"We propose instead to predict pointmaps in upright, gravity-aligned frames that exploit strong
structural cues present in many real-world scenes. Unlike camera-centric frames,
gravity-aligned frames share a common vertical axis across viewpoints,
reducing the rotational degrees of freedom needed to relate pointmaps to one another."
图 2(论文第 3 页):G3T 模型架构。
左图:相机坐标系(VGGT)与重力对齐坐标系(G3T)的坐标系对比示意。
右图:G3T 在 VGGT 架构上做了两处关键修改:
(1) Point Head 改为输出重力对齐点图 𝒳G;
(2) 原 Camera Head 被替换为两个新头:
Local Camera Head(输出重力到相机的旋转 RG→C 及内参)和
Relative Camera Head(仅输出 1 DoF 的 yaw 旋转及平移 t)。
重力对齐点图预测
传统 VGGT 的点图在相机坐标系 C1 中表示,G3T 改为在重力坐标系 G1(第一帧的重力对齐坐标系)中表示。
重力坐标系保持 y 轴朝上(与重力方向对齐),不同视角的点图可共享同一垂直轴。
Point Head 在训练时监督于由 COLMAP model_orientation_aligner 提取的真实重力方向标注。
对于相机姿态预测:Local Camera Head 预测每帧的 gravity-to-camera 旋转矩阵(将重力坐标系旋转至相机坐标系),
以及相机内参(焦距、主点)。Relative Camera Head 仅预测 1 DoF 的 yaw 角和平移向量,
大幅简化了相对姿态估计问题。
GA-Procrustes:重力感知子图对齐
标准 Procrustes 对齐需要 7 DoF 变换(包含完整的 3D 旋转);
由于所有子图均在重力对齐坐标系中,对齐旋转只需绕 y 轴旋转(即 xz 平面上的 2D 旋转),
从而将对齐问题简化为 5 DoF(1 DoF yaw + 3D 平移 + 1 缩放)。
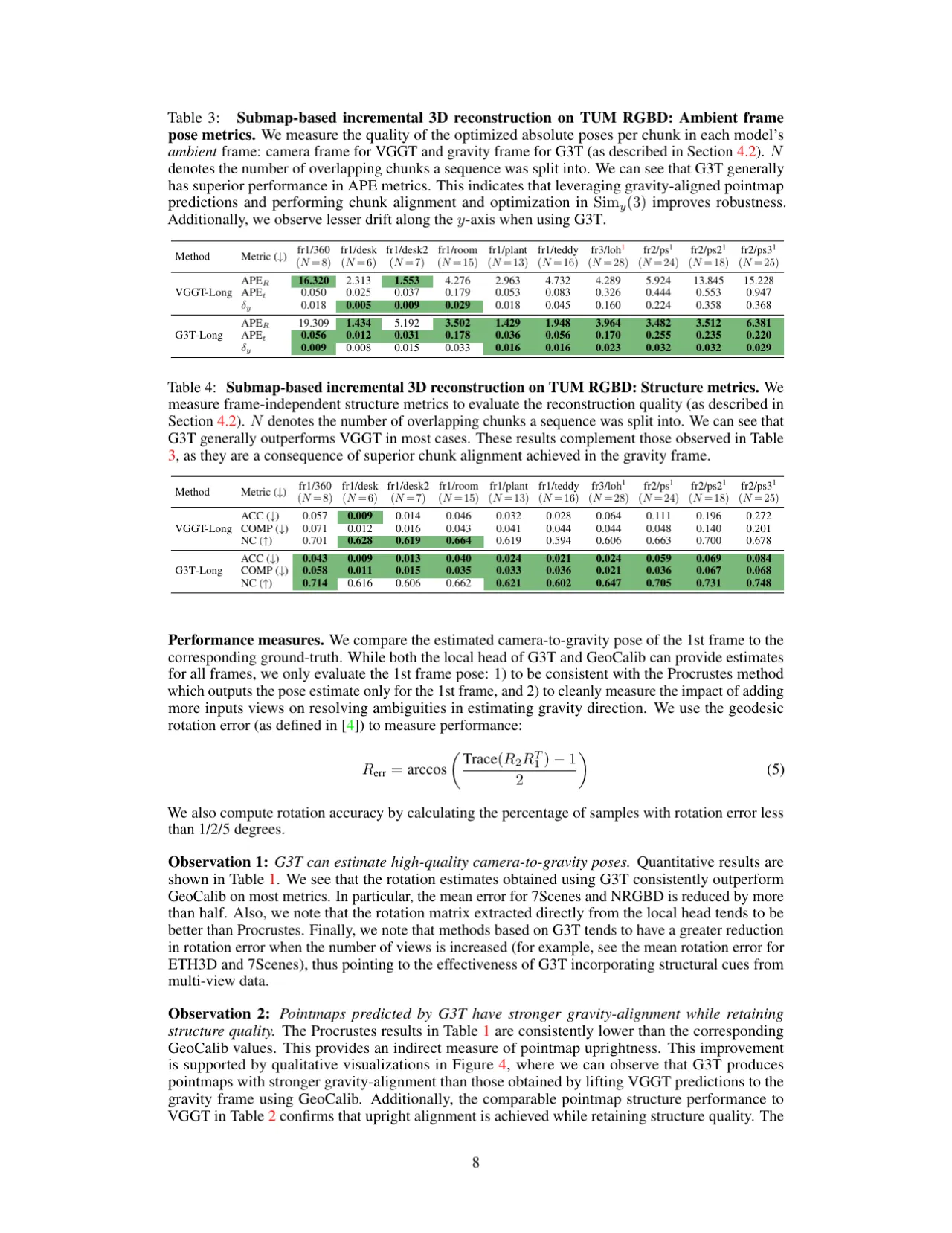
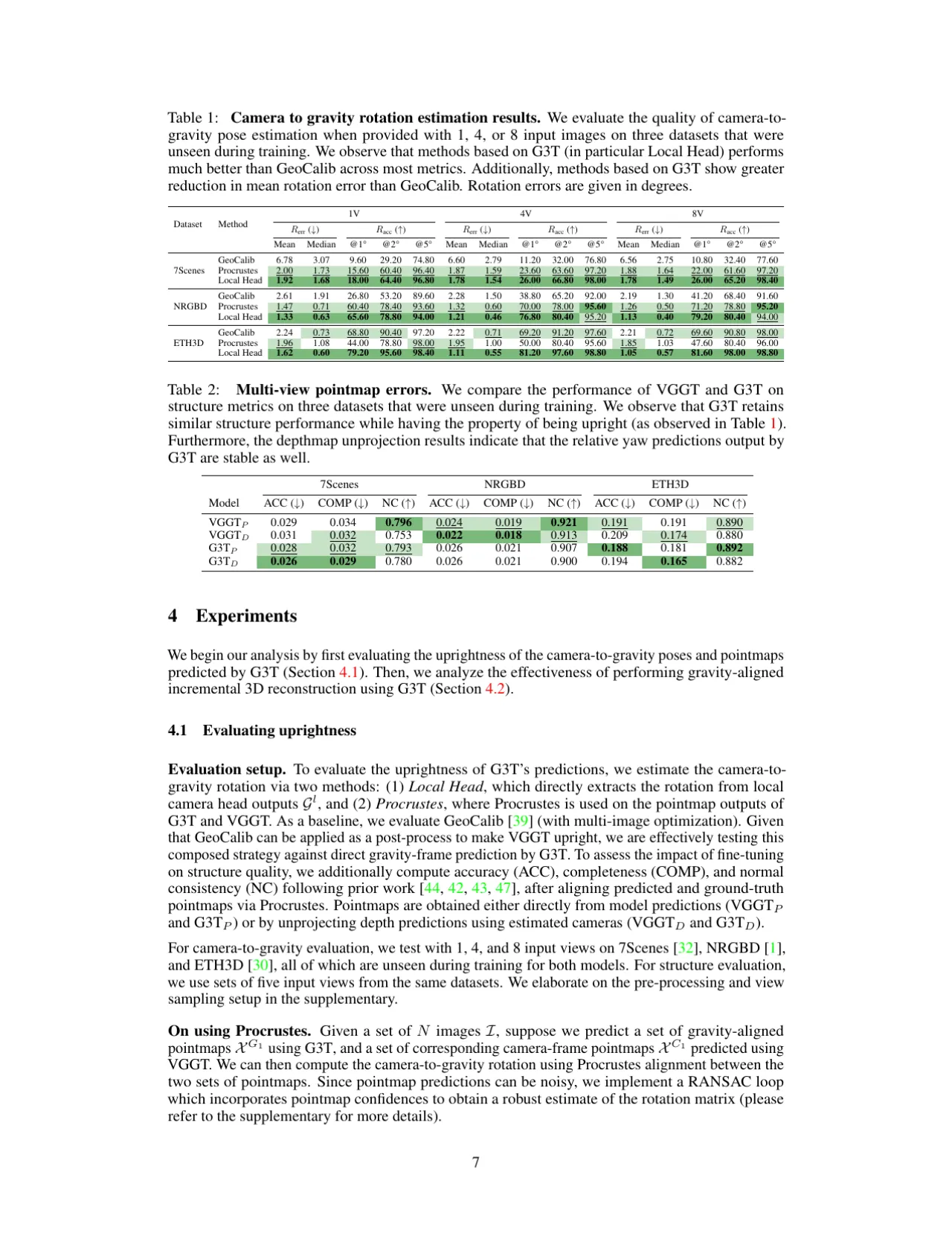
结论(Observation 1):"G3T can estimate high-quality camera-to-gravity rotation estimates,
reducing mean errors by more than half compared to post-hoc gravity alignment with GeoCalib."
说明:以下第 1、2 条为论文中明确陈述的限制(stated by authors);第 3、4 条为从方法设计中推断的限制(inferred from design)。
(stated)场景结构先验不明确时预测退化
"G3T may not produce good upright-aware predictions in scenes with ambiguous structural cues."
例如,在缺少上下文的情况下,近距离拍摄地板或墙壁时,
G3T 难以正确估计直立方向,产生倾斜的点图(论文 Figure 5 的失败案例)。
(stated)水平旋转视角导致方向混淆
对于竖向物体(如橱柜)的水平旋转图像,模型可能产生方向错误的点图。
"G3T can struggle to estimate upright pointmaps from close-up images of floors and walls
if additional unambiguous context is not present."