01 动机
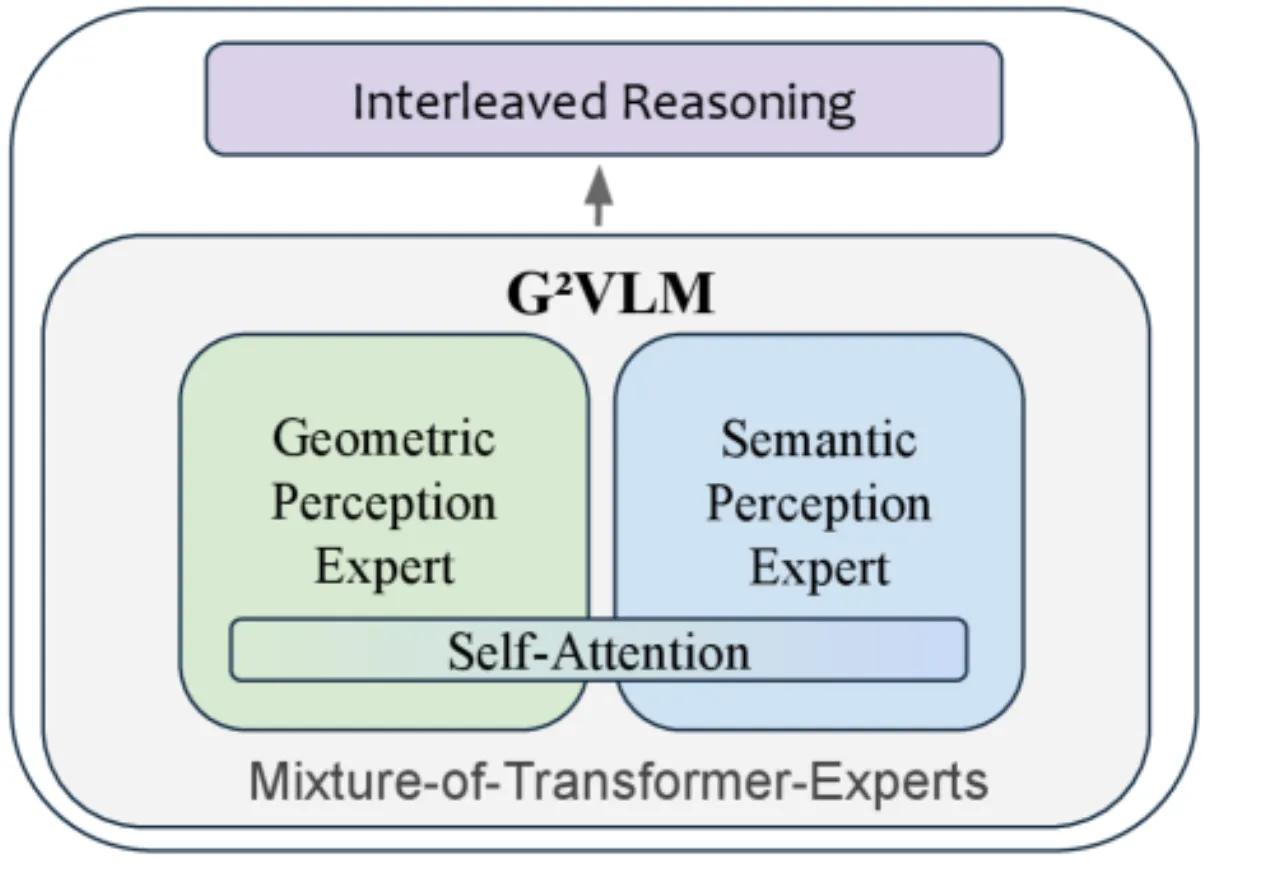
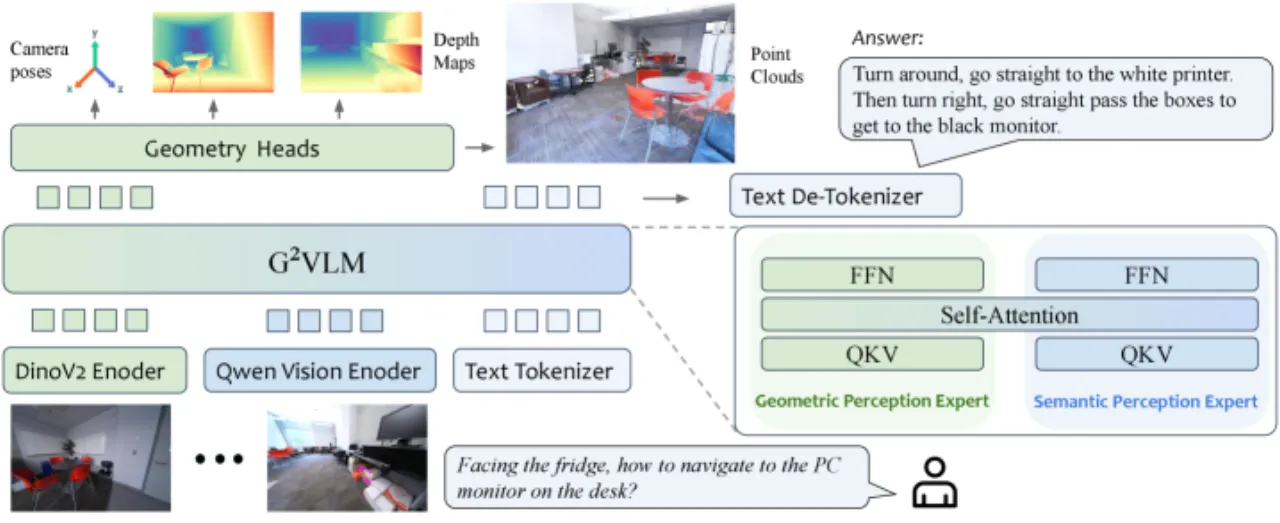
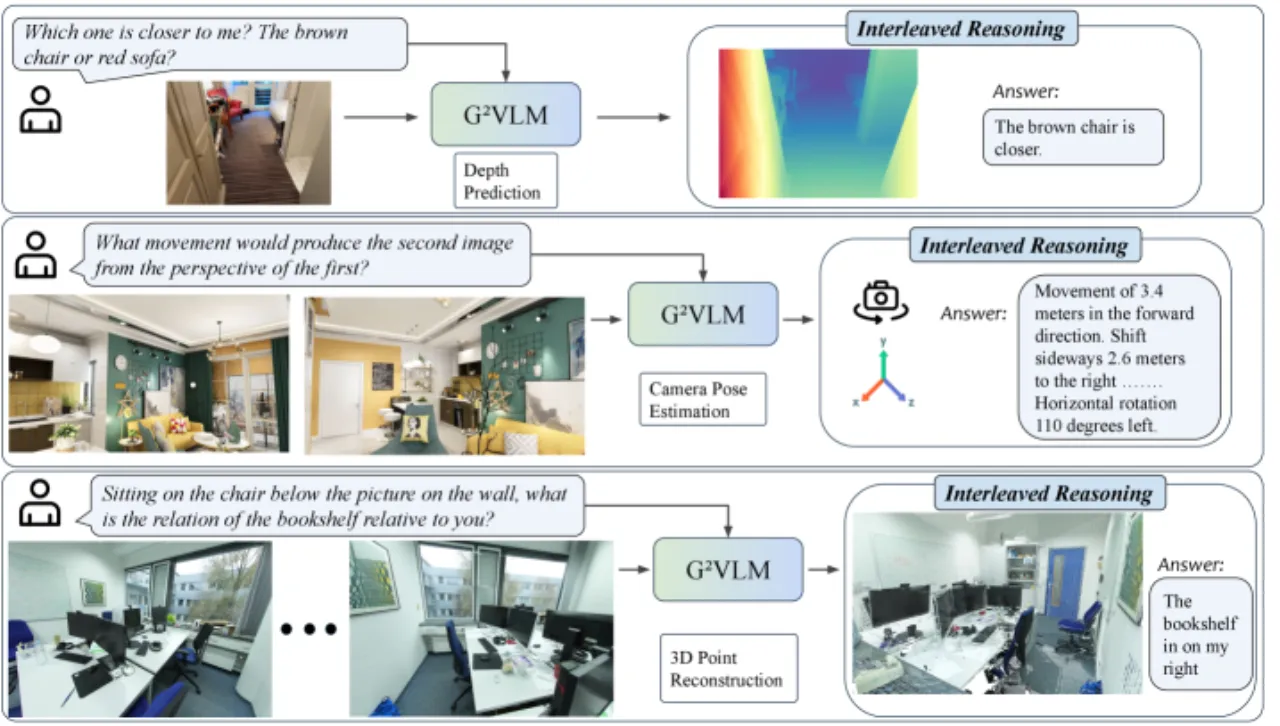
现有视觉语言模型(VLMs)将图像视为"扁平"的 2D 数据处理,缺乏对三维空间的几何理解能力,导致在需要 3D 空间推理的任务上表现受限。另一方面,专门的视觉几何模型虽能进行精确的 3D 重建,但不具备高层语义理解和自然语言交互能力——两类模型之间存在鸿沟。
"By unifying a semantically strong VLM with low-level 3D vision tasks, we hope G2VLM can serve as a strong baseline for the community and unlock more future applications, such as 3D scene editing."
54.87SPAR-Bench 均值
(本文 G2VLM-SR)
(本文 G2VLM-SR)
38.81GPT-4o 在 SPAR-Bench
的均值(对比基线)
的均值(对比基线)
48.33MindCube 均值
(本文最优)
(本文最优)
2B参数量,媲美
更大规模的模型
更大规模的模型
为何现有方法不足?
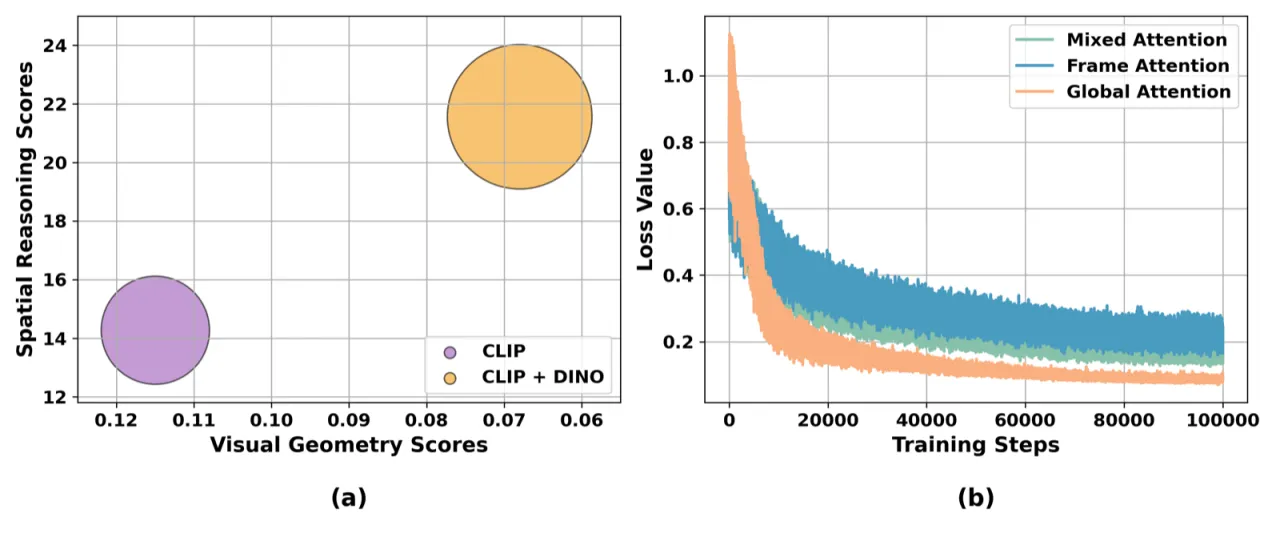
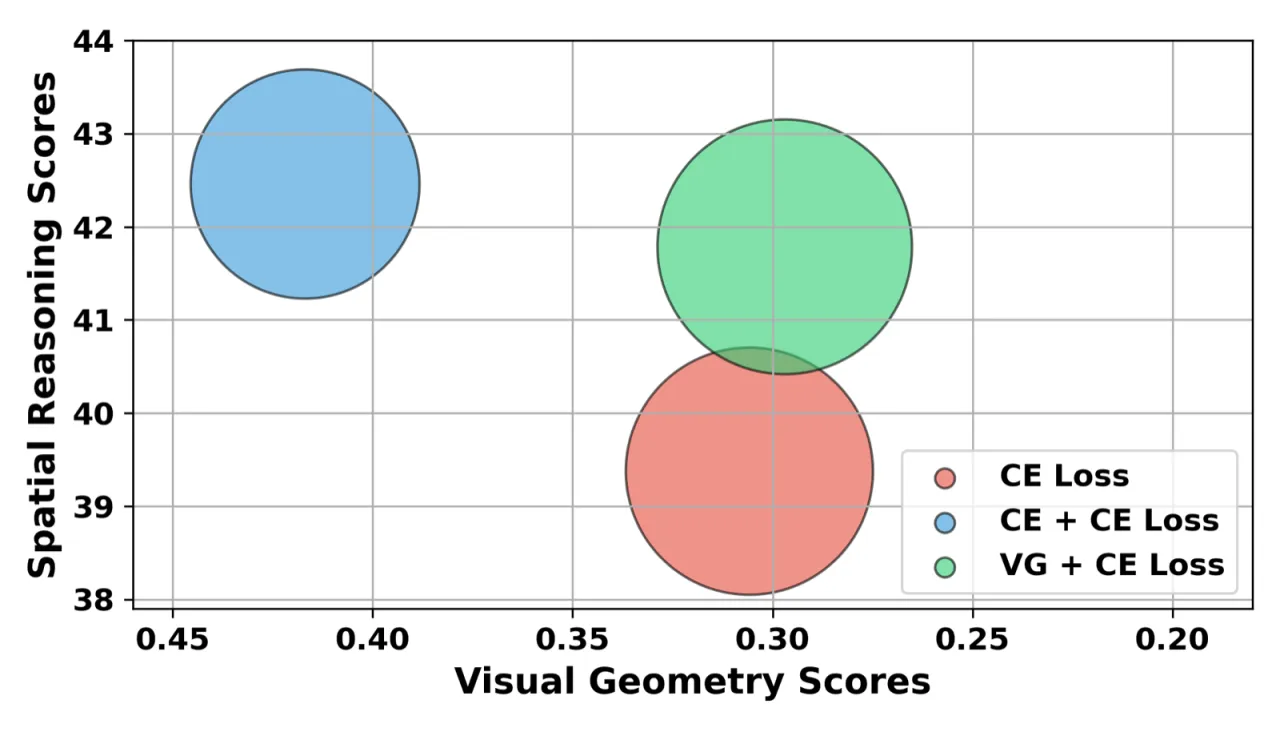
- 空间推理 VLMs:将图像视为纯 2D 输入,缺乏几何归纳偏置,空间推理能力上限受限。
- 前馈视觉几何模型(如 VGGT、π³):擅长 3D 重建,但不具备语义理解和自然语言交互能力。
- 大型专有模型(如 GPT-4o):虽具备语言能力,但空间推理分数(SPAR-Bench 38.81)远低于本文 2B 参数的专用模型(54.87)。