01 动机
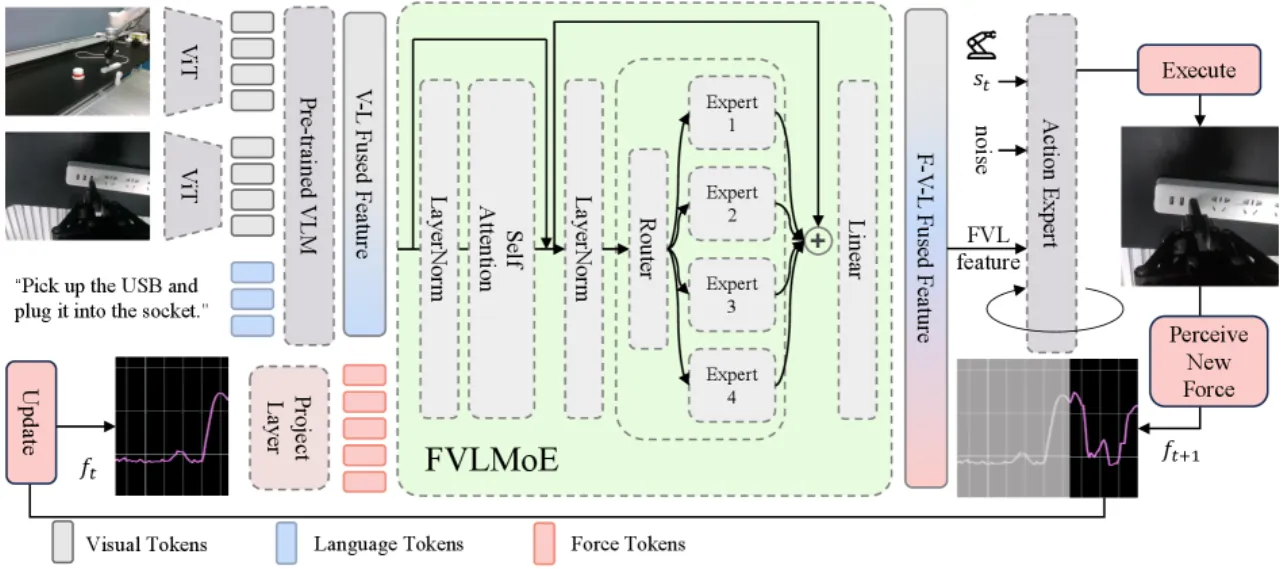
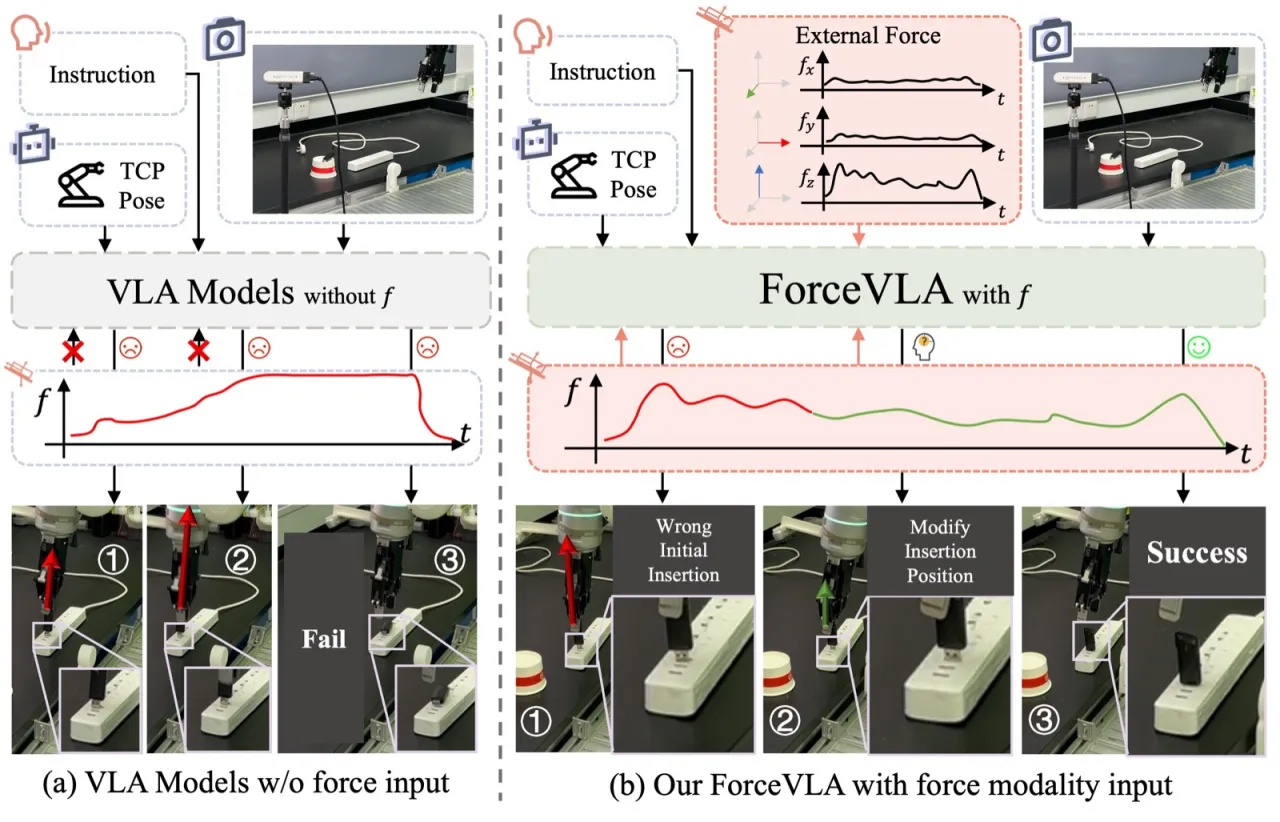
现有 VLA 模型在语义理解方面表现出色,却难以应对接触密集型操作(contact-rich manipulation)——如插拔、工具使用、装配——这类任务要求精细的力控制,尤其在视觉遮挡或动态不确定性场景下。 机器人系统普遍忽视了力感知这一关键模态,而人类却自然地整合触觉与本体感知来适应操作策略。
"6D external force sensed at the robot's end-effector should be treated as a first-class modality",而非事后追加,这与人类操作中触觉与本体感知的协同机制一致。
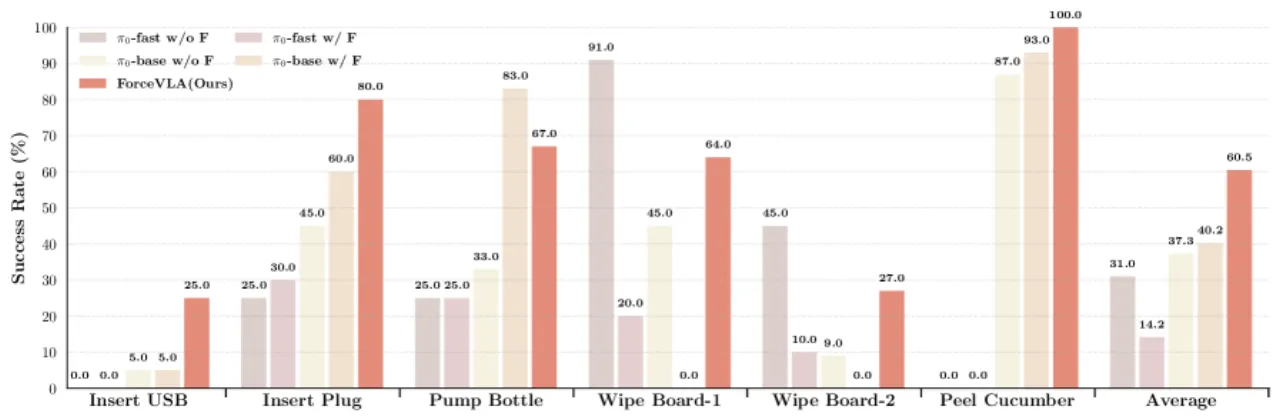
23.2%平均成功率提升(vs. π₀-base w/o Force)
80%单任务最高成功率(对象泛化测试)
90%视觉遮挡条件下成功率
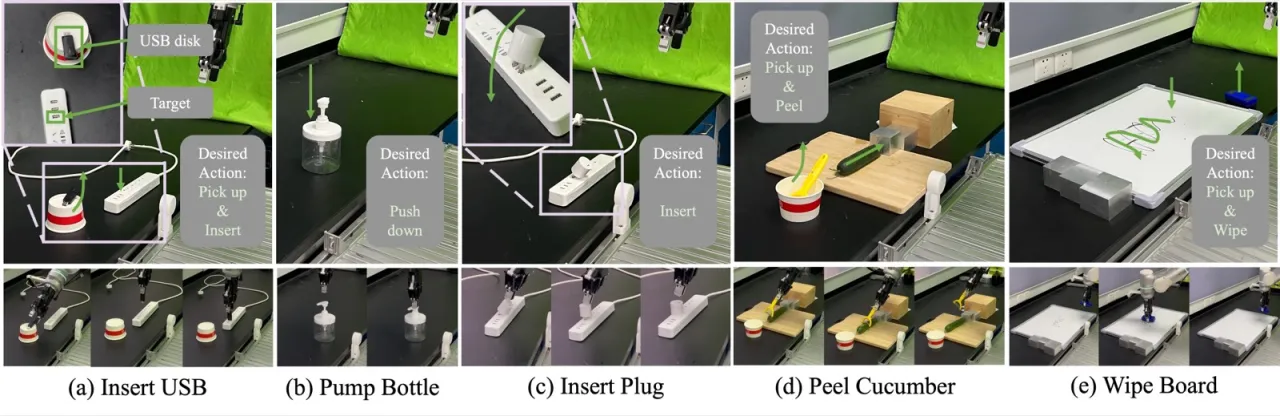
5接触密集型任务 · 244 条轨迹 · 140K 同步帧