"We present FLOWER, an efficient VLA flow policy capable of pretraining a 950M parameter model in only 200 H100 GPU hours, while achieving competitive performance across 190 tasks spanning simulation and real-world benchmarks."
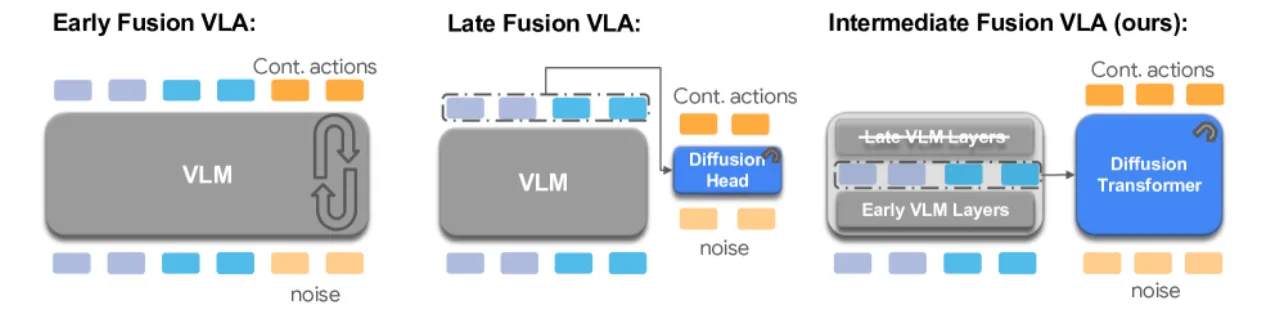
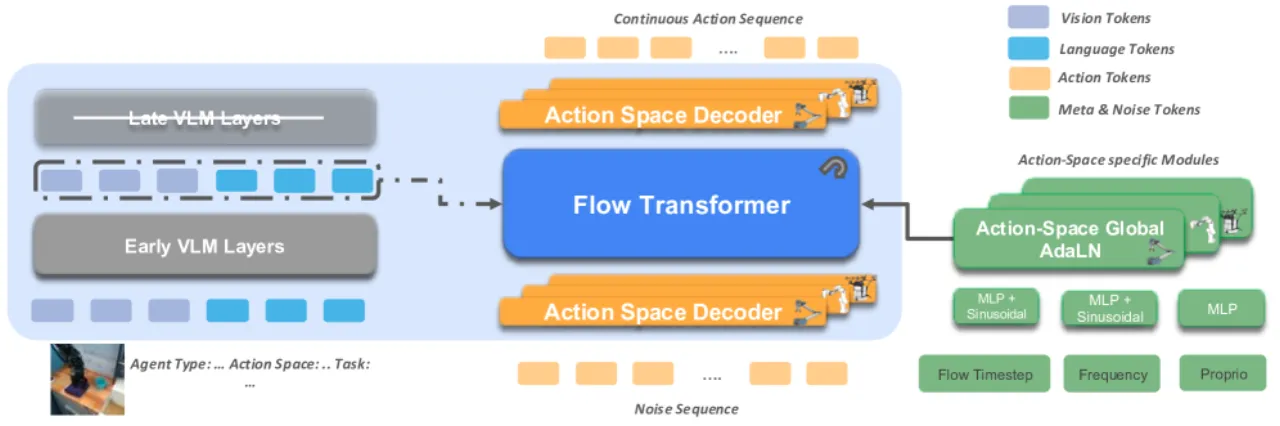
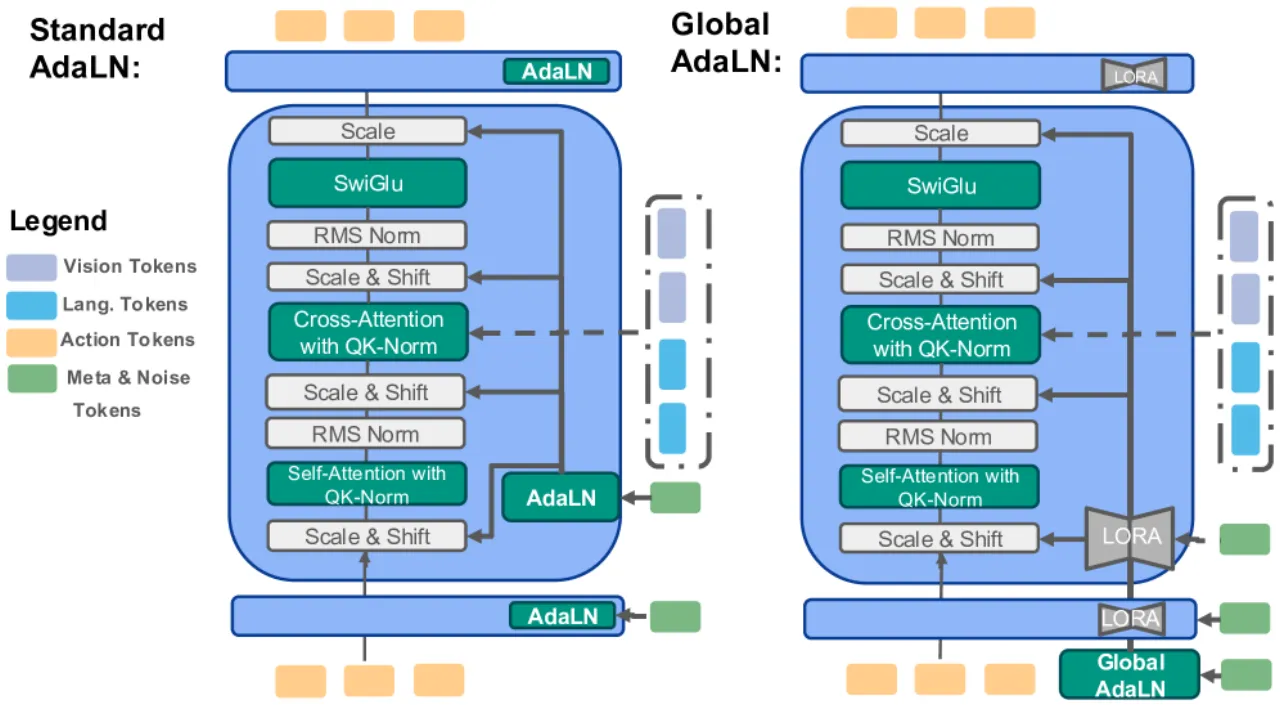
"The intermediate representation prunes between 30% and 50% of pretrained VLM layers, yielding a 20–35% parameter reduction while preserving rich cross-modal semantics."
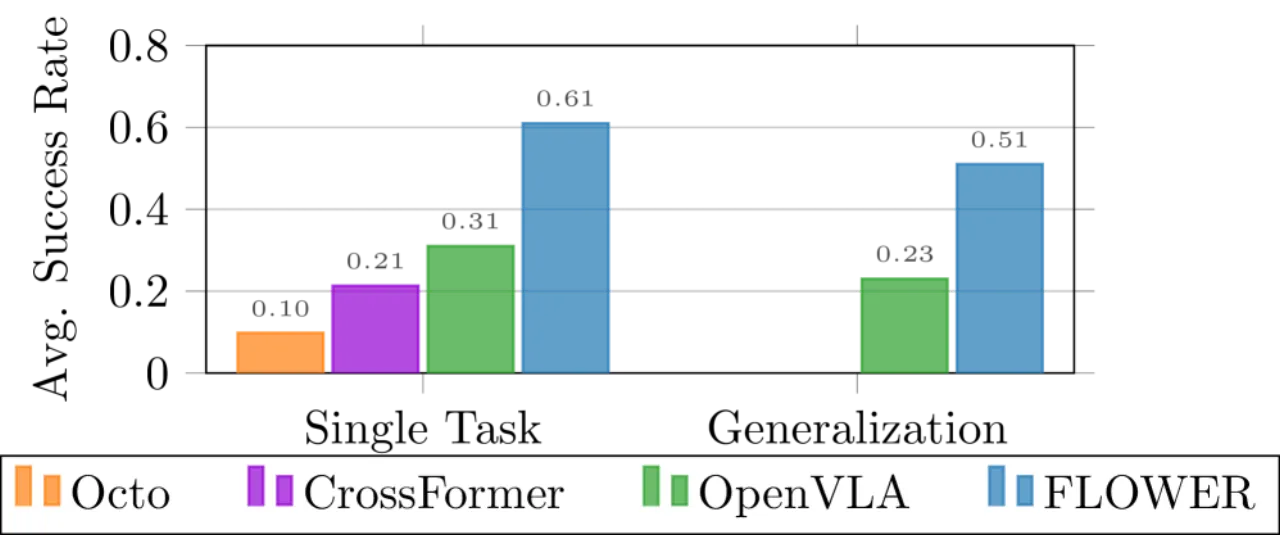
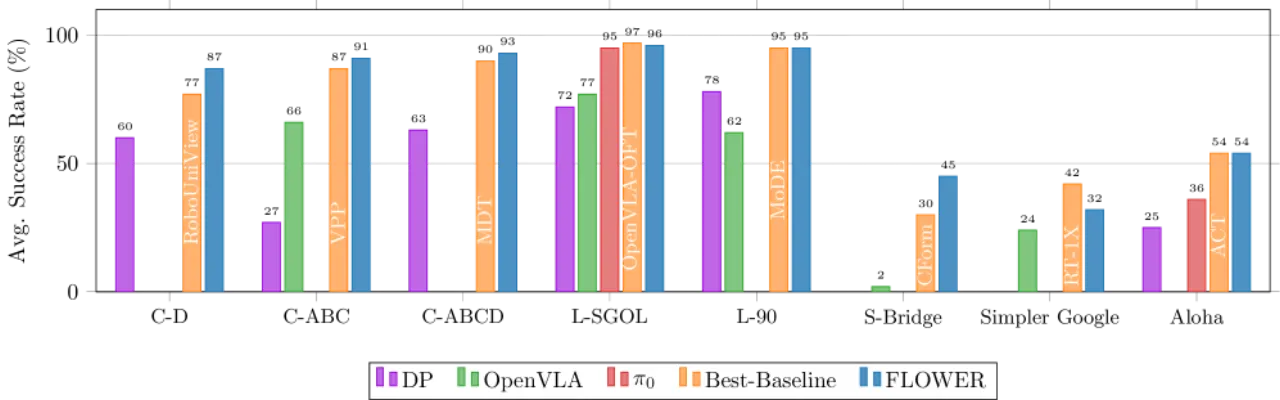
消融实验证明,中间融合相比早期融合提升 61 个百分点(LIBERO-Long:93.4% vs 33.4%),相比晚期融合提升 21 个百分点,优势显著。
"It relies on an iterative sampling procedure, which is inherently slower than a single forward pass from deterministic policies."——基于 flow matching 的多步去噪推理,在步数较多时仍慢于单步确定性策略(如 ACT)。
仅验证了三种操作动作空间
"We have validated FLOWER primarily on three manipulation action spaces; its ability to generalize to other embodiments, such as mobile navigation or humanoid locomotion, remains unexplored and is an important direction for future work."——尚未在移动导航或人形机器人场景下验证。
在 SIMPLER Google Robot 基准上有待提升
"Pretraining performance for zero-shot deployment on the SIMPLER Google Robot benchmark indicates that further improvements are needed. We hypothesize that the generalization tested in SIMPLER benefits from larger models."——在 Google Robot 设置下(31.9%)低于 RT-1-X(42.4%),作者推测更大模型有助于改善。
约 1B 参数对低资源场景仍有挑战
"Although FLOWER is considerably smaller than most state-of-the-art VLA models, its ≈1 B-parameter size may still present deployment challenges in low-resource or real-time settings."
8/10 基准在仿真环境中进行
"Eight out of our ten used benchmarks are conducted in simulation, limiting the extent to which our results can be taken as evidence of real-world generalization."——真实世界结果相对有限,泛化结论需谨慎外推。