01 动机
通用机器人需要在开放世界环境中同时做到广泛泛化与高精度动作执行——这一组合对现有 Vision-Language-Action(VLA)模型而言仍是重大挑战。
"models optimized for strong reasoning capabilities tend to exhibit reduced action precision, while those achieving high-fidelity execution often demonstrate limited generalization."
具体而言,现有方案存在三层缺陷:
- 语义泛化不足:大型 VLM 提供语言理解,但具身推理(空间感知、任务规划、错误恢复)仍薄弱,导致机器人在分布外场景下行为脆弱。
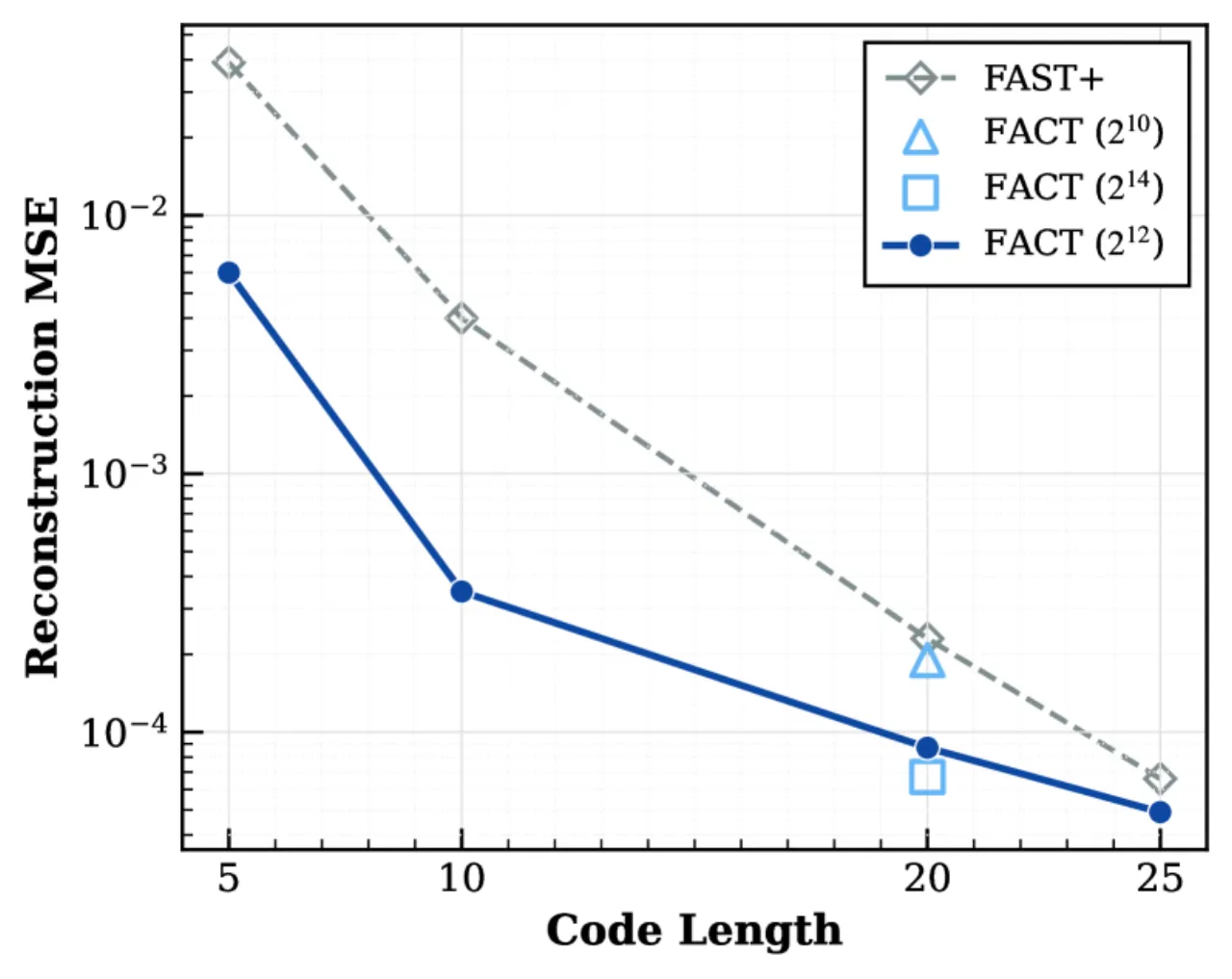
- 动作精度损失:现有离散动作分词器(均匀分箱或 VQ-VAE)在量化过程中丢失轨迹精细结构,重建误差较大。
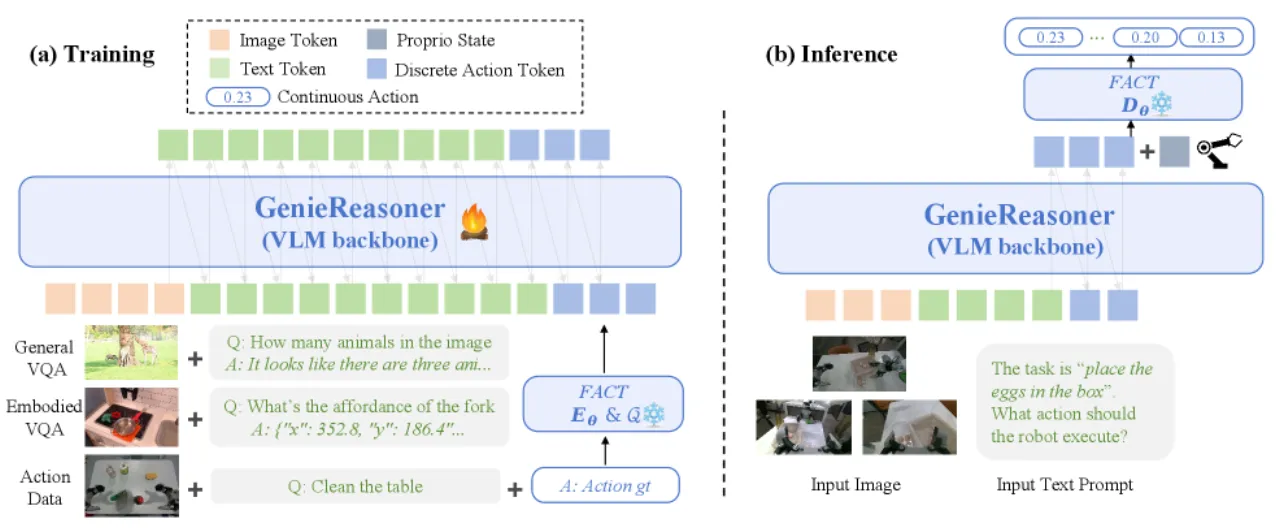
- 优化冲突:将连续动作头直接附加到 VLM 主干时,推理目标与动作预测目标相互干扰,难以联合优化。
为定量解耦这一瓶颈,作者构建了 ERIQ(Embodied Reasoning Intelligence Quotient)—— 一个包含 6,052 条具身问答对的大规模基准,跨四个推理维度评测 VLM, 并证明具身推理能力与端到端 VLA 泛化性能之间存在显著正相关。
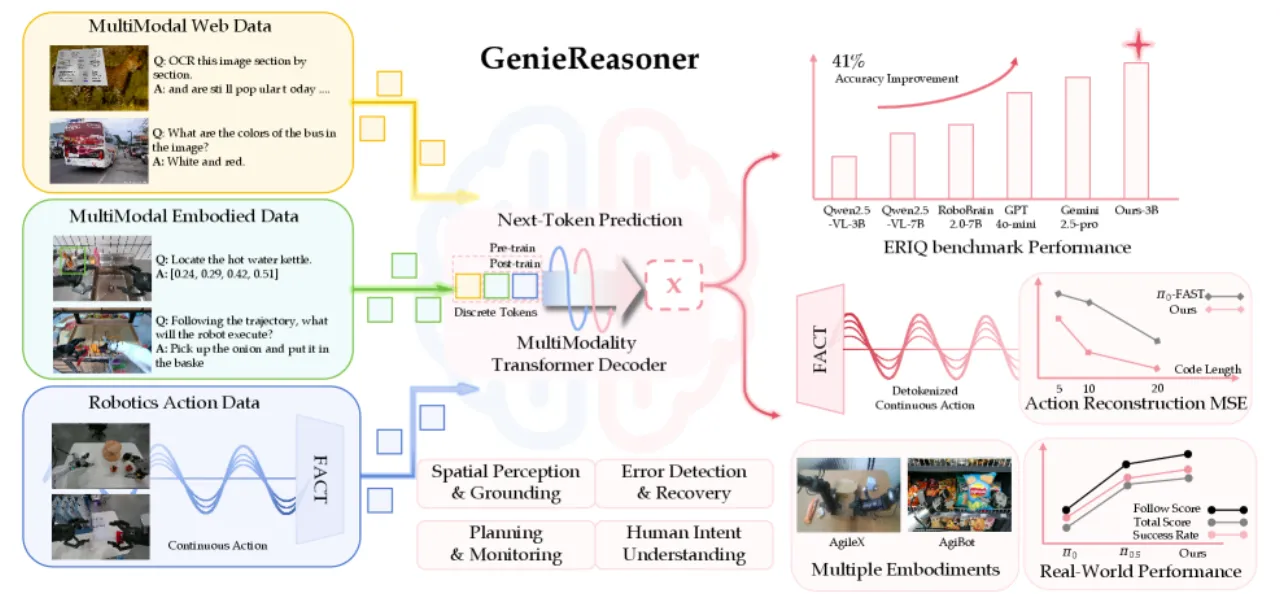
6,052ERIQ 问答对总量(四维度)
82.72%GenieReasoner-3B 在 ERIQ 上的平均准确率
58.64%基线 Qwen2.5-VL-3B 在 ERIQ 上的平均准确率
10×FACT 轨迹重建误差低于 FAST+ 的幅度(相同码长)