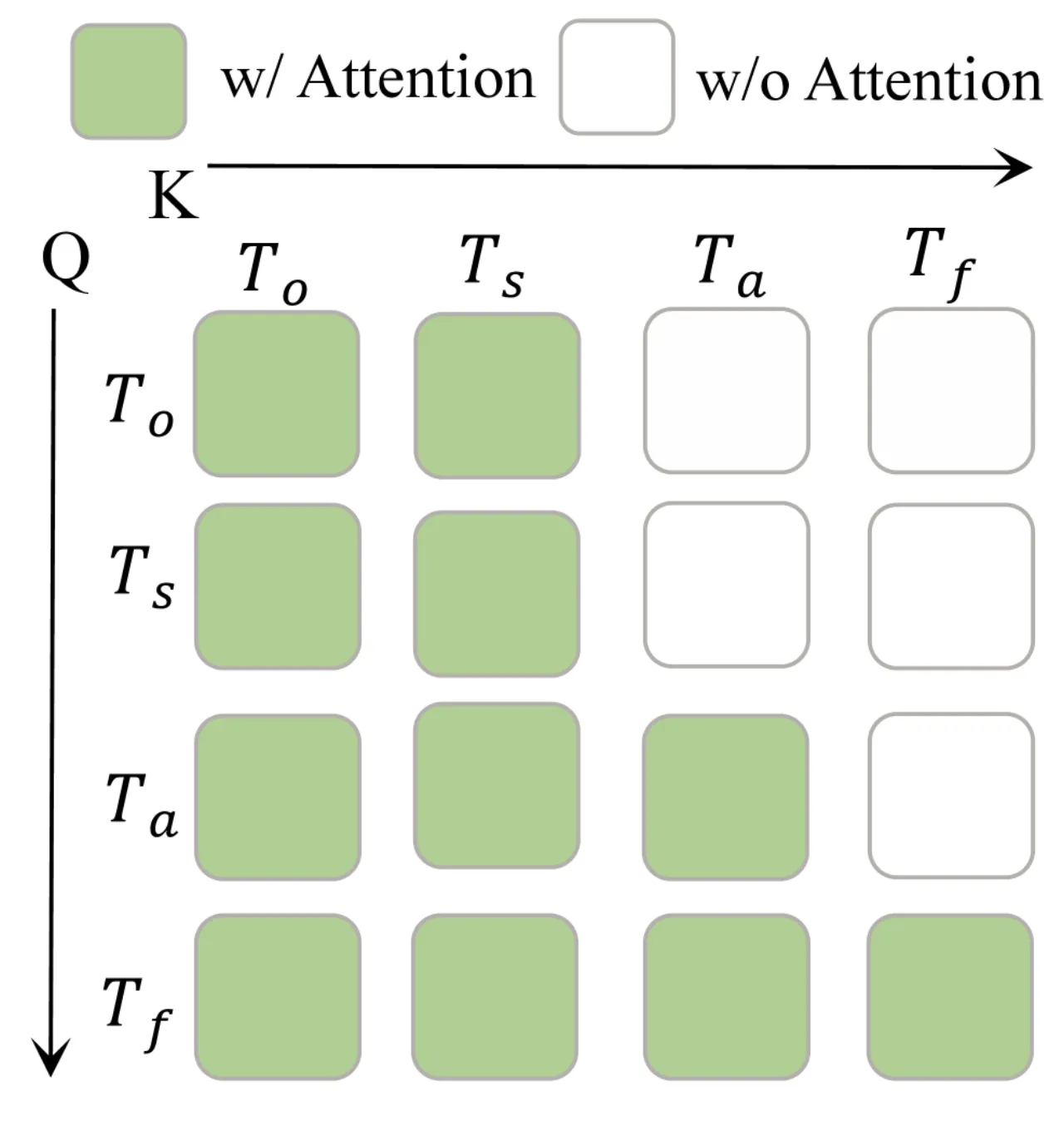
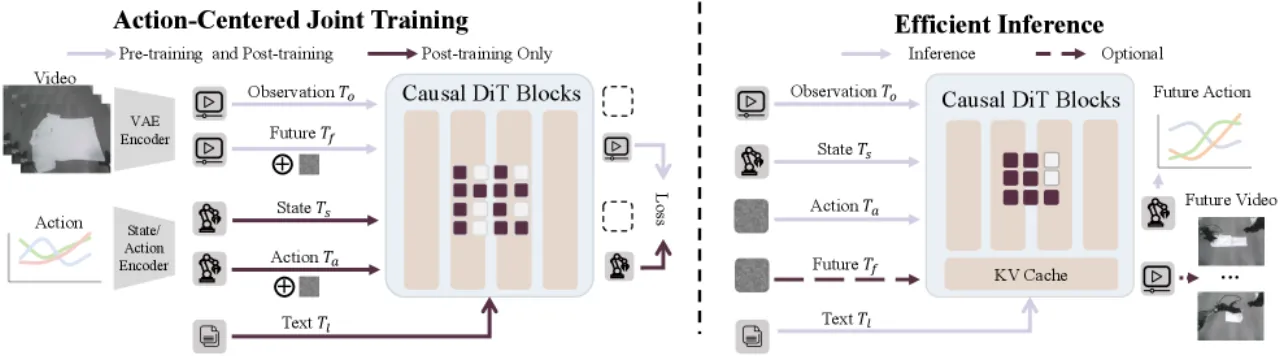
01 动机
现有世界-动作模型(World-Action Models)在推理时面临两大核心瓶颈: 一是推理开销过大——联合推断未来视觉动态与动作序列导致延迟极高; 二是表征耦合问题——动作预测质量与视频预测质量强绑定,一旦视频生成出错,动作也随之降级。 此外,基于 VLM 的 VLA 方法存在"监督稀疏"(supervision sparsity)问题:动作标签相对于高维观测过于稀疏,容易使模型将不同场景压缩为重复行为,而非学习有物理意义的动作。
"jointly reasoning over future visual dynamics and corresponding actions incurs substantial inference overhead" ——论文对当前世界-动作模型推理瓶颈的直接概括
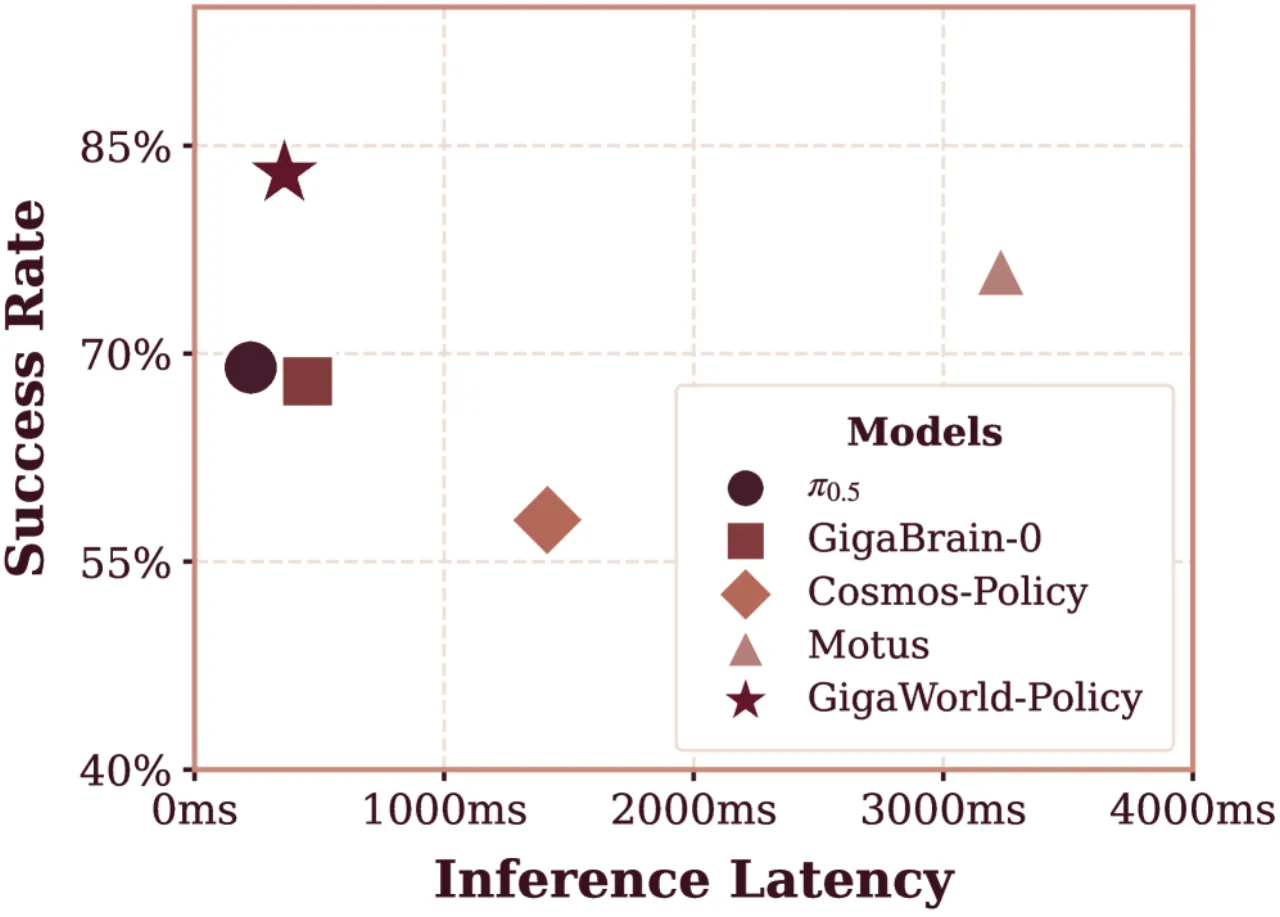
9×比 Motus 推理速度提升(360ms vs 3231ms)
0.86RoboTwin 2.0 仿真平均成功率(clean)
0.83真实机器人平均成功率(20次试验/任务)
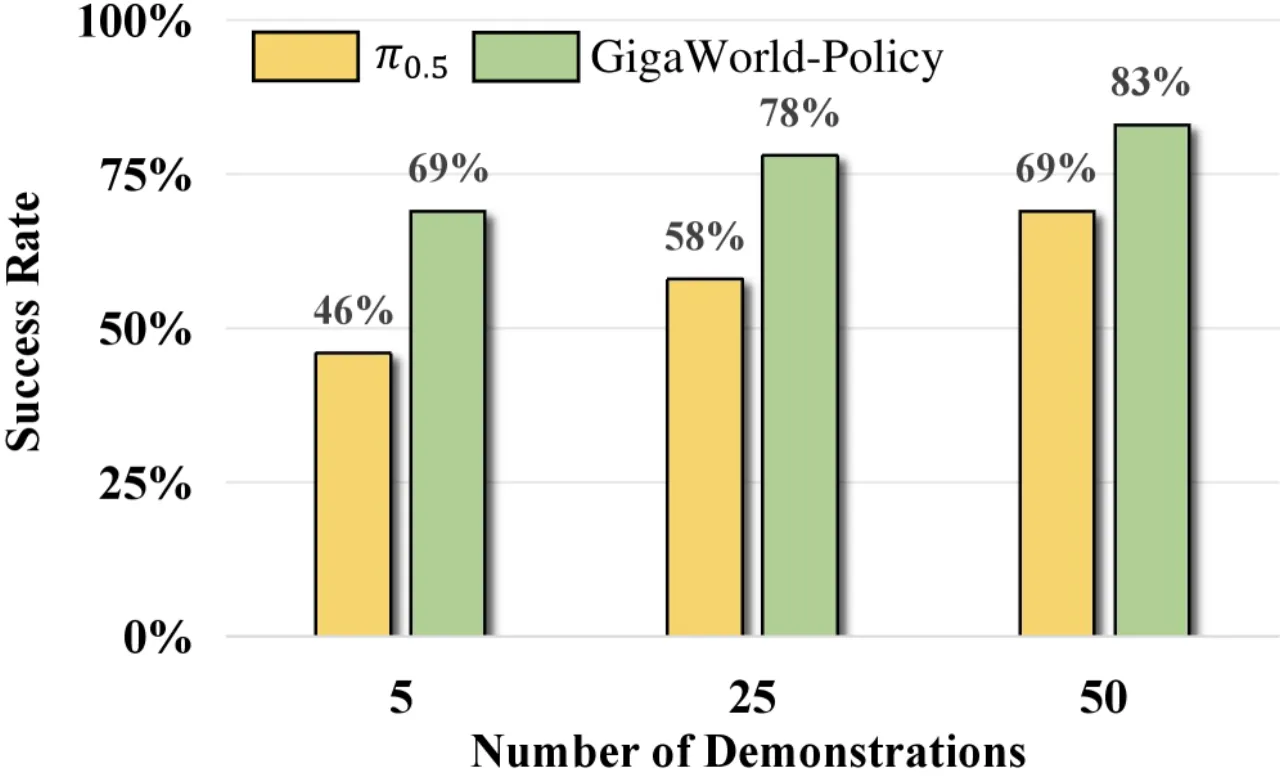
10%达到基线最优所需的训练数据量