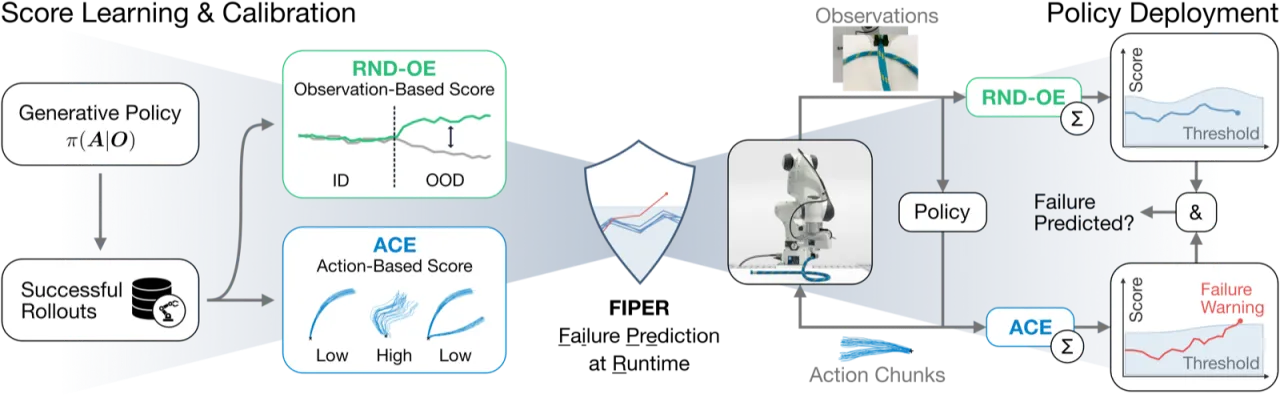
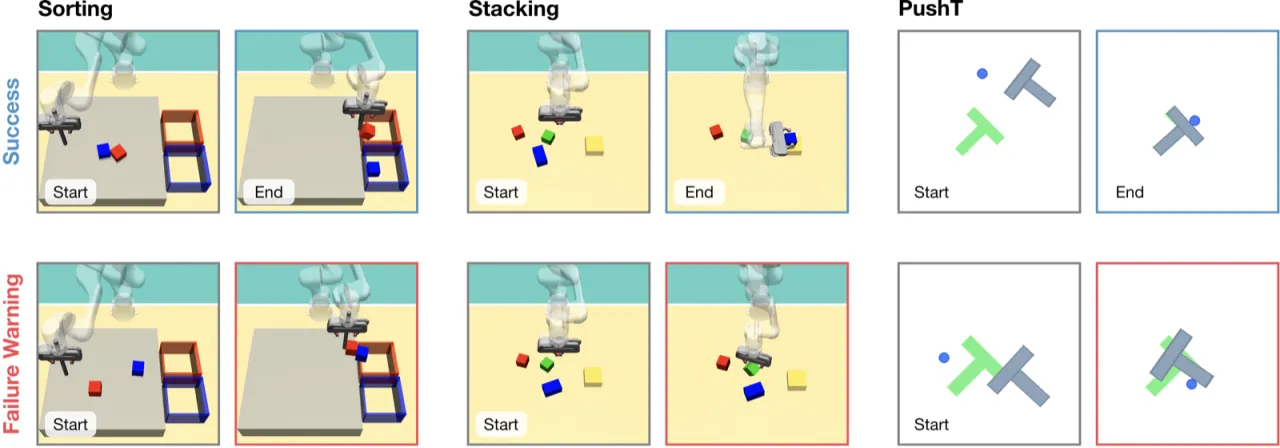
"Distribution shifts from unseen environments or compounding action errors can still cause unpredictable and unsafe behavior, leading to task failure. Early failure prediction during runtime is therefore essential for deploying robots in human-centered and safety-critical environments."
FIPER(Failure Prediction at Runtime for generative IL policies)由两个互补子模块组成,分别从观测侧和动作侧检测失效前兆,通过逻辑"与"(AND)组合两者的警告信号,并用 conformal prediction 在少量成功 rollout 上标定各自阈值,实现对误报概率的统计保证。
RND-OE:基于随机网络蒸馏的 OOD 观测检测
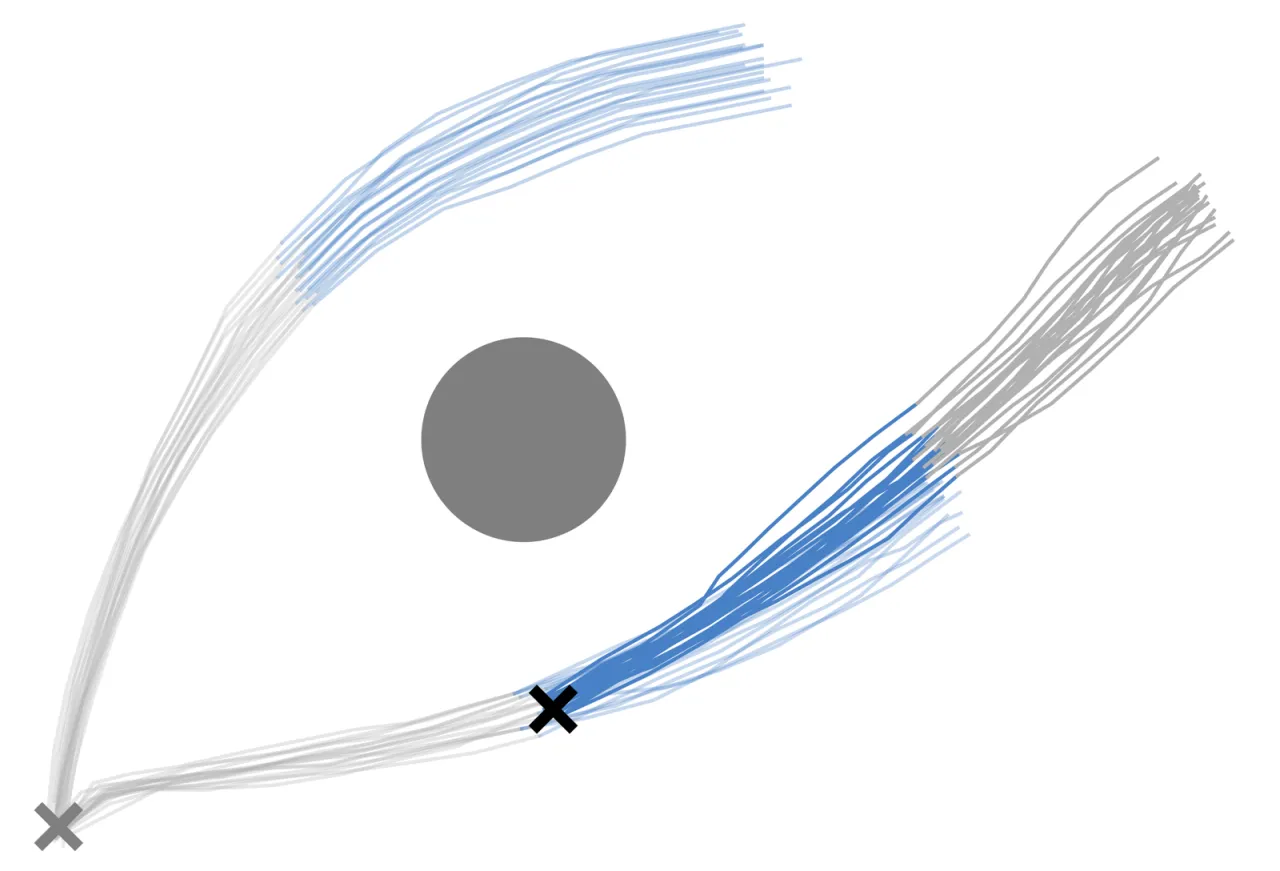
Random Network Distillation (RND) 最初用于强化学习中的探索激励。FIPER 将其应用于策略的观测嵌入空间(observation embedding space),利用预训练好的策略编码器 h(·)(如 ResNet-18)提取嵌入,再训练一个预测网络 fθ(·) 去拟合随机目标网络 g(·) 在 ID 成功数据上的输出。OOD 样本会使两个网络的输出产生较大偏差,RND-OE 评分 sRND(Ot) = ‖fθ(Ot) − g(Ot)‖² 即量化这一差异。将该评分在大小为 wO 的滑动窗口上聚合,得到观测侧失效预测分 ηO。