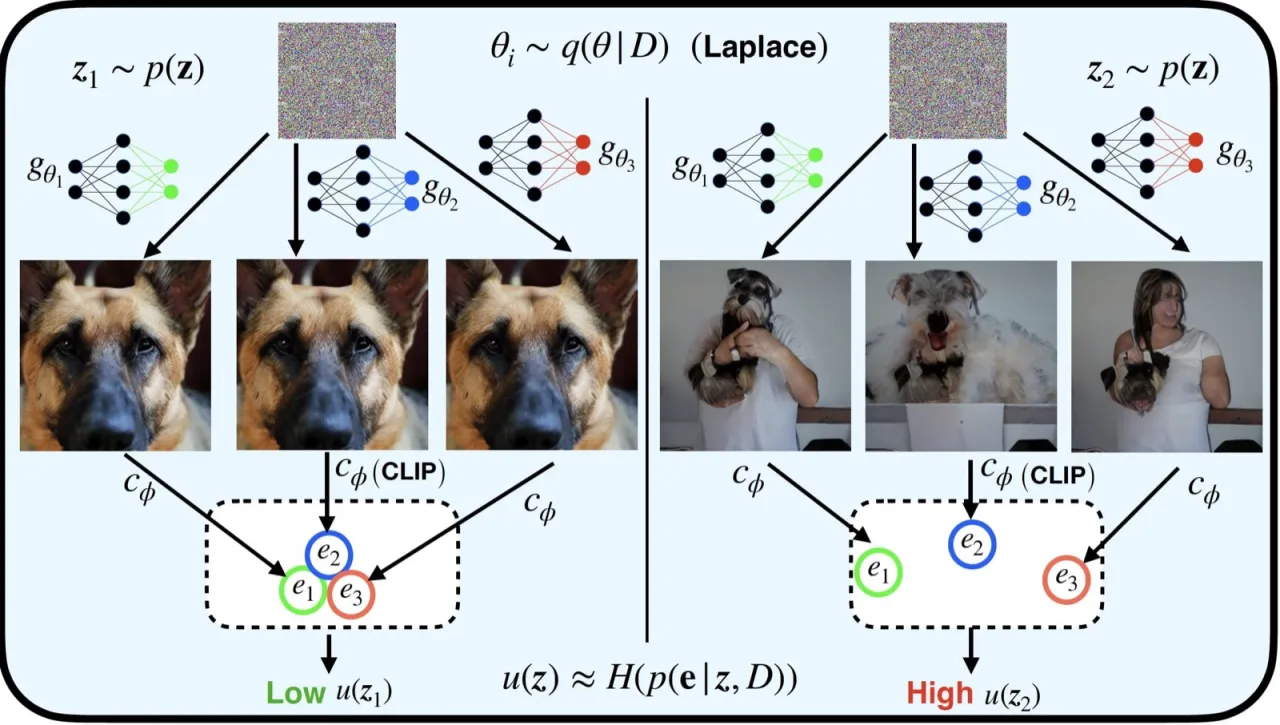
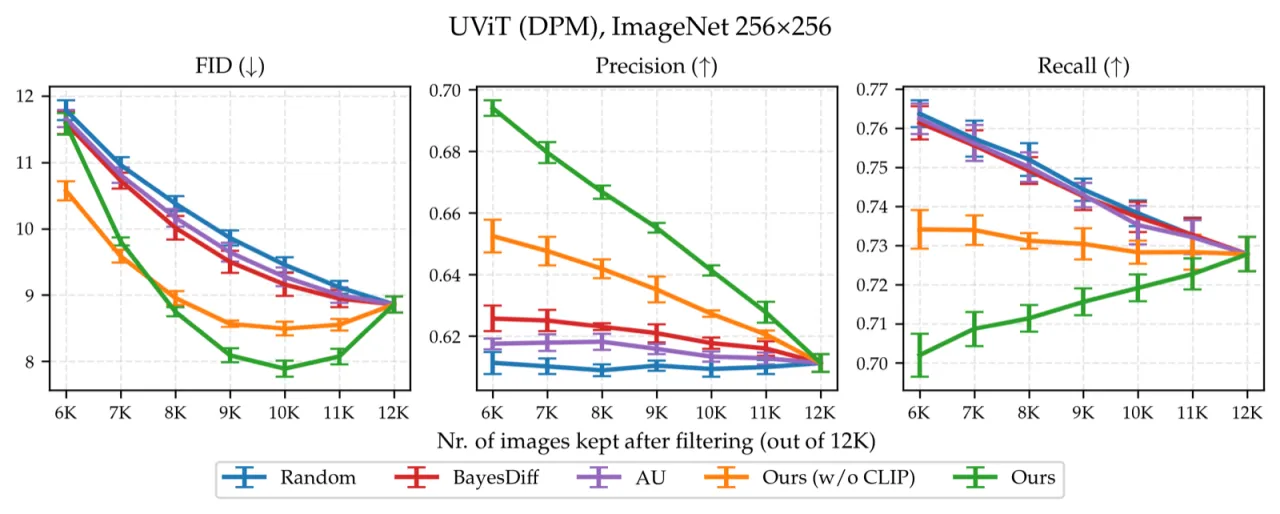
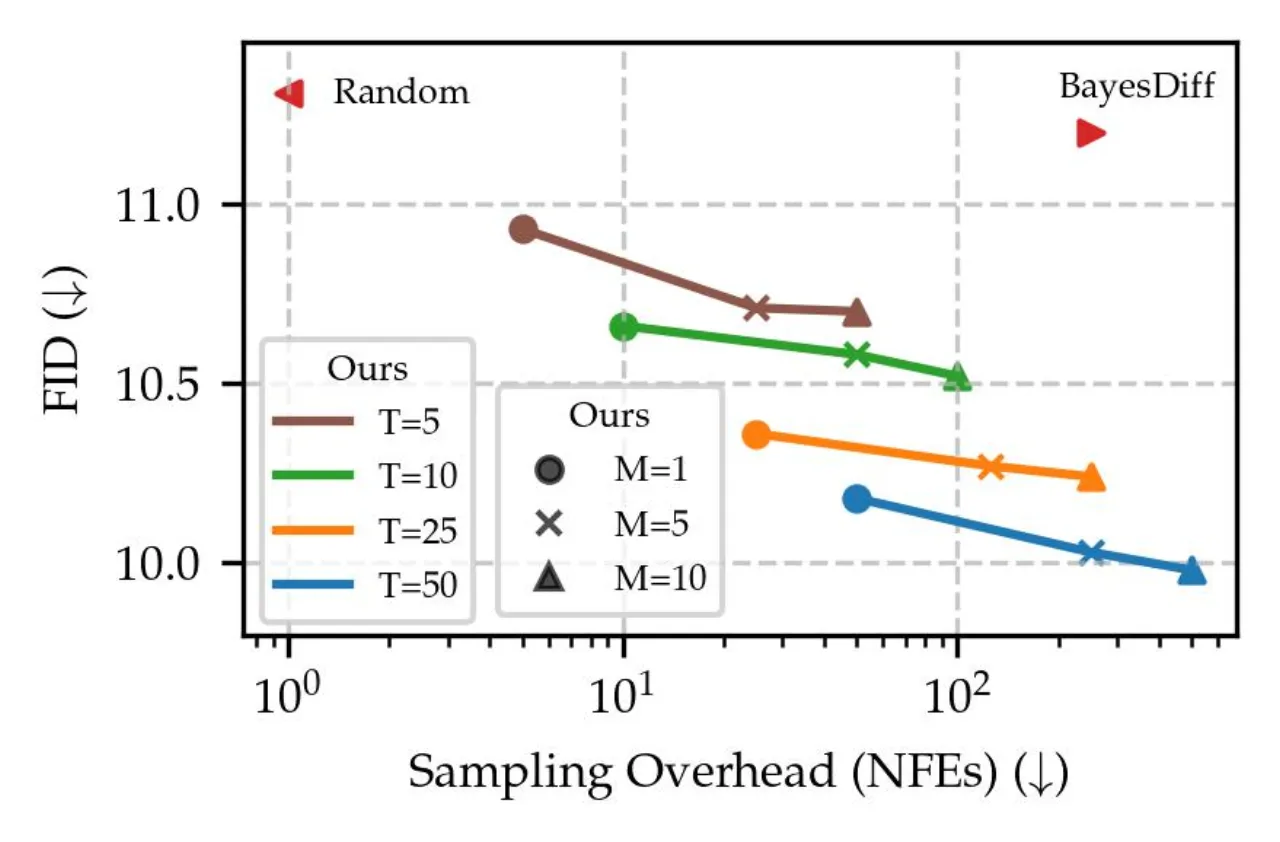
02 方法核心思路:把分类任务中"预测不确定性"(predictive uncertainty)的概念迁移到生成模型——用后验预测分布的方差来衡量每个样本的可靠程度,并借助 last-layer Laplace approximation 和语义似然使之在大型模型上高效可行。
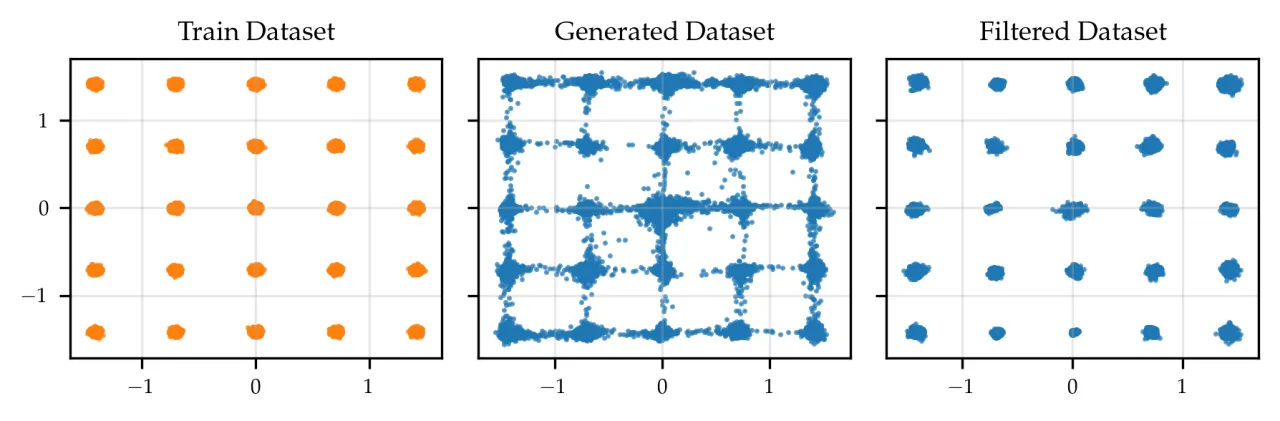
图2:二维高斯玩具示例。训练 ensemble (M=5) 后,过滤掉 50% 高不确定性样本,有效去除了两个模式之间的"幻觉"样本,分布质量大幅提升。
生成不确定性定义
对于给定的隐变量 z,生成不确定性定义为后验预测分布的变分度(variability):u(z) := V(p(x | z, D))
Last-Layer Laplace Approximation(可扩展贝叶斯推断)
对超过 1 亿参数的扩散模型直接做完整贝叶斯推断计算上不可行。本文只在模型最后一层施加 Laplace 近似,将参数后验近似为高斯分布:q(θ | D) = N(θ | θ̂, Σ),其中 Σ = (∇²_θ L(θ; D)|_θ̂)⁻¹
语义似然(Semantic Likelihood)
像素空间的似然在高维情况下失效(维度诅咒)。本文引入基于预训练编码器(如 CLIP)的语义似然:p(x | g_θ(z); φ) = N(e(x) | c_φ(g_θ(z)), σ²I)