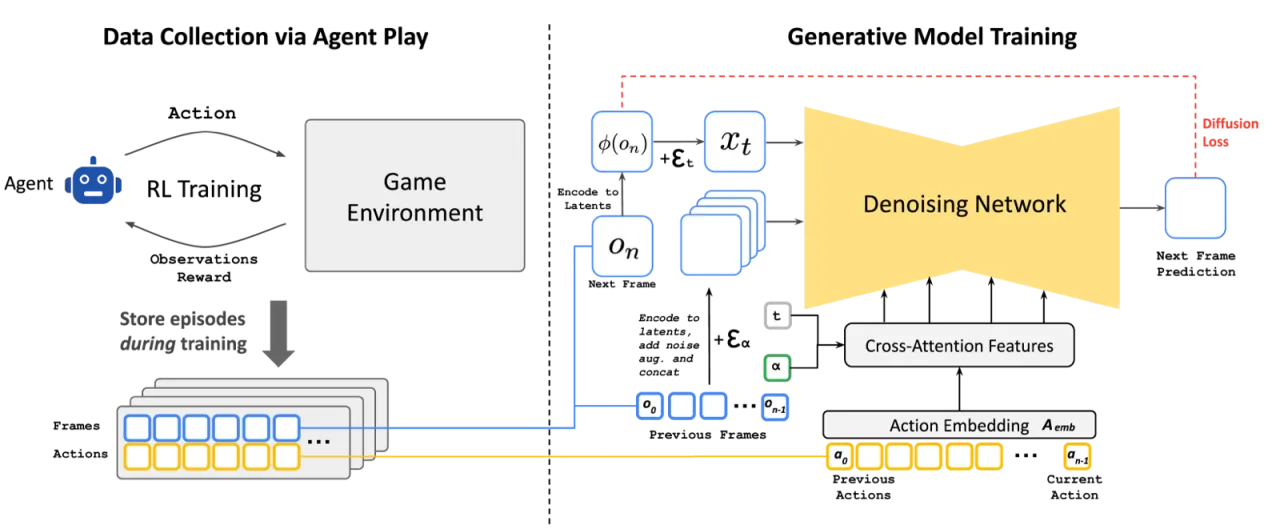
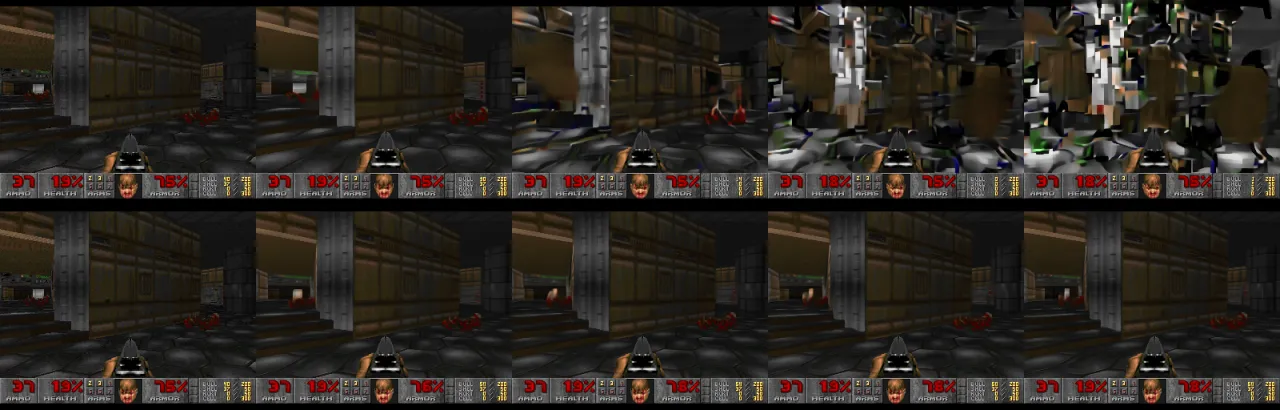
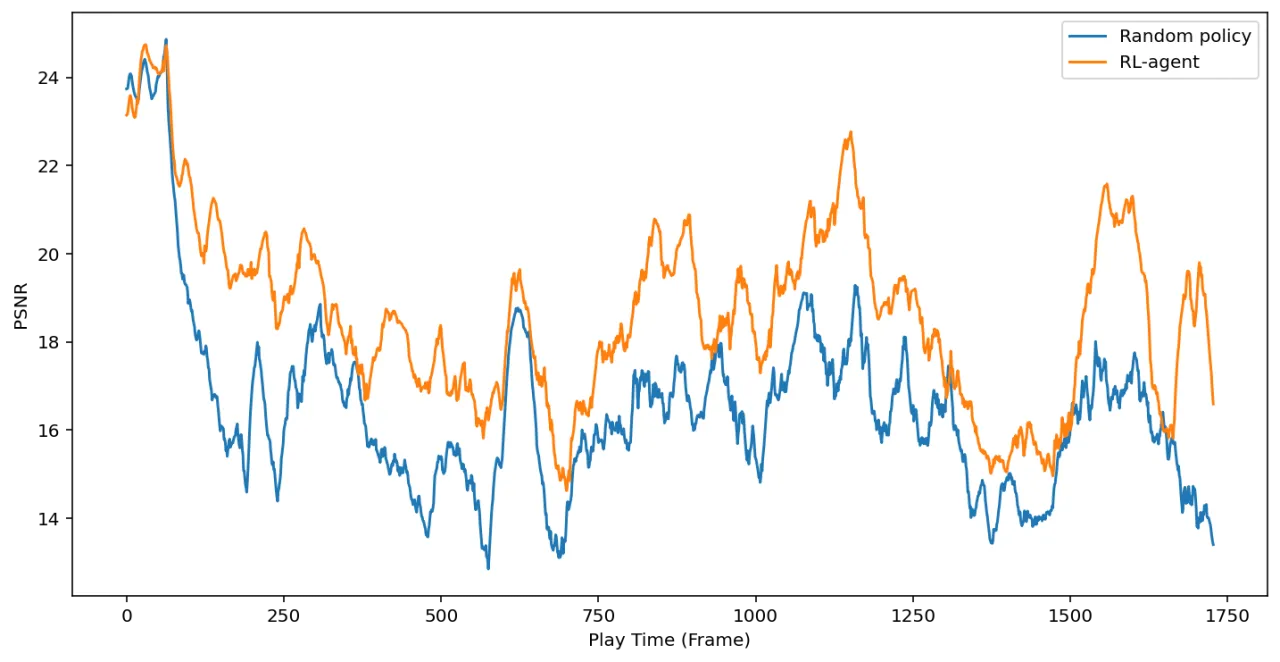
传统游戏引擎依赖大量手工编写的规则和渲染管线,开发成本极高。
随着生成模型能力的飞速提升,一个自然的问题随之浮现:
神经网络能否取代传统游戏引擎,直接从数据中学会模拟复杂的交互式环境?
此前的探索(如 World Models、GameGAN)已展现出可能性,但均无法支持实时互动游玩,也难以保持长时序的视觉一致性。
"We present GameNGen, the first game engine powered entirely by a neural model that enables real-time interaction with a complex environment over long trajectories at high quality."
模型仅能访问约 3.2 秒的历史上下文(64 帧),而真实游戏状态可能需要更长的记忆才能维持一致性。
作者指出:"The model only has access to a little over 3 seconds of history",
模型极可能依赖强启发式来弥补,但在需要长期记忆的场景(如打开过的门、拾起的物品)中可能出现错误。
训练数据覆盖不足(Agent Behavioral Gap)
智能体在训练中并未探索游戏的所有关卡、位置和交互,导致模型在这些未见过的场景中可能产生错误行为。
作者明确表示:"the trained agent does not explore all of the game's locations and interactions, leading to erroneous behavior in those cases."
无法用于创作新游戏(Game Creation Limitations)
现阶段 GameNGen 是针对特定游戏(DOOM)的模拟器,无法像传统游戏引擎那样用于开发全新游戏内容。
作者坦言:"We are not able to easily produce new games with GameNGen",
这意味着其应用场景目前仍局限于已有游戏的模拟与研究。