01 动机
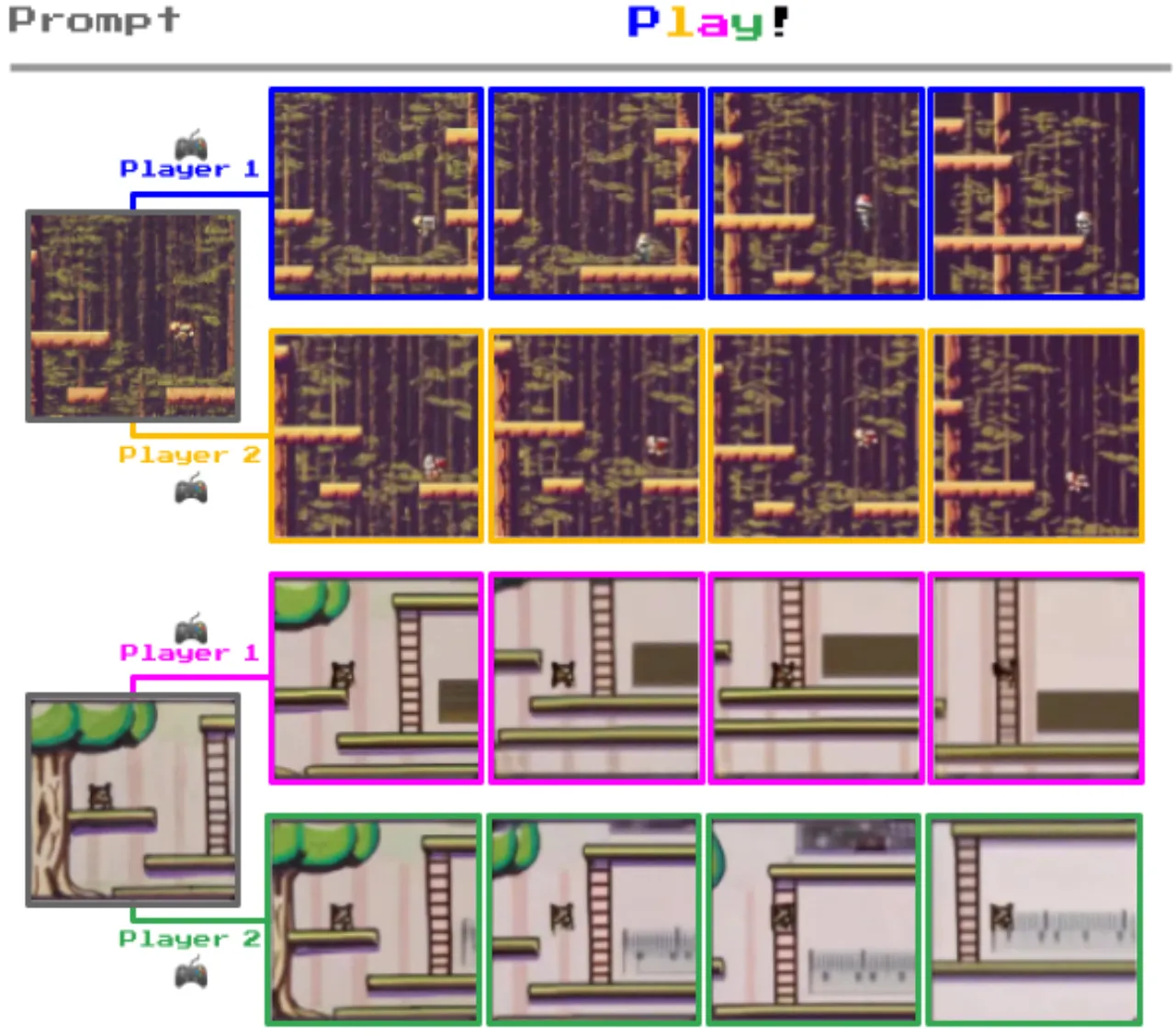
生成式 AI 已能生成高质量的文本、图像和视频,但真正可交互的虚拟环境仍高度依赖人工设计或带标注的数据。能否从海量无标注的网络视频中,自动学习出一个可供智能体"玩耍"的交互世界?
"We introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos."
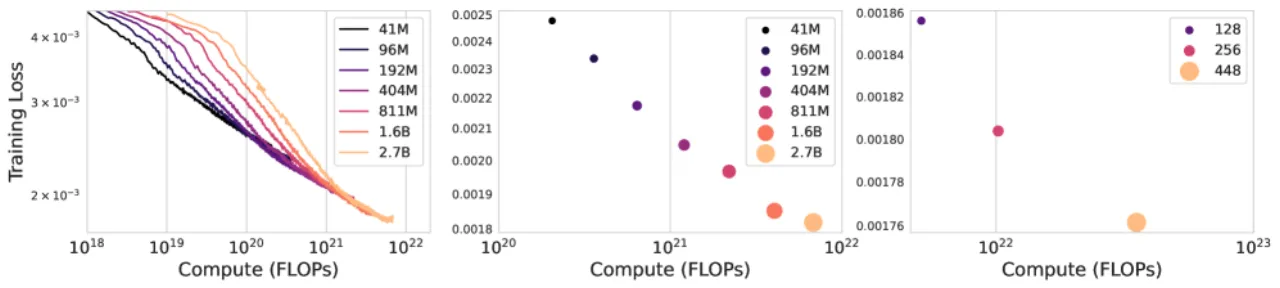
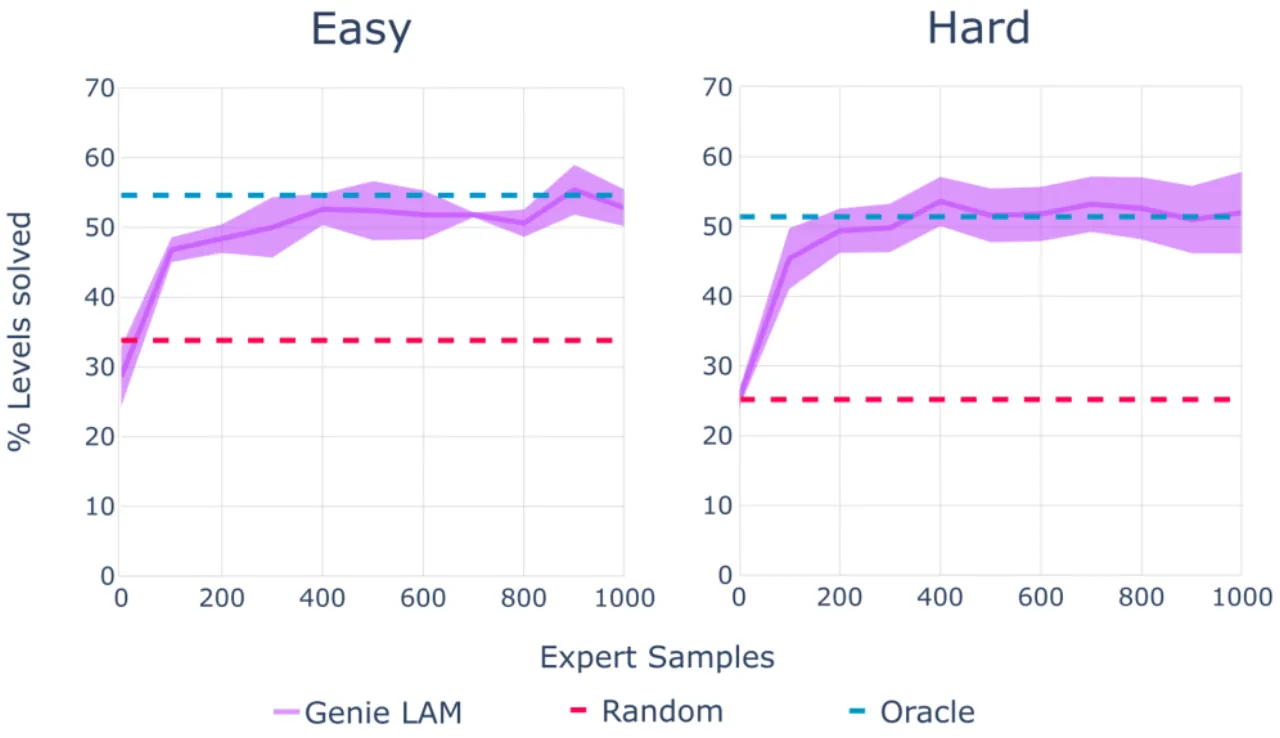
11B总参数量
6.8M训练视频(30k 小时,2D 游戏)
8离散潜在动作数(无人工标注)
~1 FPS当前推理速度
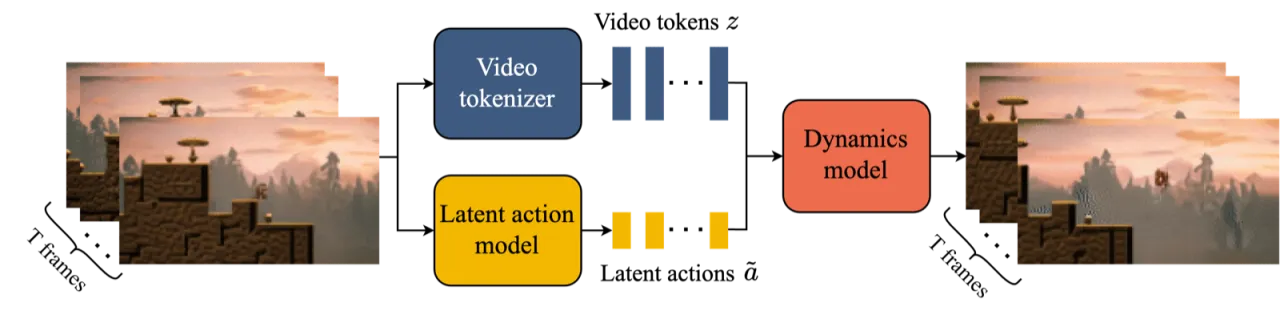
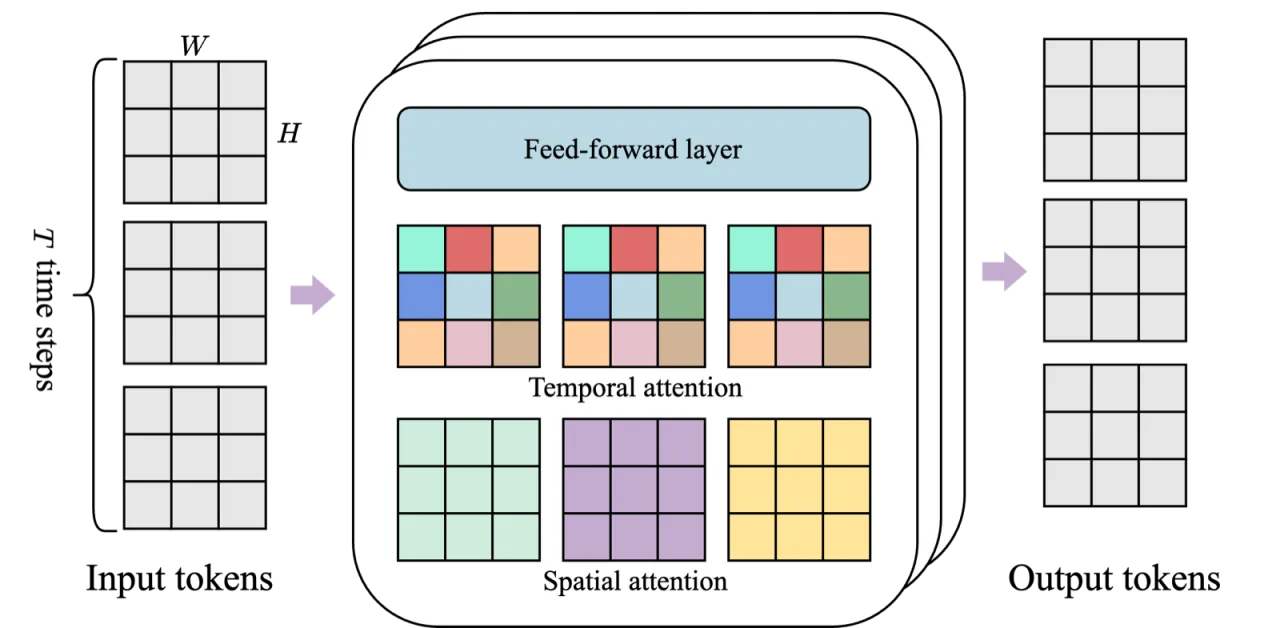
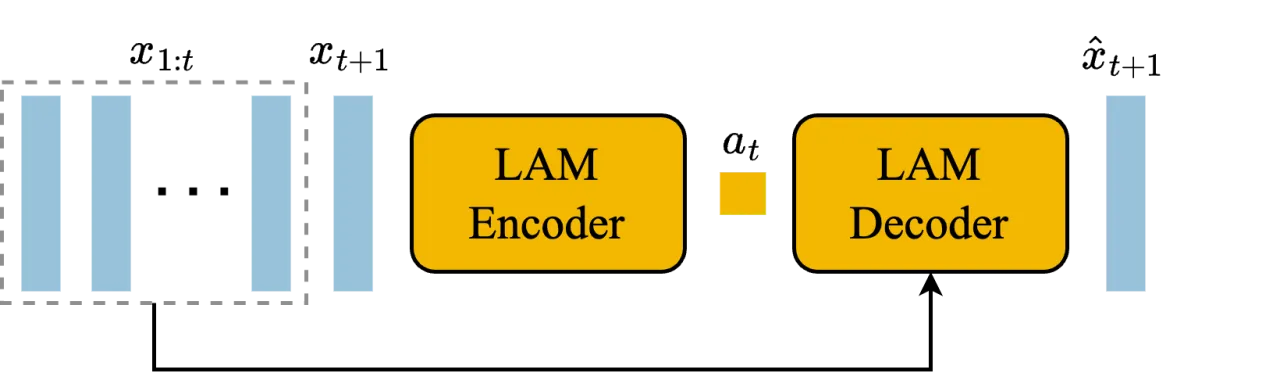
现有方法要么依赖真实动作标注(如环境模拟器日志),要么只能生成被动视频,无法响应用户交互。Genie 的核心洞见在于:动作信息隐含在视频帧的时序变化之中——只要能从相邻帧中推断出潜在动作,便可在完全无标注的条件下学习一个可控的动态模型。