01 动机
将大型视觉基础模型的语义特征蒸馏到辐射场(NeRF / Gaussian Splatting)中,已成为语言条件机器人操控与导航的重要基础。既有方法主要使用 CLIP、DINOv2 等纯视觉特征,而近期提出的 VGGT(Visual Geometry Grounded Transformer)则通过 3D 重建任务目标训练,获得了几何感知语义特征。直觉上,视觉-几何特征对位姿估计等空间任务应更有优势——但事实真是如此吗?
"Do geometry-grounded semantic features offer an edge in distilled fields? … Surprisingly, we find that the pose estimation accuracy decreases with geometry-grounded features."

9个测试场景,跨 3 个基准数据集
3个核心研究问题,涵盖关键机器人应用
SPINE首个无需初始猜测的语义辐射场反演框架
三个核心问题
Q1:视觉-几何语义特征是否含有更高保真度的空间内容?
是 VGGT 特征包含更精细的结构细节,例如更清晰的边缘、更准确的子部件分解,但对象级语义的一致性弱于 DINO 系列。
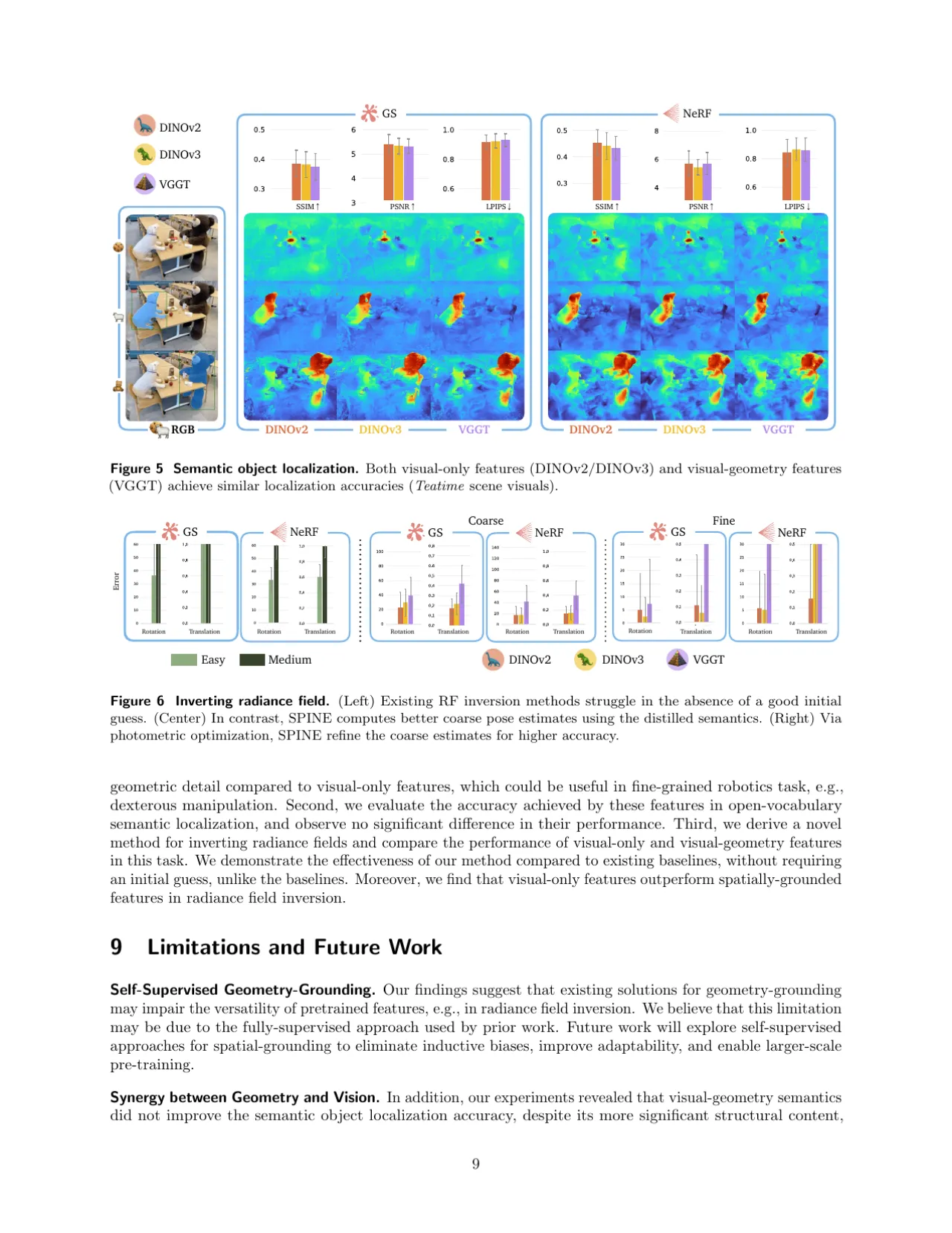
Q2:几何感知是否能提升语义目标定位精度?
否 在 GS 与 NeRF 上,视觉-几何特征与纯视觉特征的定位精度无显著差异;VGGT 甚至出现轻微性能退化。
Q3:视觉-几何特征能否实现更高精度的辐射场反演?
否(出人意料) DINOv2 在粗位姿估计阶段取得最低旋转误差与平移误差;VGGT 反演精度最差,尽管其几何内容最丰富。