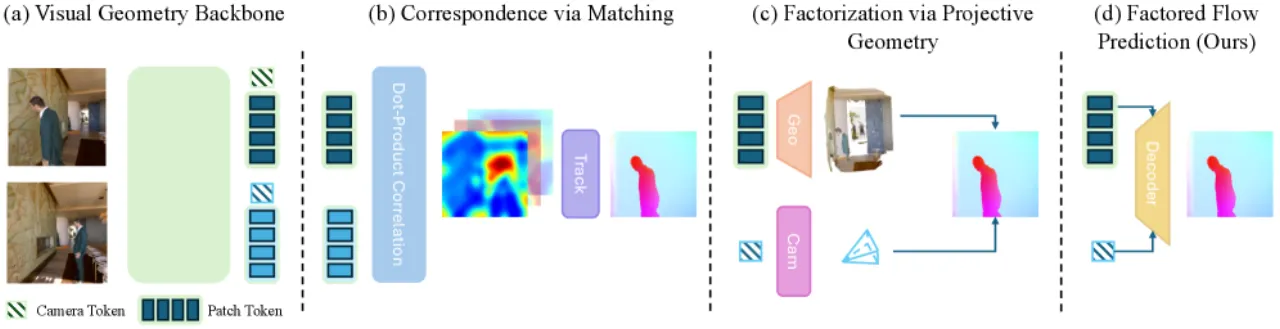
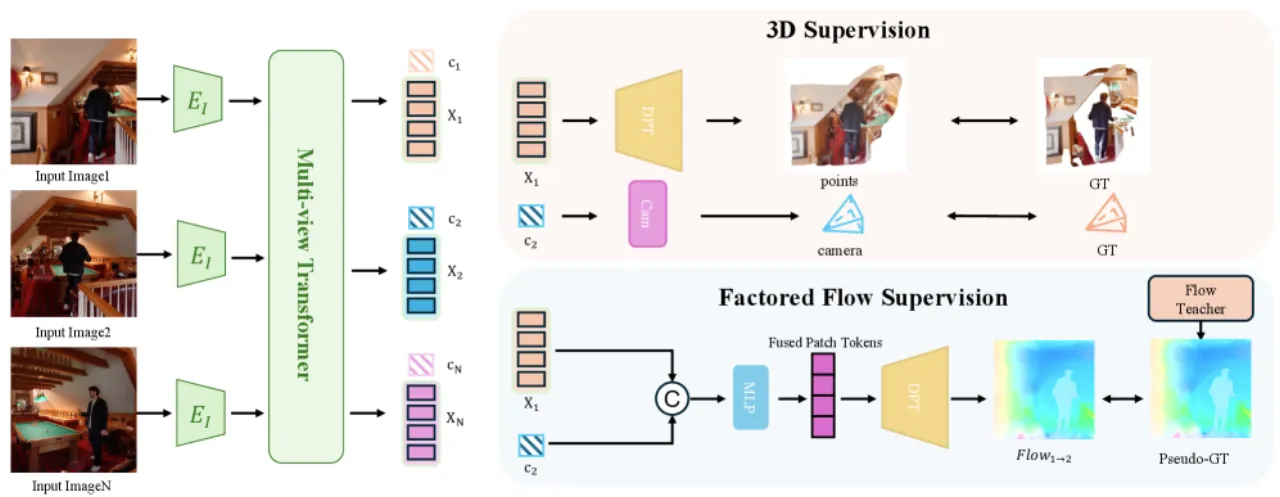
"Current feed-forward 3D/4D reconstruction systems rely on dense geometry and pose supervision — expensive to obtain at scale and particularly scarce for dynamic real-world scenes."
"Flow3r relies on off-the-shelf models to provide pseudo-ground-truth flow supervision, and there can be domains where such 2D prediction fails." — 在某些分布外领域(如医学图像、航拍等),预训练2D光流模型可能给出低质量伪标注,从而影响几何学习。
复杂动态场景中多运动体的挑战(Complex Multi-Object Dynamics)
"Although our factored flow formulation elegantly handles dynamic scenes…, Flow3r may struggle under complex scenes with multiple independently moving components." — 当场景中存在多个独立运动物体时,单一相机特征 token 可能无法完整编码所有运动信息。
当前实验规模距真正大规模仍有差距(Scale Gap to Web-Scale)
"Our current experiments operate at a moderate scale (~800K video sequences for flow supervision), and scaling to truly large-scale settings (~10-100M videos) presents an exciting but unexplored direction." — 尽管~800K序列已展现出良好的扩展性,更大规模训练的潜力尚未被探索,且对算力与存储提出了新挑战。
推断(inferred):因子化光流对独立流估计并非最优
作者本人指出:"our factored flow prediction is suboptimal for standalone flow estimation — since it enforces an information bottleneck by conditioning on the target-view camera token rather than patch features that contain richer visual cues." 即该设计优化的是几何监督信号质量,而非光流预测本身的精度。