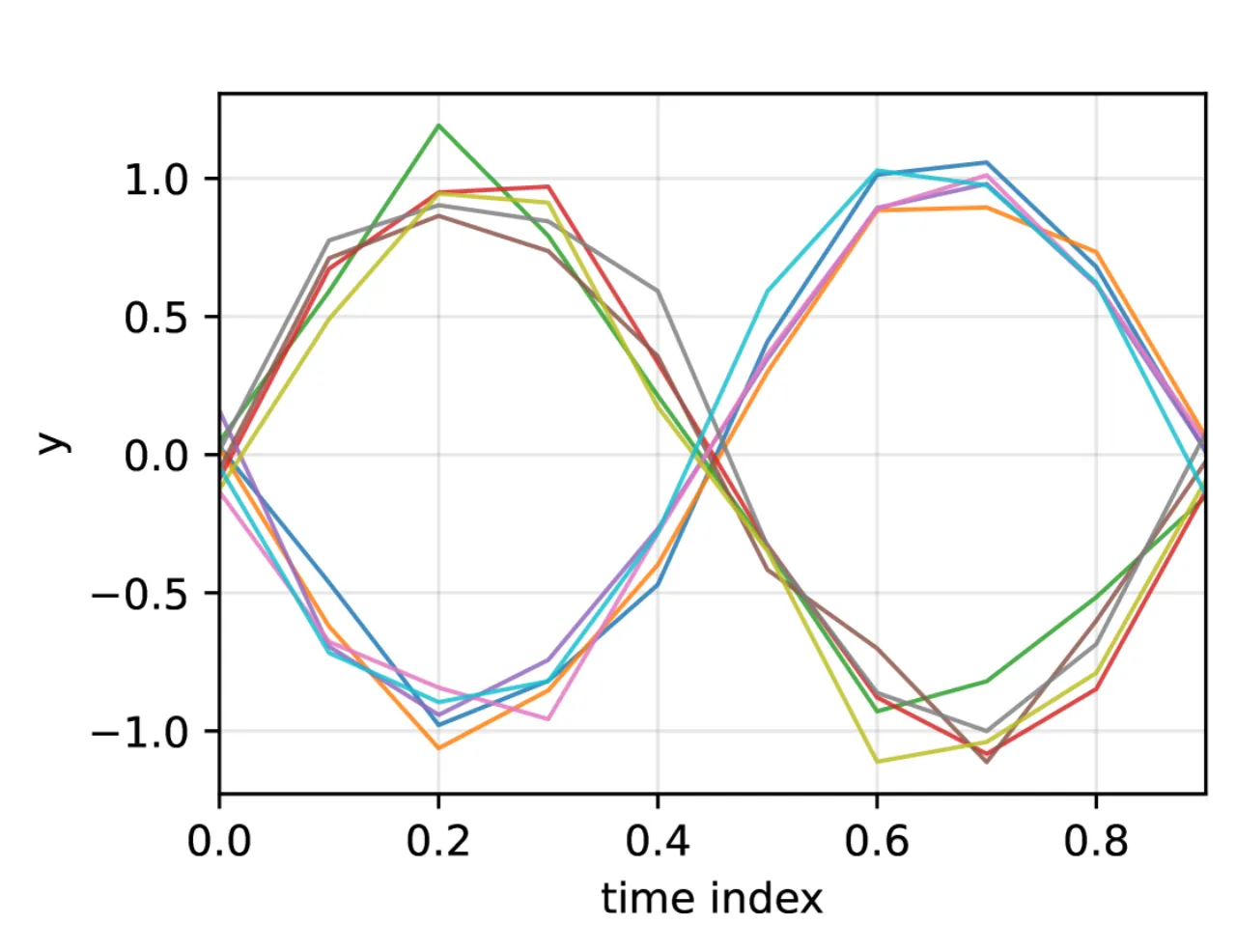
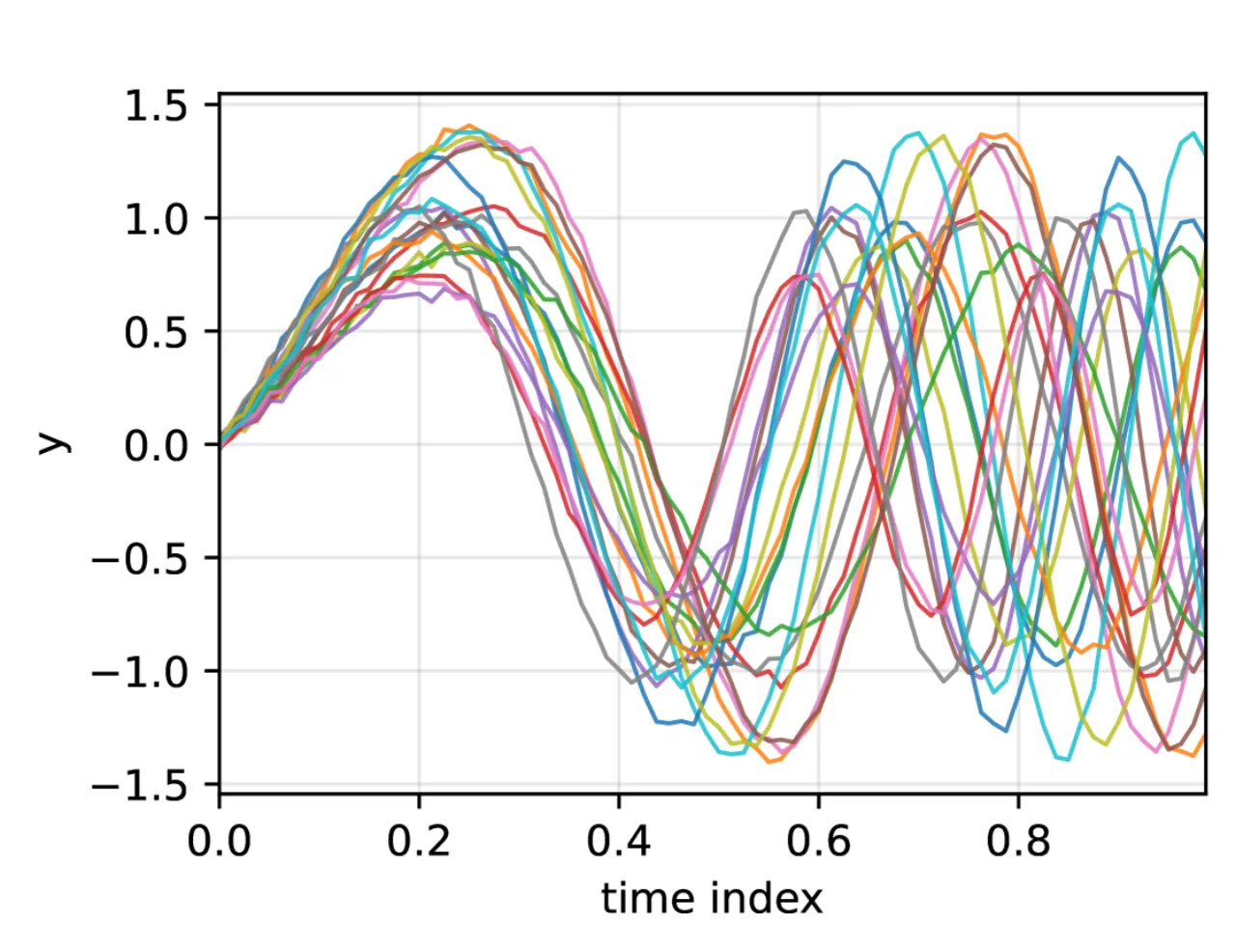
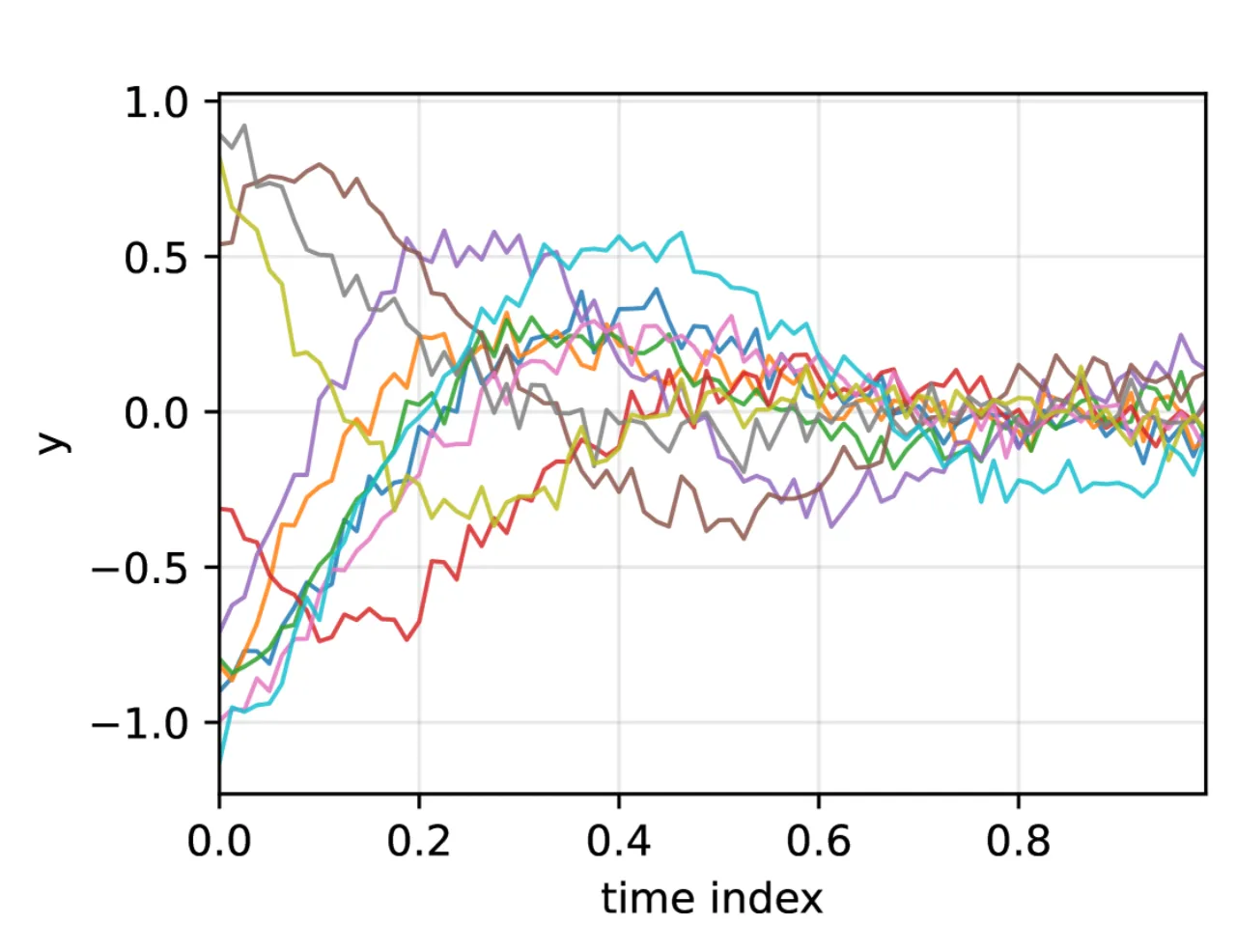
02 方法
FLARE 基于 Fisher–Laplace 框架,将参数后验协方差通过去噪器的 Jacobian 矩阵逐步传播到生成轨迹中,从而精确刻画每条轨迹的认知不确定性,同时通过随机子网络采样保持计算可行性。
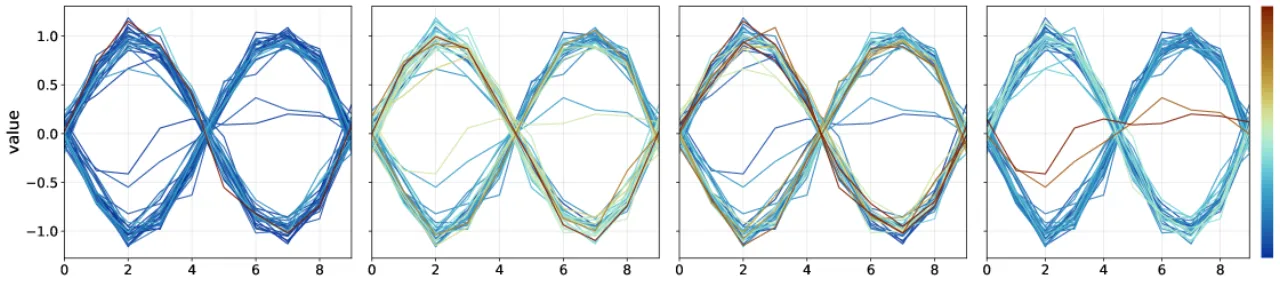
A. Fisher 信息引导的参数不确定性投影
在 Laplace 近似下,参数后验为高斯分布 θ ~ N(θ̂, Σ_θ)。FLARE 通过去噪器在每一步的 Jacobian J_t 将参数空间的不确定性投影到样本空间,得到认知协方差:
Σept-1|t(η) = b²_t · J_t · Σ_θ · J_t⊤
这一公式将认知方差从偶然噪声中显式隔离出来,沿整条反向扩散轨迹产生"认知视角"。
B. 多步认知递推传播
不确定性通过去噪步骤逐层向前递推,形成轨迹级的累积认知协方差:
Σept-1(η) = a²_t · Σept(η) + b²_t · J_t · Σ_θ · J_t⊤
与仅考虑最终步骤的 LLLA 不同,这种递推式传播能捕捉整个去噪链条上每一步的参数敏感性。
C. 随机子网络近似(Randomized Subnetwork Approximation)
完整 Fisher 信息矩阵的计算代价与网络参数量的平方成正比,对大型扩散模型不可行。FLARE 的解决方案:
- 从全部网络层中均匀随机采样 m 个参数;
- 将 GGN(Generalized Gauss-Newton)矩阵限制在所选坐标上;
- 保留全网络的敏感性结构,同时大幅降低计算成本;
- 避免了 LLLA 仅限最后一层所引入的"结构性偏差"。
Theorem 1 证明了该随机近似的近似误差以 O(1/√m) 速率收敛,随参数采样量 m 的增加而降低,提供了严格的理论保证。