01 动机 Motivation
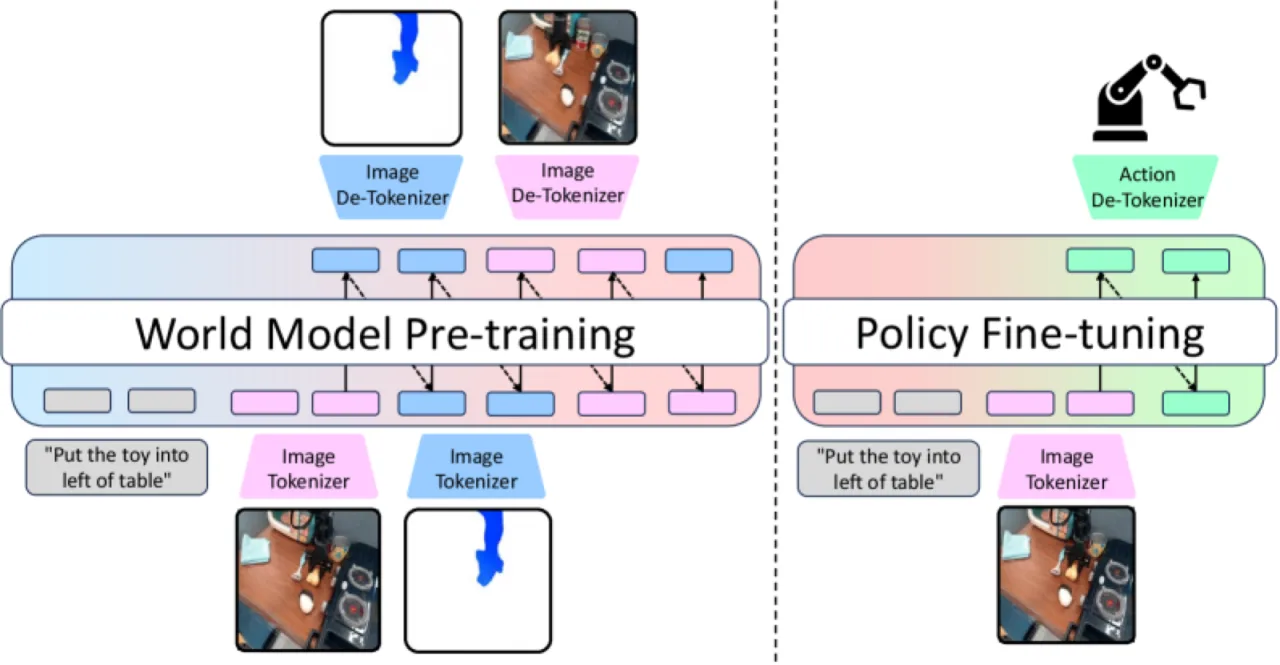
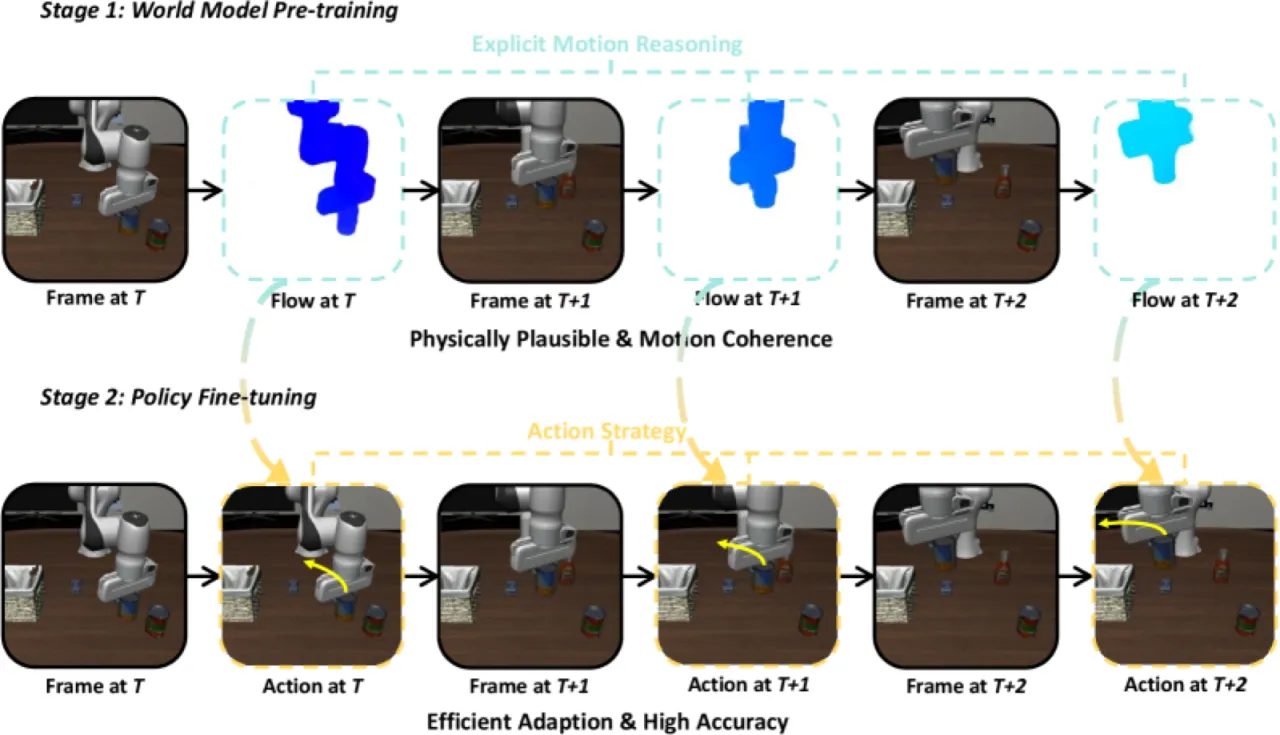
当前主流 VLA 模型依赖基于"next-frame prediction"训练的世界模型,试图直接预测未来帧的外观,而不显式建模底层的运动动态。这导致两个核心问题:预测在物理上不合理(物体凭空消失、机械臂轨迹混乱),且预训练目标与下游动作生成之间存在明显的领域鸿沟。
"This approach attempts to predict future frame appearance without explicitly reasoning about underlying dynamics, leading to physically implausible visual forecasts and inefficient policy learning."
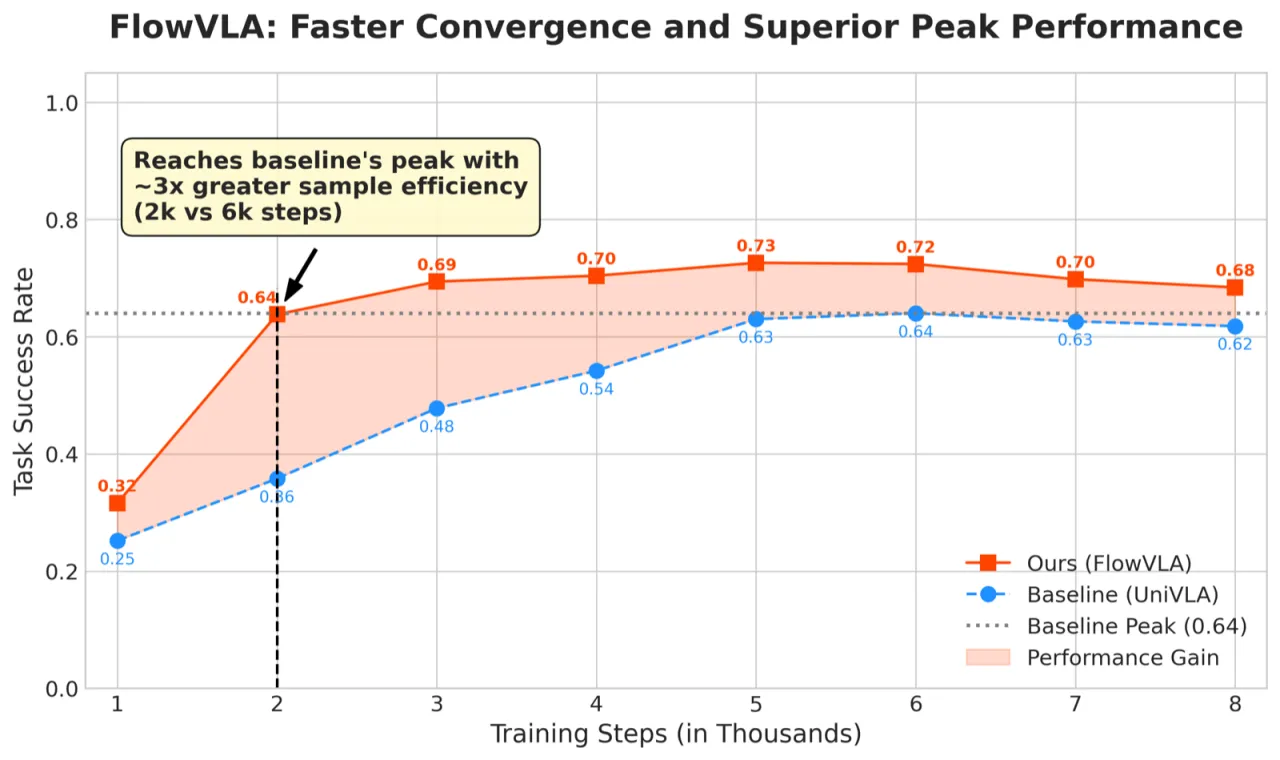
88.1%LIBERO 平均成功率(vs. UniVLA 84.0%)
74.0%SimplerEnv 平均成功率(vs. UniVLA 65.6%)
44.0%真实机器人平均成功率(vs. UniVLA 31.0%)
+55%低数据场景下相对基线的成功率提升
传统世界模型陷入"pixel-copying trap":模型只是复制静态背景而非理解时空动态,导致"blurry, inconsistent, and physically implausible long-horizon forecasts"。FlowVLA 通过在帧预测前插入光流预测步骤,强迫模型先理解"场景如何运动",再推断"场景将呈现什么样子"。