01 动机(Motivation)
Flow matching 模型(如 SD3.5、FLUX)在图像生成上表现出色,但在多对象组合、属性绑定和文字渲染等复杂场景下仍有明显短板。在线强化学习(online RL)已被证明能显著提升大语言模型的推理能力,然而将其应用于 flow matching 模型面临两大根本挑战。
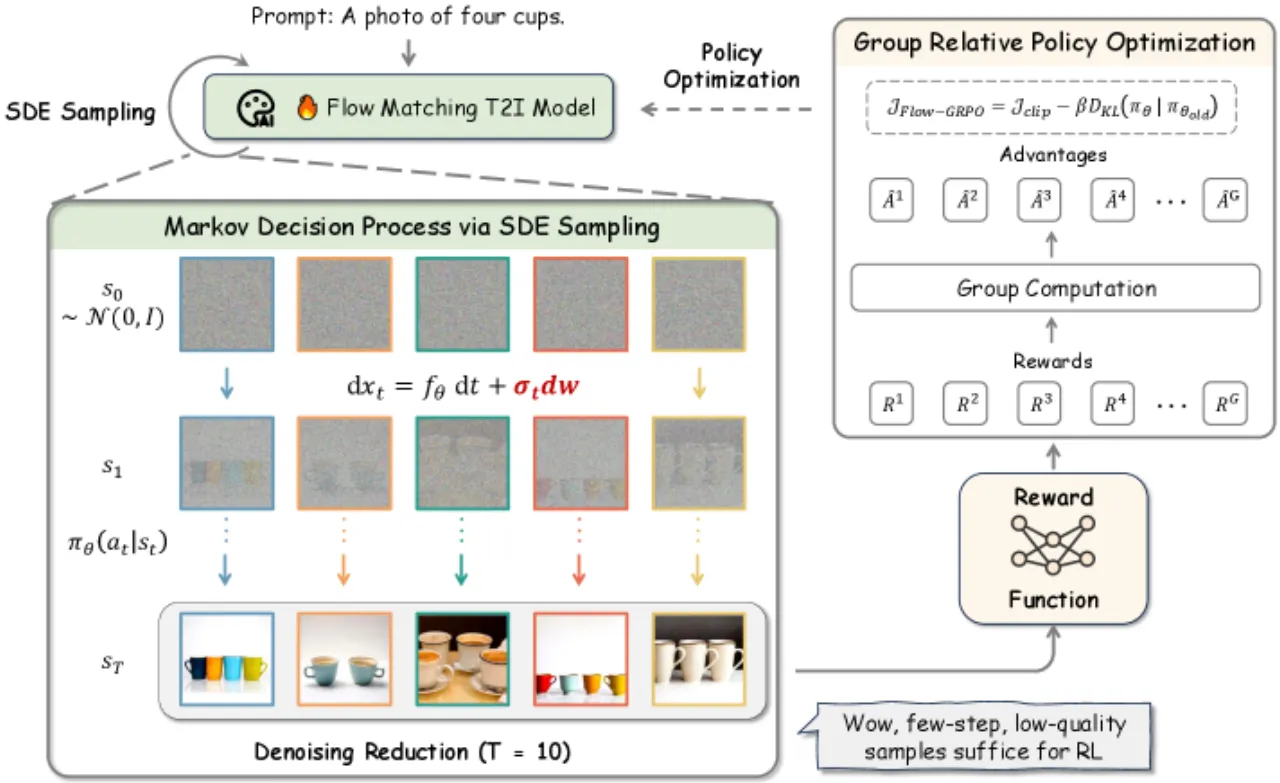
"This need for stochasticity in RL conflicts with the deterministic nature of flow matching models." — Flow matching 依赖确定性 ODE 采样,无法直接支持 RL 所需的随机探索;同时 flow model 推理需要大量去噪步数,数据收集代价极高。
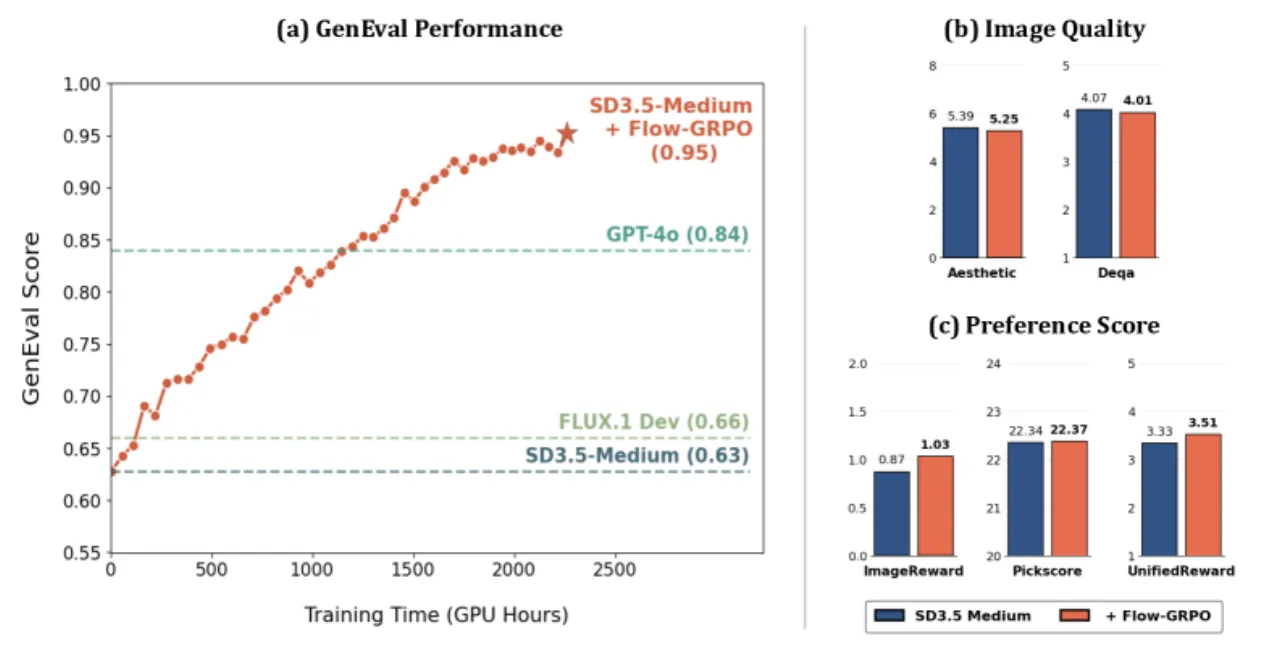
95%GenEval Overall(SD3.5-M + Flow-GRPO),超越 GPT-4o 的 84%
63%→95%组合图像生成准确率提升幅度
59%→92%视觉文字渲染(OCR)准确率提升幅度
4×Denoising Reduction 带来的训练采样加速比
核心挑战
- 确定性 vs. 随机性:RL 需要通过随机采样探索动作空间,而 flow matching 使用确定性 ODE,无法直接进行统计采样,policy ratio(Eq. 5 中的 r_t)在 deterministic 动态下计算代价极高。
- 采样效率瓶颈:Flow model 推理默认需要 T=40 个去噪步骤,在线 RL 每次收集训练数据都需完整运行,GPU 小时消耗极大,限制了实用性。
- Reward Hacking 风险:奖励模型可能被"钻空子"——奖励分数上涨而图像质量或多样性下降,这在 T2I 任务中尤为需要防范。