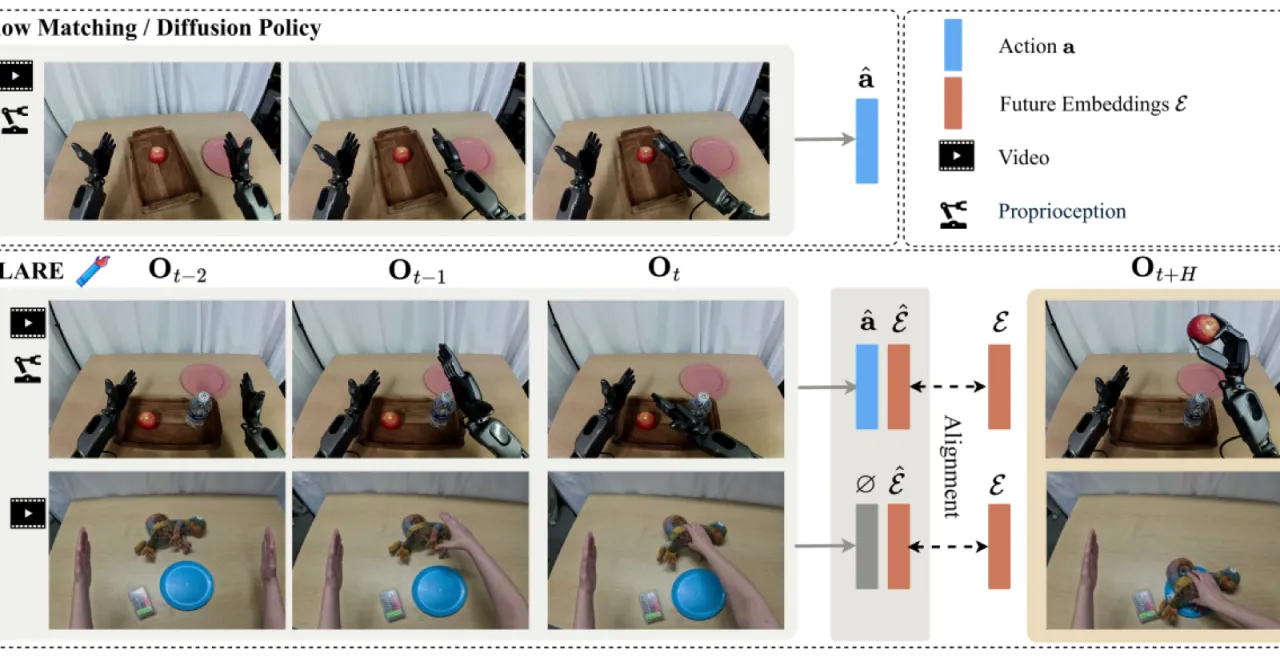
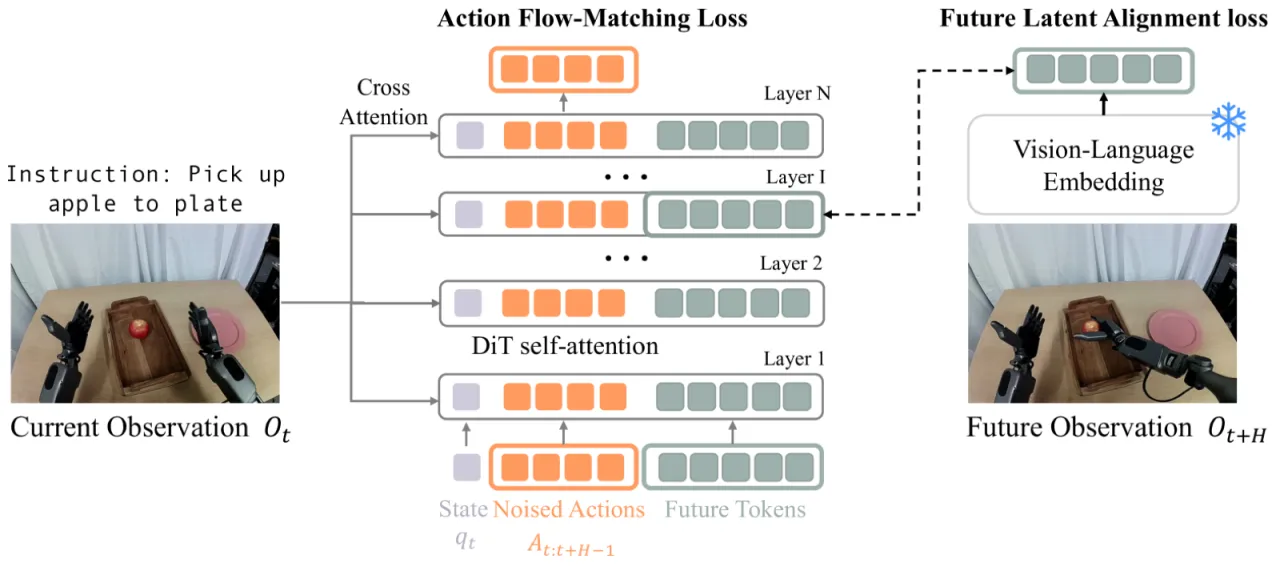
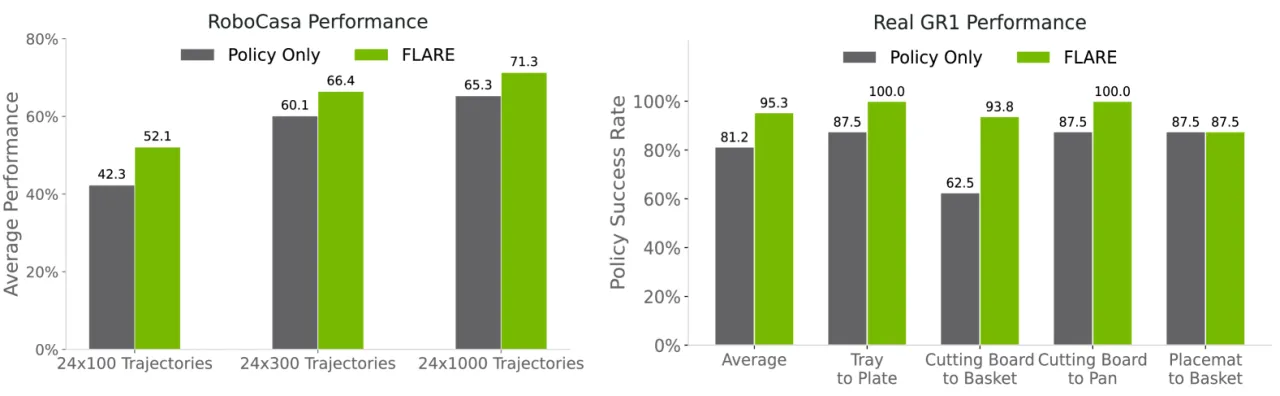
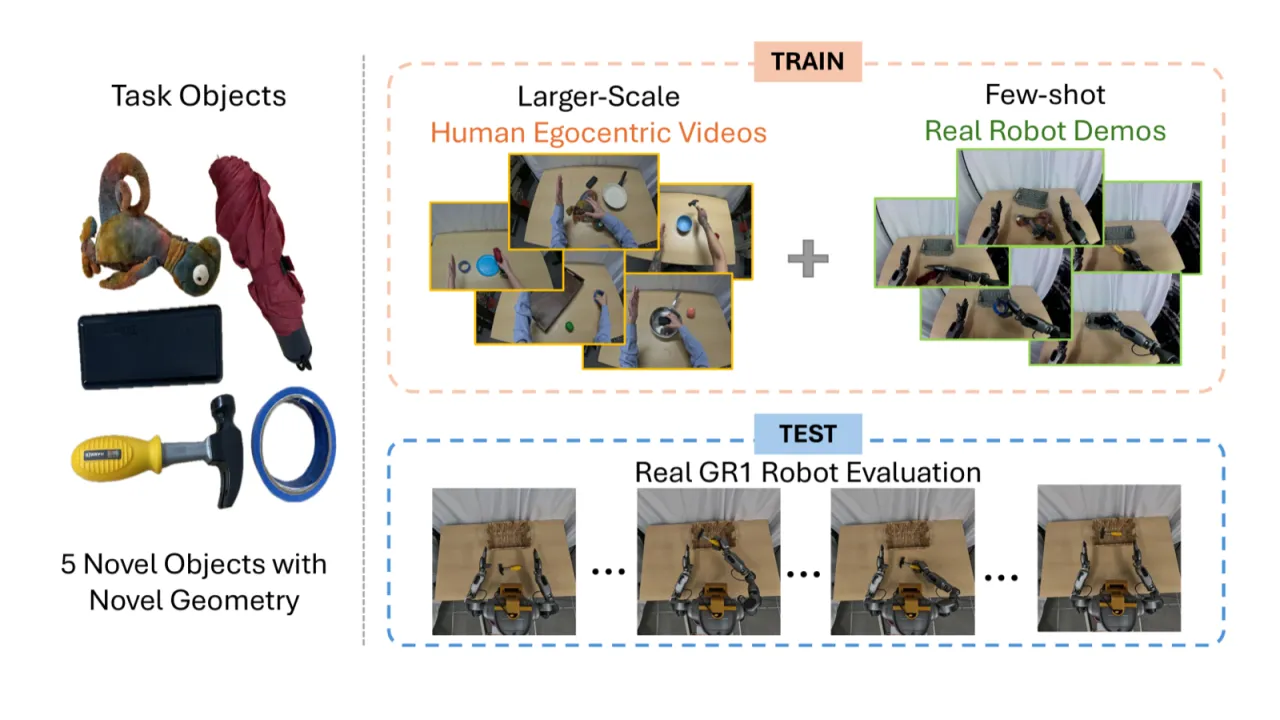
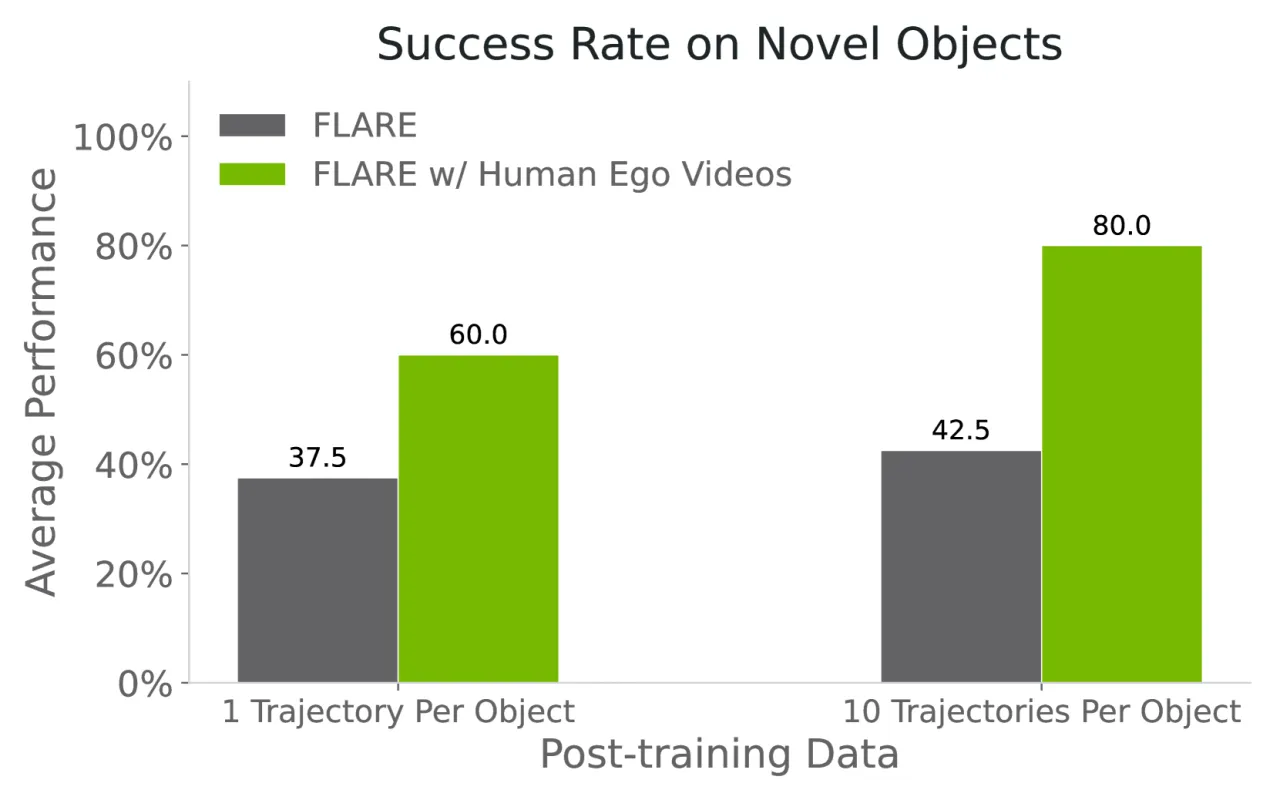
"We show that a surprisingly simple and flexible recipe, fully compatible with existing VLA architectures, can surpass prior VLA policy learning methods by a substantial margin."
图 8–9:左图展示不同 DiT 层 L 对性能的影响——中间层效果最佳,过浅或过深均会下降;右图展示 EMA 系数 ρ = 0.995 时性能最优。损失权重 λ = 0.2 为最佳,Action-Aware Embedding 对比通用 SigLIP2(49.6–50.9%)提升明显(55.0%)。
04 局限性
Note: 以下局限性均来自论文原文的 Limitations 部分(stated by the authors);附带标注 inferred 的为设计层面合理推断。
任务范围局限于拾放操作
论文明确指出:"we focus mainly on imitation learning with pick-and-place tasks on a real humanoid robot. Extending to more complex humanoid tasks that require more fine-grained dexterous manipulation … remains an important direction."细粒度灵巧操作(如工具使用、精密装配)尚未验证。
未集成强化学习
论文将"incorporating reinforcement learning into the training paradigm"列为重要未来方向。目前 FLARE 仅在模仿学习框架下验证,RL 是否能进一步放大世界模型带来的收益尚不清楚。
人类视频数据采集受限(inferred)
人类视频泛化实验依赖头戴式 GoPro 相机在受控环境中录制,视角与光照条件相对固定。论文提及"controlled settings using head-mounted GoPro cameras"。对真实野外场景的泛化能力尚未评估。