01 动机
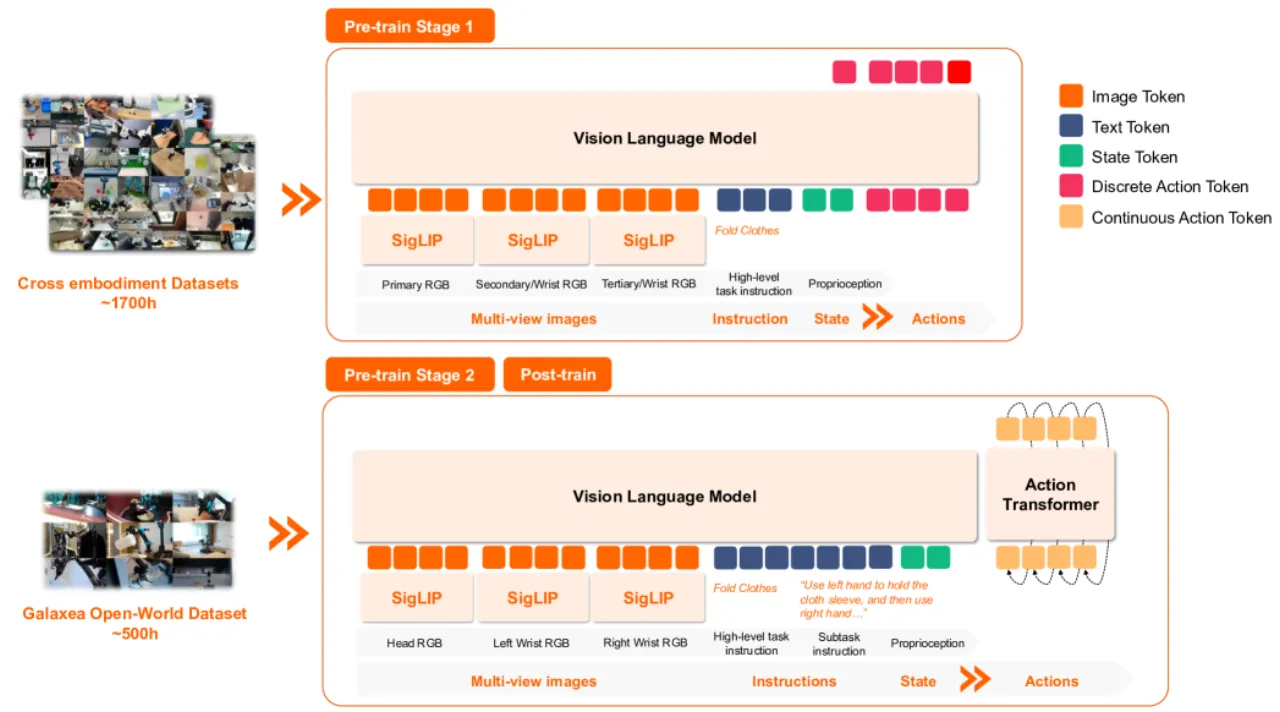
VLA 模型的发展面临一个核心瓶颈:缺乏大规模、高质量的开放世界机器人数据。现有数据集(如 BridgeData V2、DROID、Open X-Embodiment)大多在受控或人工布置的实验室场景中采集,场景多样性有限、语言标注粗糙,难以支撑 VLA 向真实世界的泛化。
"a substantial bottleneck persists due to the scarcity of large-scale, high-quality, open-world robot data."
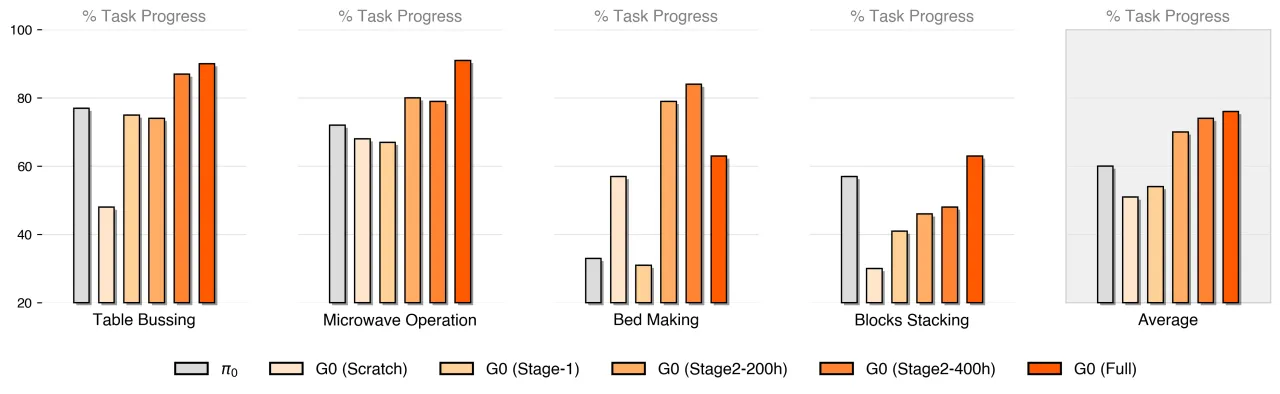
500h高保真数据总时长
100K演示轨迹数量
150+任务类别
50真实场景数量
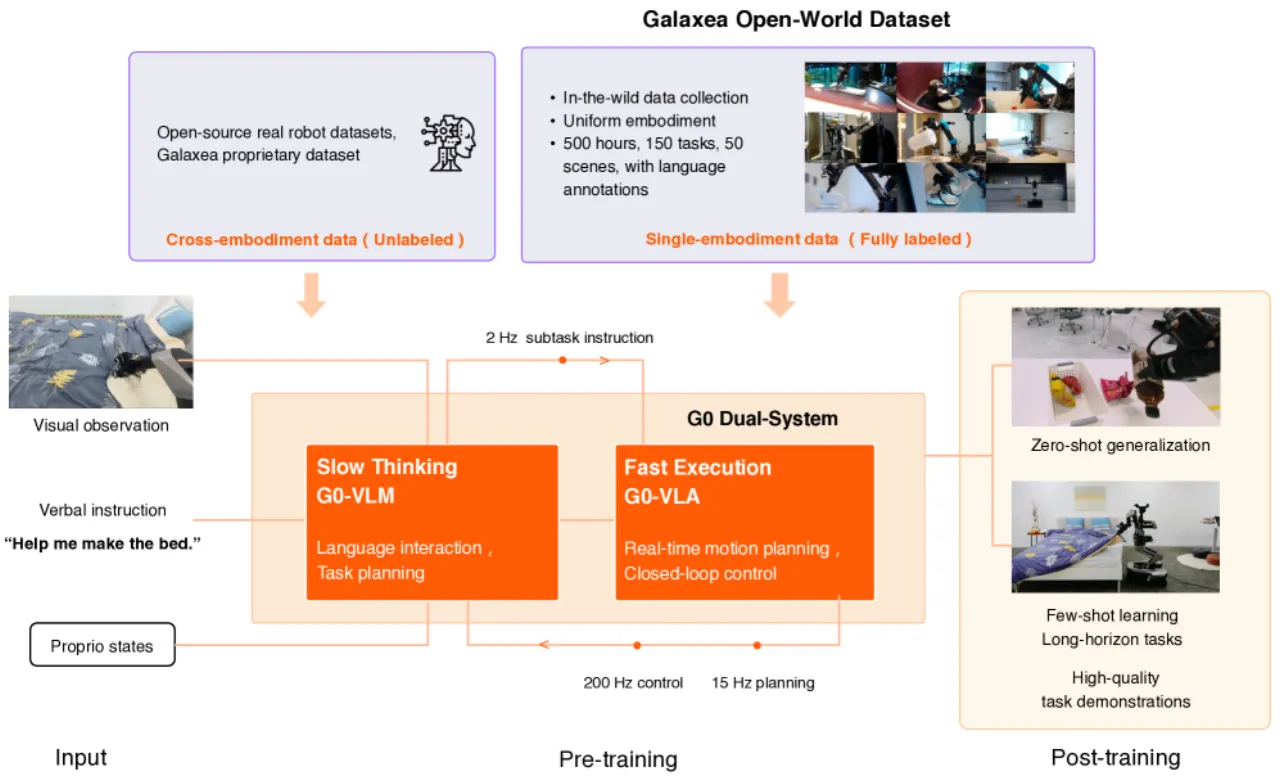
现有多具身数据集(如 OXE)虽然规模庞大,但来自不同机器人平台,动作空间不统一,反而可能因"具身鸿沟(embodiment gap)"损害特定机器人的学习效果。本文以单一机器人平台(Galaxea R1 Lite)在 11 个真实地点的 50 个场景采集数据,涵盖居民区、餐饮、零售和办公等多种环境,并提供细粒度子任务级别的语言标注,从根本上解决数据多样性与一致性的矛盾。
数据采集三原则
- Observability:视觉流包含所有任务相关信息
- 数量与质量:简单任务需约 100 条演示;复杂序列质量优先
- Linguistic grounding:子任务级语言标注,支持多模态对齐
数据集核心统计
- 1,600+ 种独特物体
- 58 种操作技能(从 "pick" 到 "whole-body" 协调)
- 11 个物理采集地点
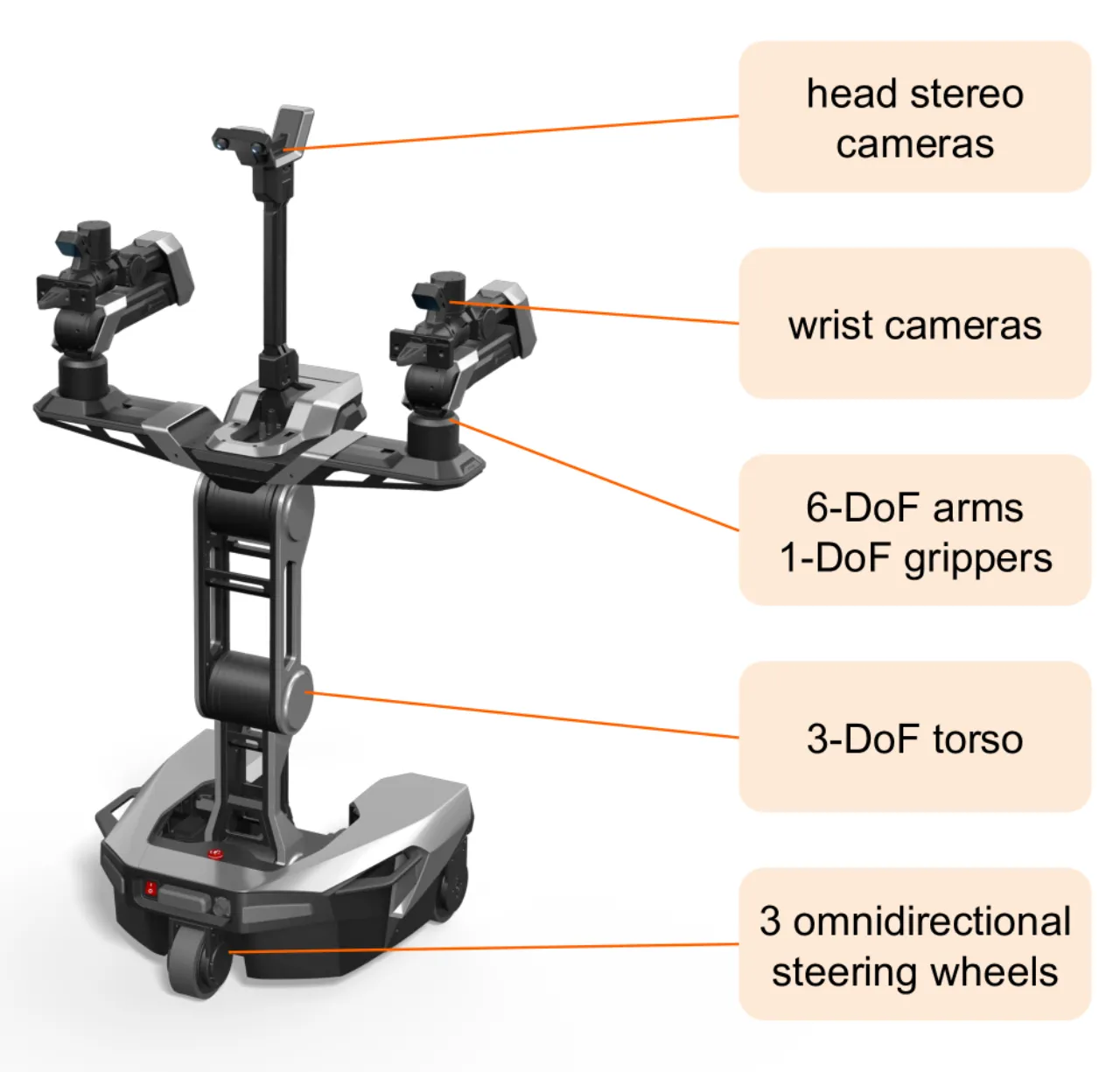
- 使用同构遥操作(isomorphic teleoperation)采集