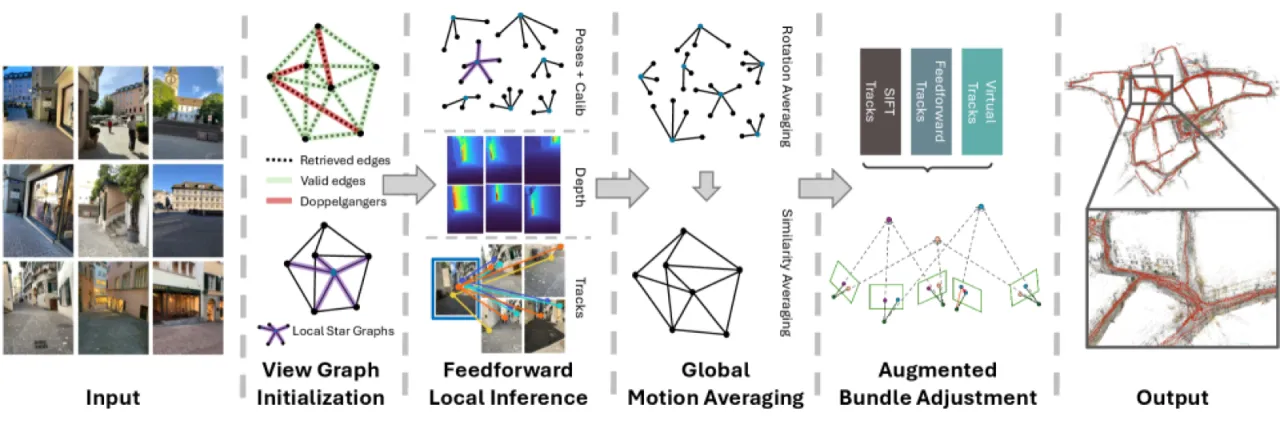
01 动机
经典 SfM(以 COLMAP 为代表)在标准重建场景表现优异,但在低纹理、有限重叠度、对称结构等场景下系统性失效。 前馈神经网络方法(如 π³)在这些困难场景中展现出惊人的鲁棒性,却在可扩展性、精度和鲁棒性上远不及经典方法。 本文提出 GlueMap,系统性地整合两类方法的互补优势。
"We systematically analyze these limitations and propose a new Structure-from-Motion pipeline by combining the respective strengths of classical and feedforward methods."
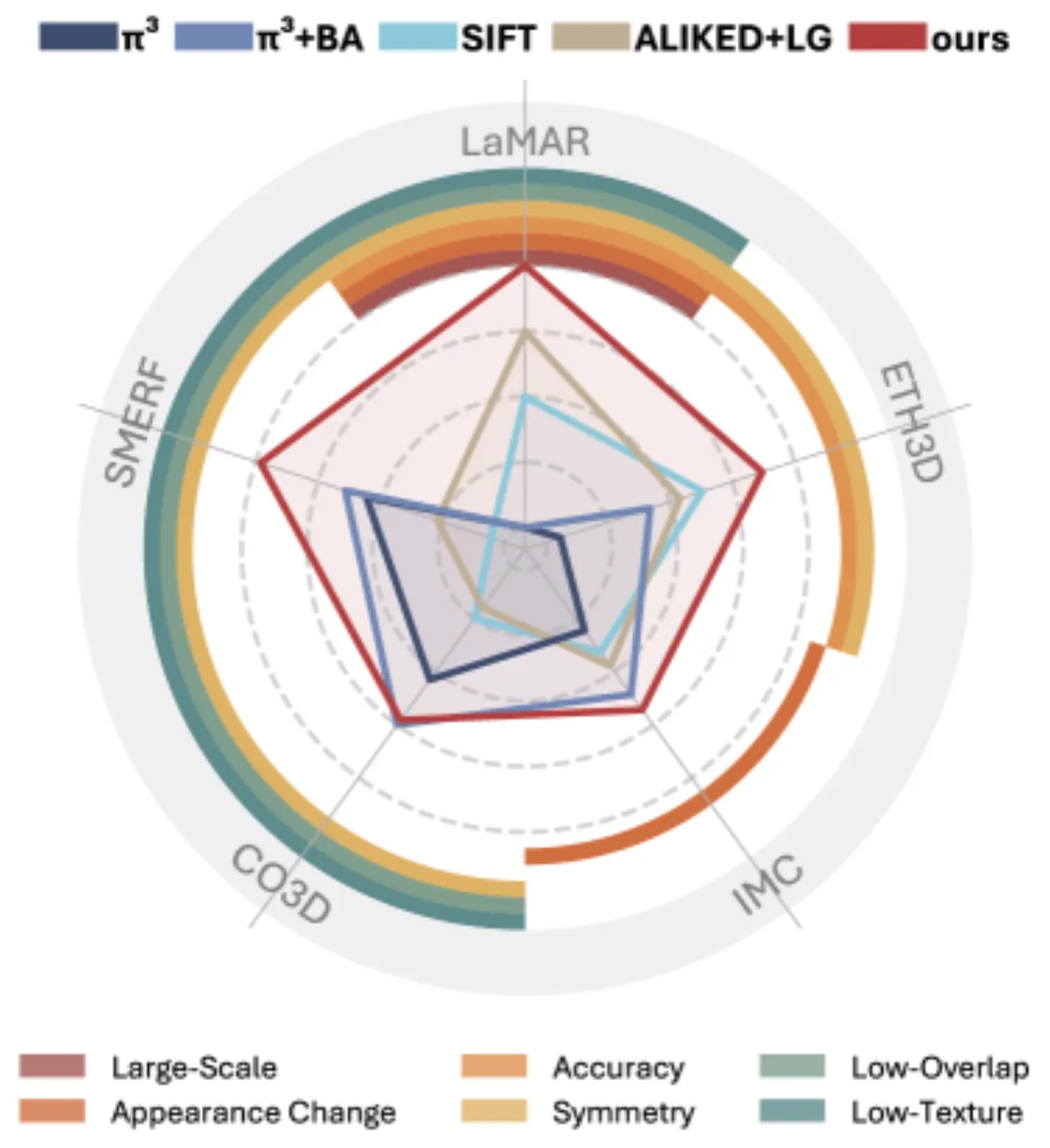
83.6ETH3D AUC@5
(ALIKED+LG: 67.4)
(ALIKED+LG: 67.4)
92.4SMERF AUC@20
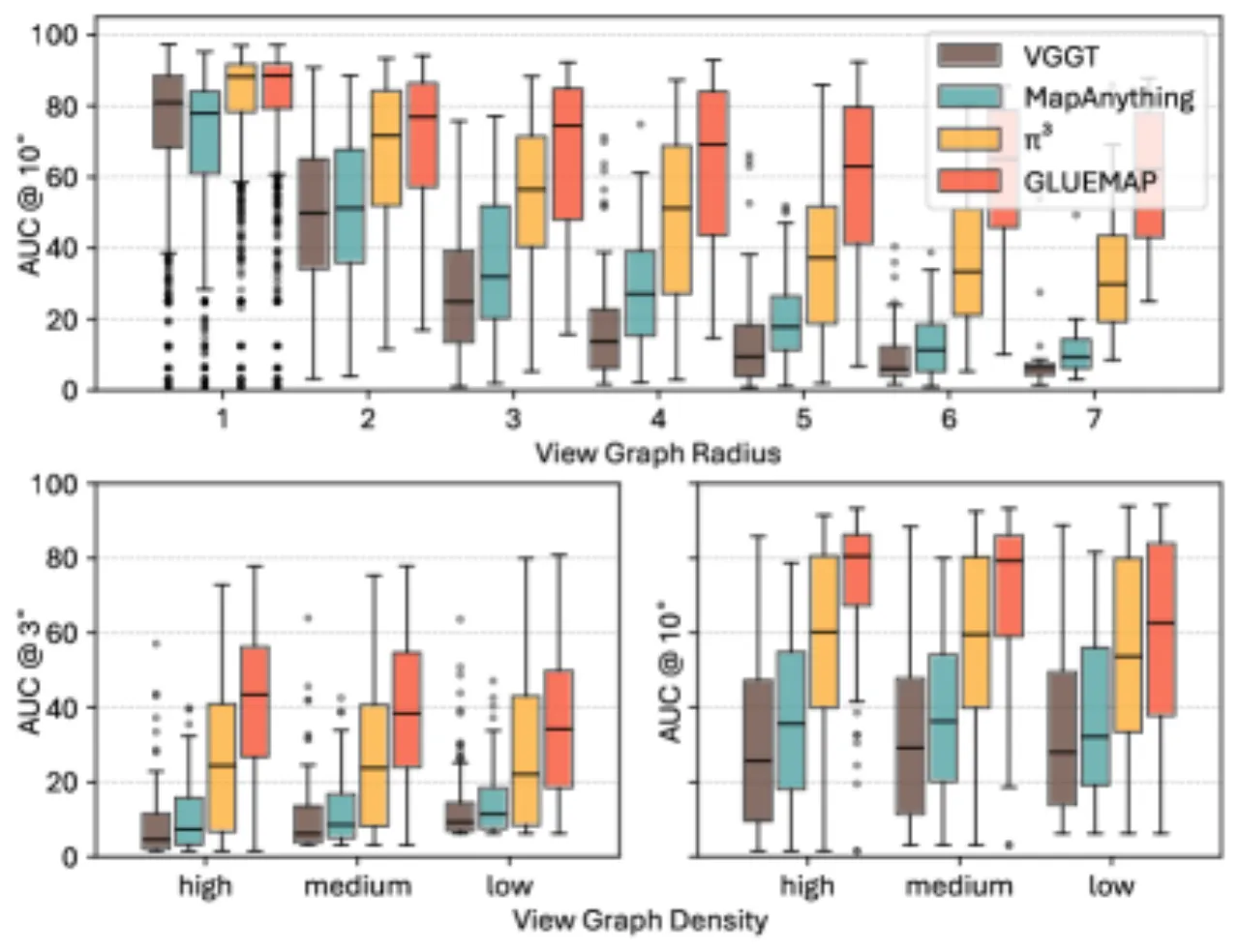
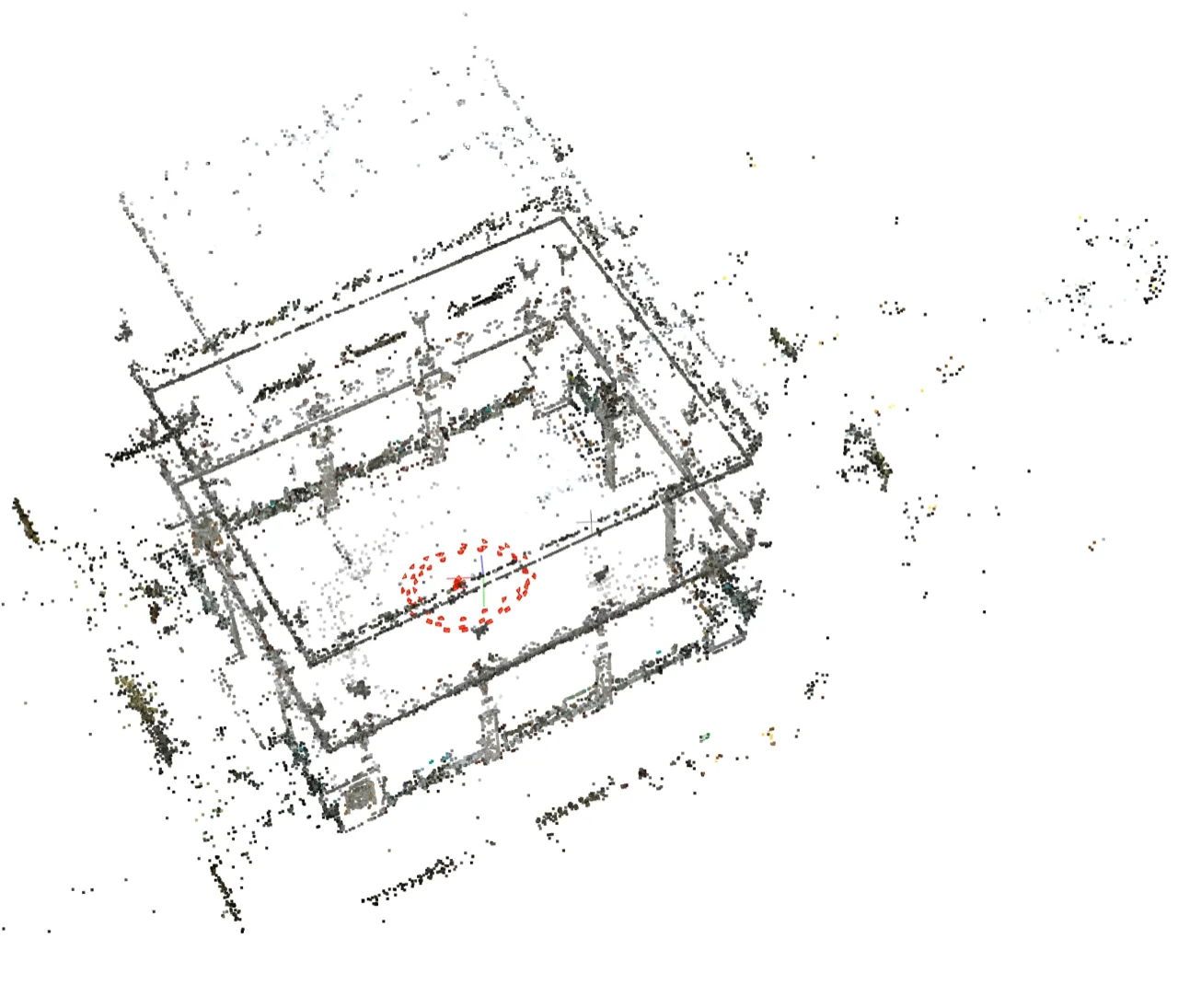
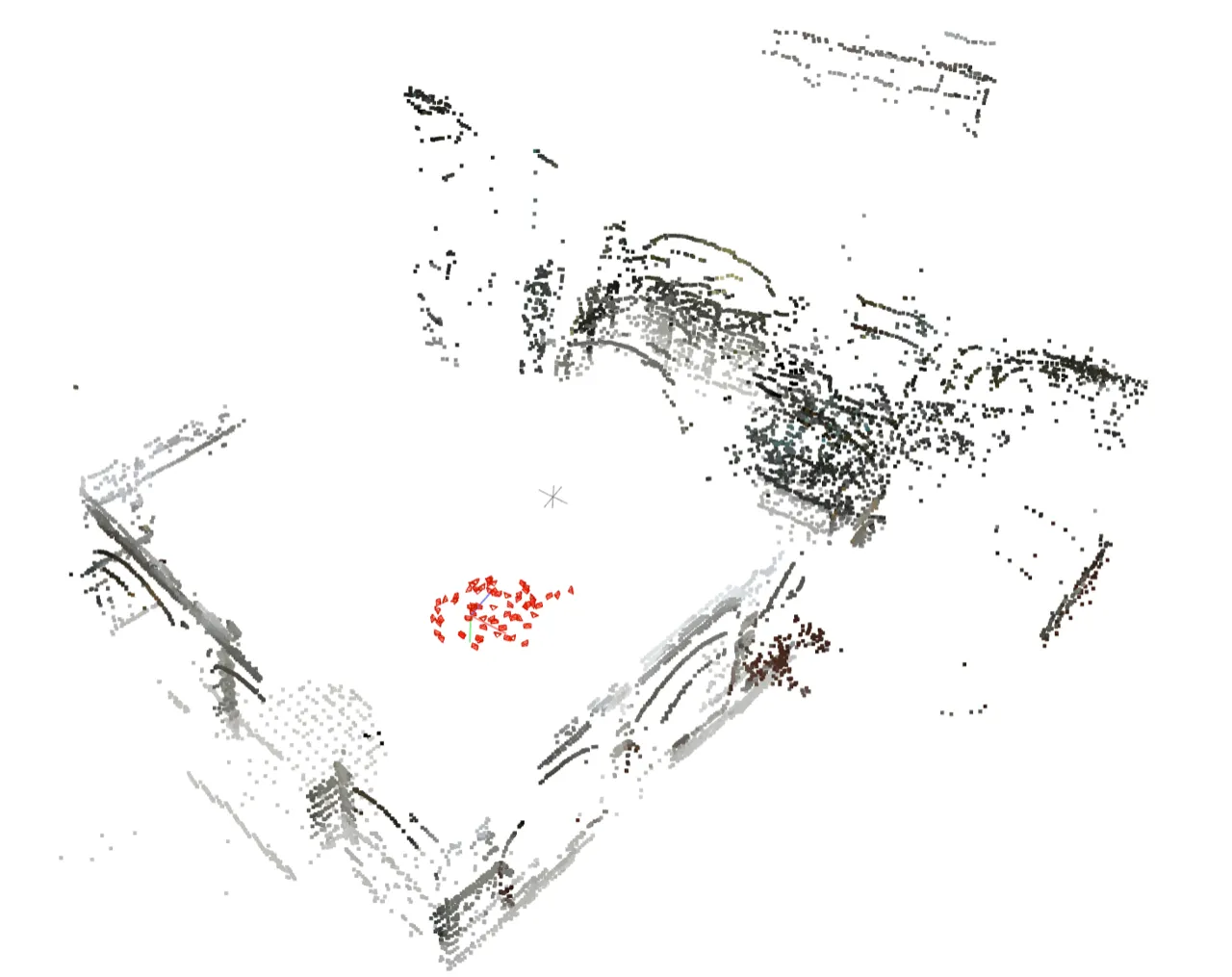
低重叠室内场景
低重叠室内场景
37.3LaMAR HGE AUC@3
(SIFT: 2.6, π³: OOM)
(SIFT: 2.6, π³: OOM)
58.7CO3Dv2 40img AUC@3
(π³: 47.1)
(π³: 47.1)