Understanding the Impact of Geometric Foundation Models on Vision-Language-Action Models
Yurou Yang, Muyuan Lin, Roberto Martin-Martin, Martin Labrie, Shreekant Gayaka, Cheng-Hao Kuo, Luca Carlone · Amazon Personal Robotics Group · UT Austin · MIT
标准 VLA(GR00T-N1.5)的深度预测 RMSE 约为 VGGT 的两倍,δ₁ 分数也明显更低,
证明 VLA 确实存在显著的"几何差距"。论文进一步发现:
"深度信息在视觉编码器之后便已丢失(the depth information is already lost after the vision encoder)"。
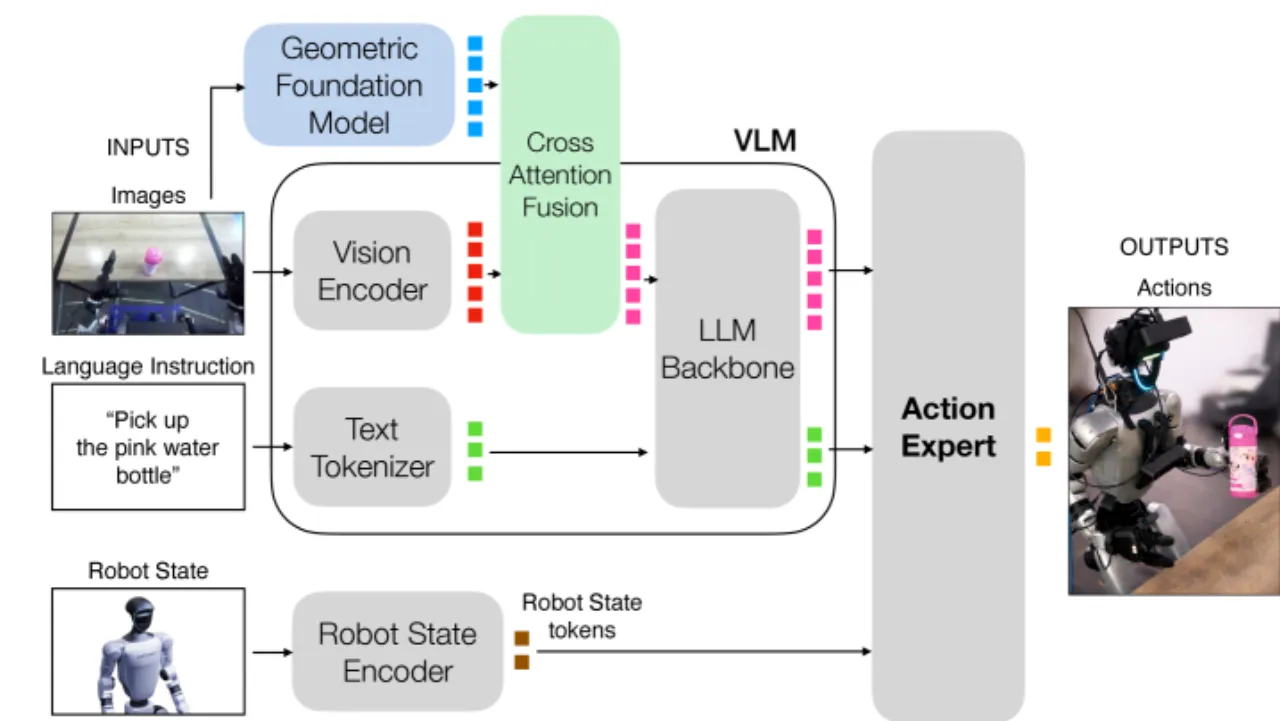
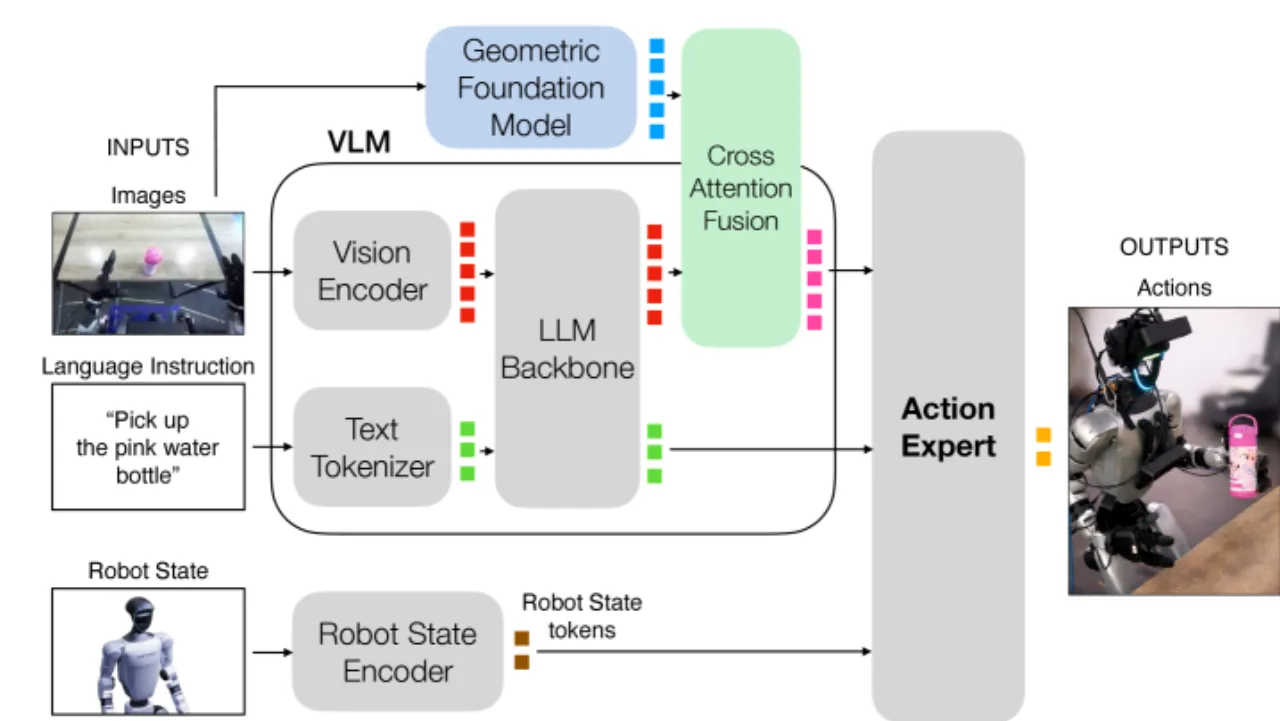
Early Fusion 与 Late Fusion 使用统一的融合实现:标准缩放点积交叉注意力,
加上一个注意力门控(attention gating)残差项:
X̃ = X + A ⊙ Z,门控矩阵 A 初始化接近零,
避免融合信号在训练初期使动作专家"偏离分布"。
LoRA rank = 8,仅训练交叉注意力层参数。
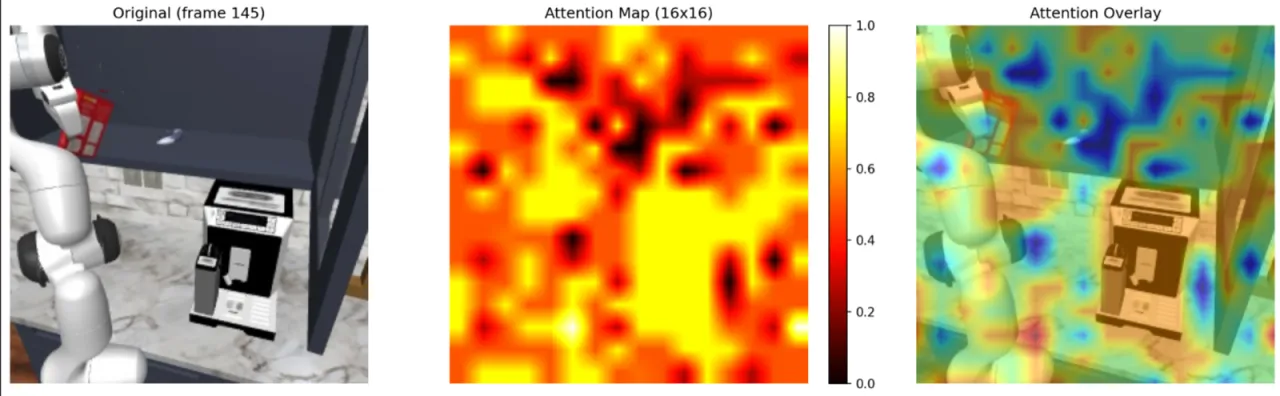
融合模块注意力掩码: Early Fusion(左)与 Late Fusion(右)中,
VLA token 对 VGGT 几何 token 的注意力权重可视化,
展示了跨模态几何信息的传递模式。
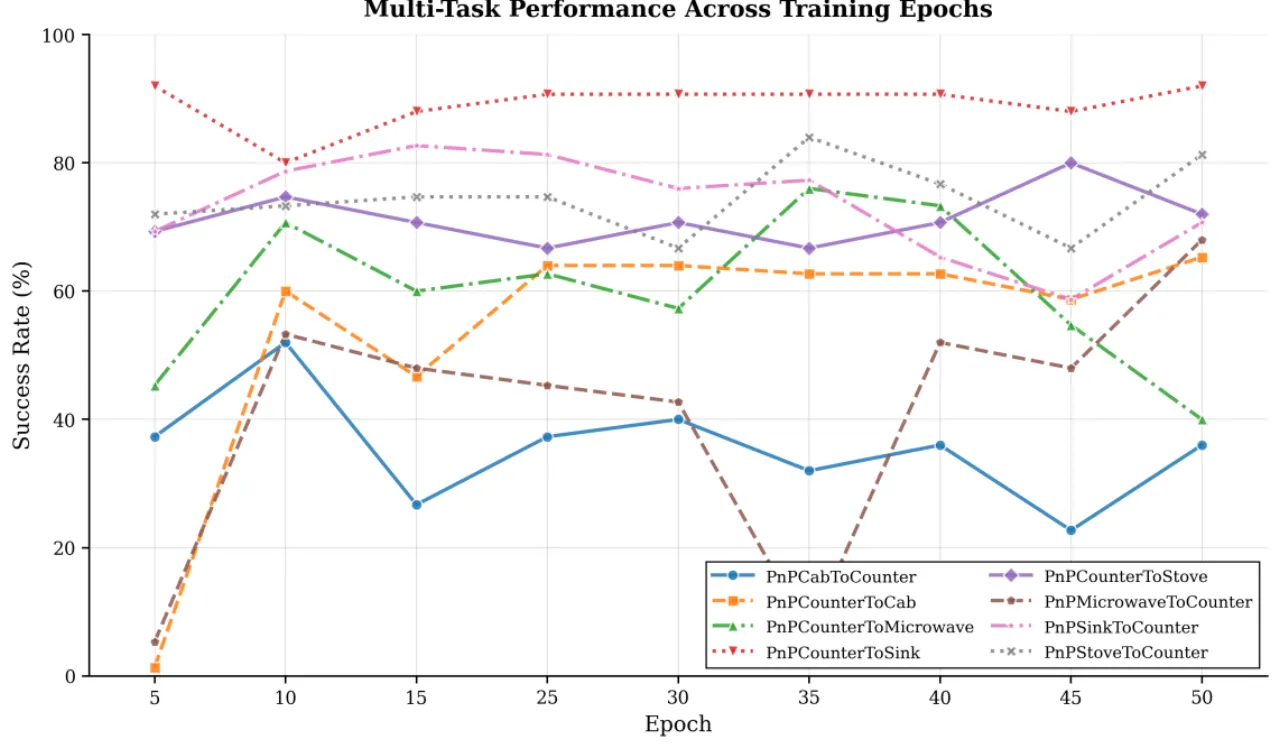
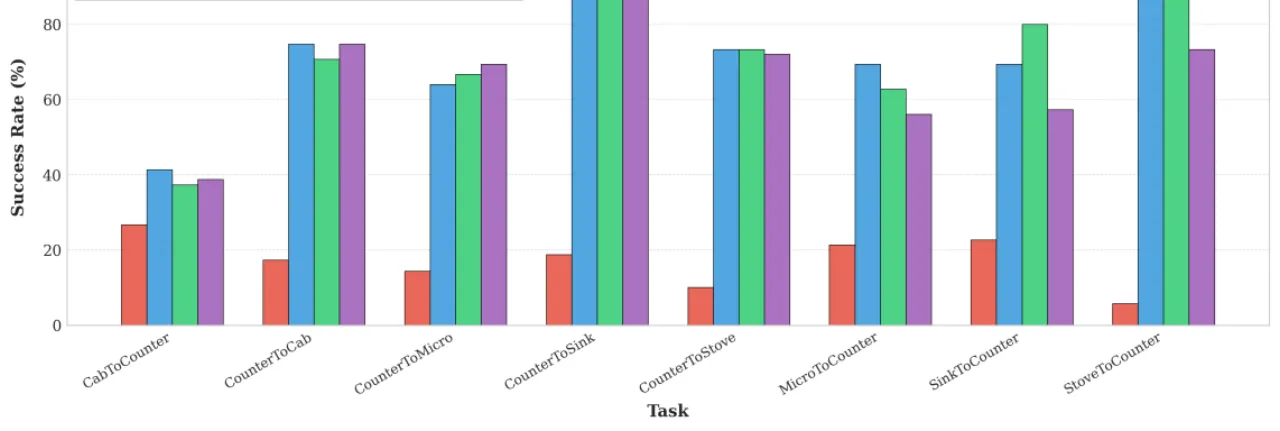
"部分仿真基准已趋饱和(some of the simulation benchmarks are saturated),
因此限制了改进空间(limiting the margin of improvement)。"
例如 RoboCasa 中某些任务基线成功率已达 88–93%,几何信息几乎无法带来额外提升。