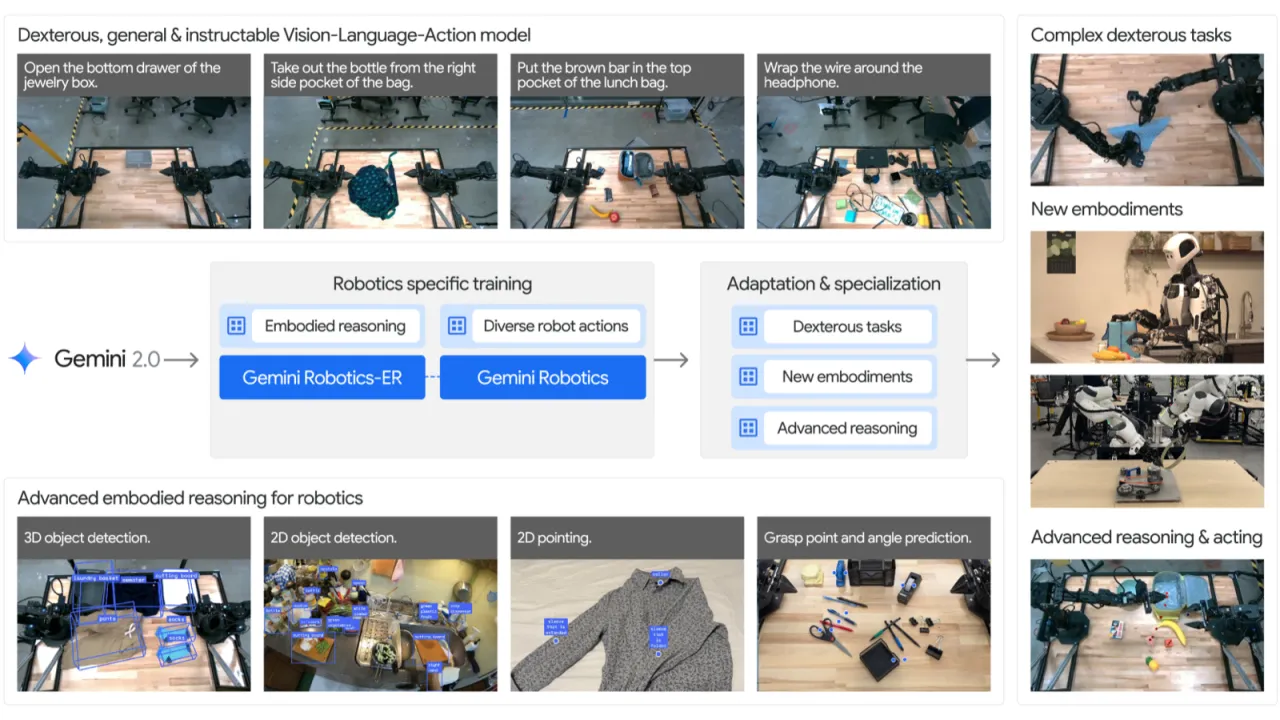
"We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots to execute complex manipulation tasks while remaining robust to object variations, environmental changes, and natural language variations."
Gemini Robotics-ER 在 3D Detection 上达到 48.3 AP@15,超越专项化模型。
04 局限性
说明:以下局限性来源于论文正文的明确陈述(stated)。
零样本灵巧操作成功率有限
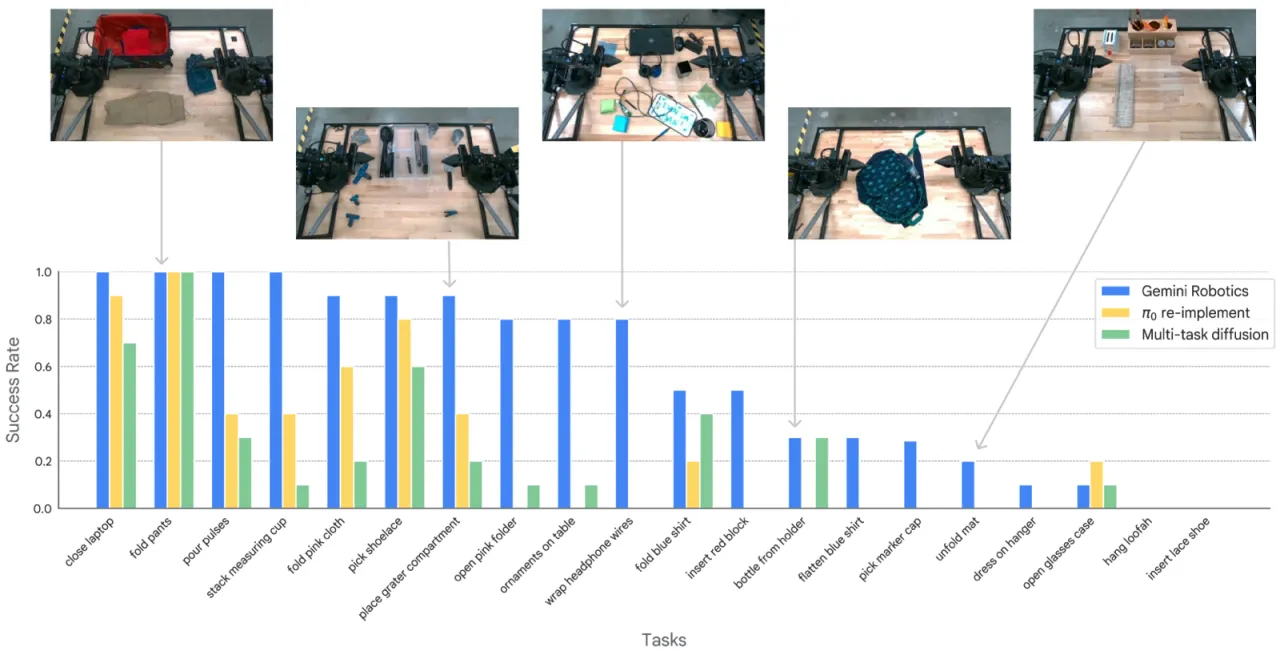
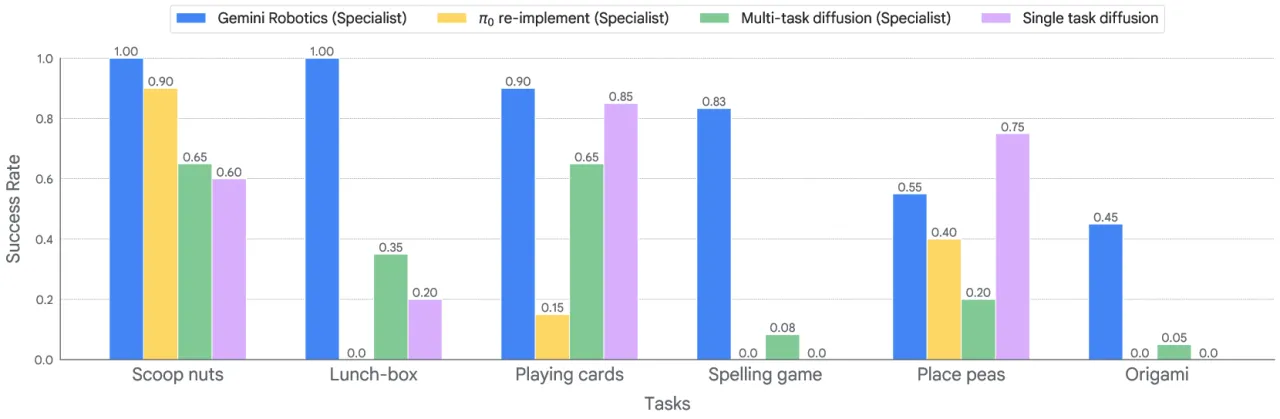
论文明确指出:"For tasks that require dexterous motions, the zero-shot success rate is not high"(Table 6 caption)。Gemini Robotics-ER 在真实机器人上进行折叠衣物(dress folding)等高灵巧任务时,零样本成功率显著低于简单抓取任务;Pack Toy 任务在仿真中零样本成功率为 0%。
VLM 与实时控制之间存在固有鸿沟
论文指出:"As a VLM, there are inherent limitations for robot control, especially for more dexterous tasks, due to the intermediate steps needed to connect the model's innate embodied reasoning capabilities to robotic actions."即便 Gemini Robotics-ER 具备较强的具身推理能力,将其与精确的关节-级别运动控制衔接仍需复杂中间步骤。