01 动机
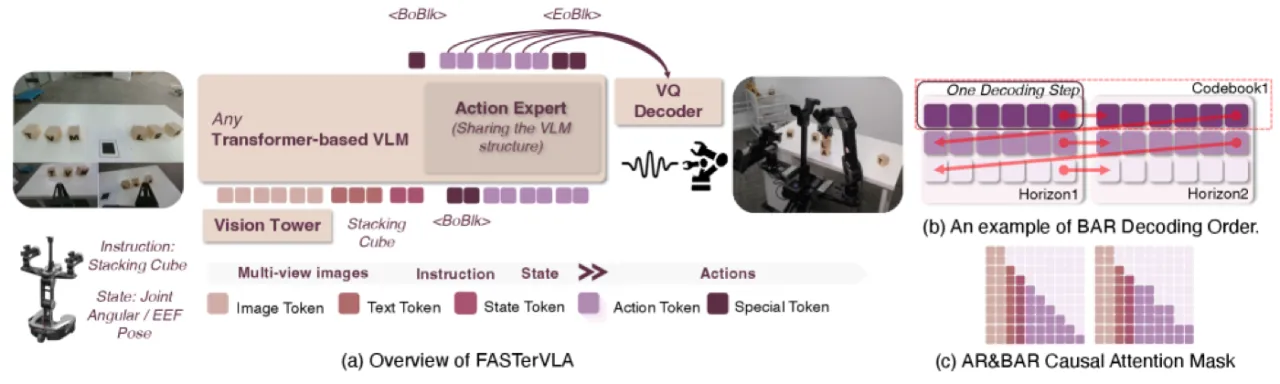
自回归 VLA 面临一个核心矛盾:为了加快推理速度,需要将连续动作序列压缩成尽可能少的 token;但过度压缩会丢失精细的动作细节,导致任务失败。
"The key challenge lies in the reconstruction fidelity vs. inference efficiency trade-off: high compression reduces inference latency but degrades action reconstruction quality, while low compression preserves fidelity but increases token count and slows inference."
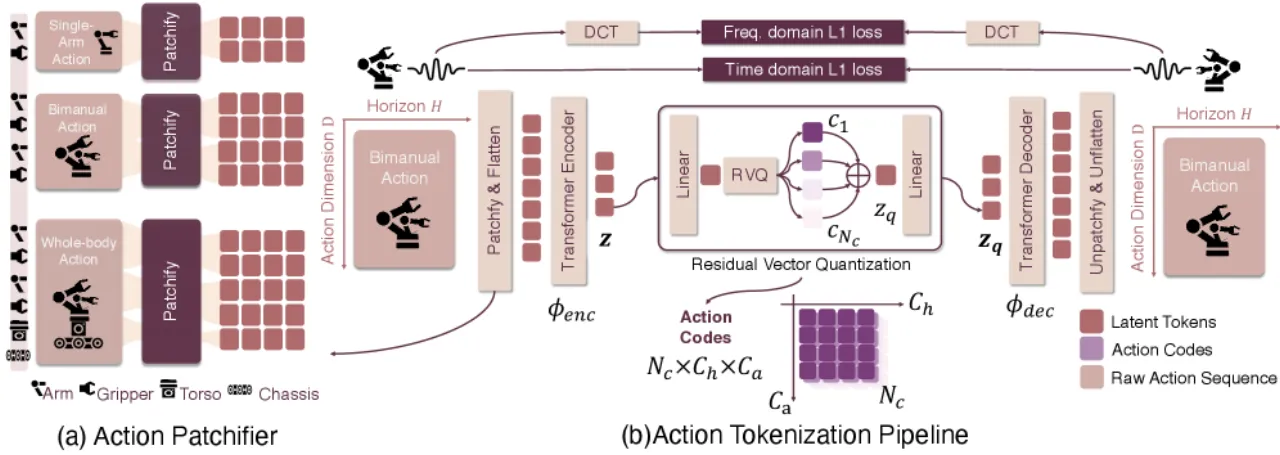
现有方法(如 FAST)将动作块经 DCT 变换后量化为离散 token,虽然加快了推理速度,但存在两大缺陷: (1)codebook 利用率低(FAST 仅使用了 48.4% 的 codebook),导致大量表征空间浪费; (2)固定的 DCT 频率截断无法自适应地保留各维度动作信号中最关键的频率成分。
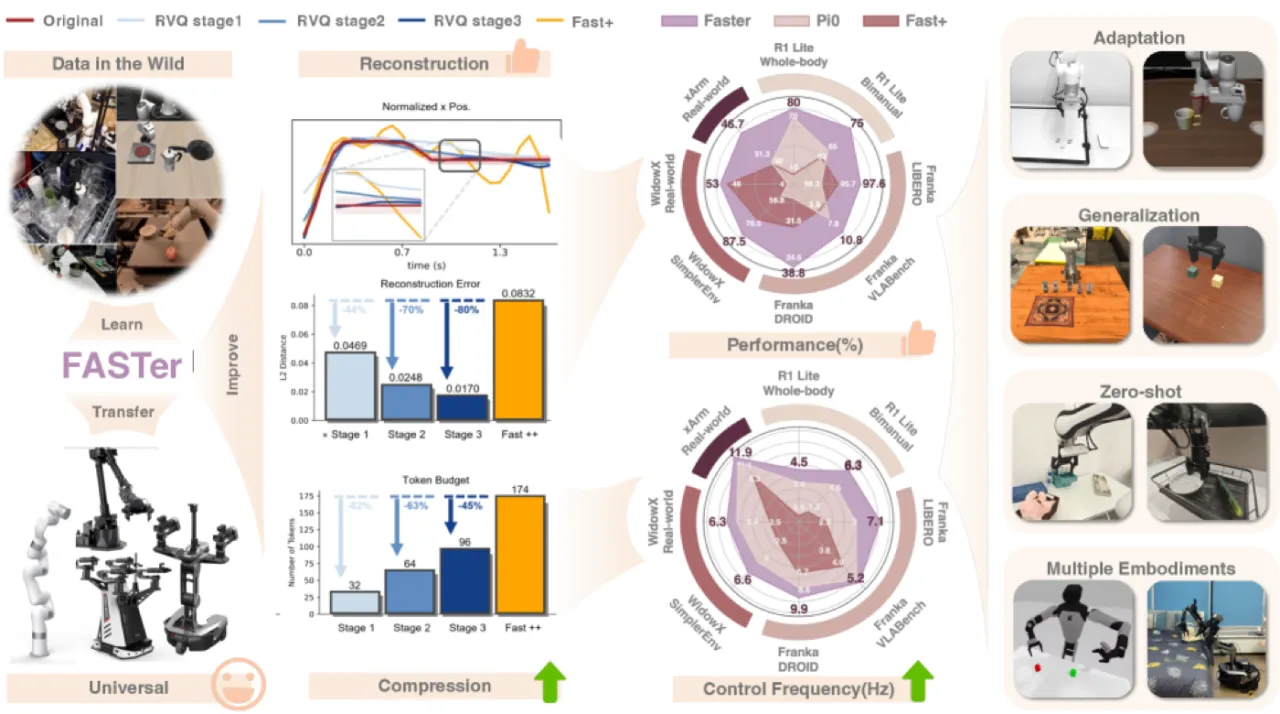
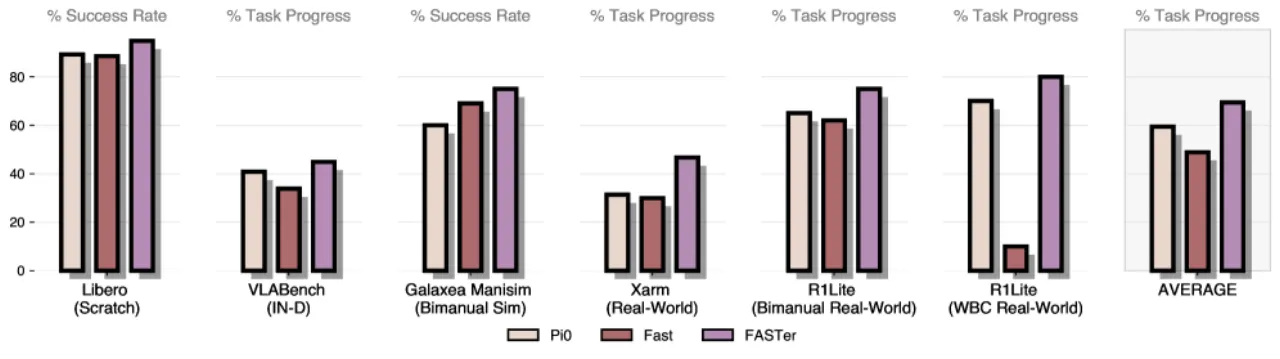
97.9%LIBERO 平均成功率(↑3.7 pp vs. π0 FAST-D)
87.9%Simpler-Bridge 平均成功率(↑11.4 pp vs. π0 FAST-R)
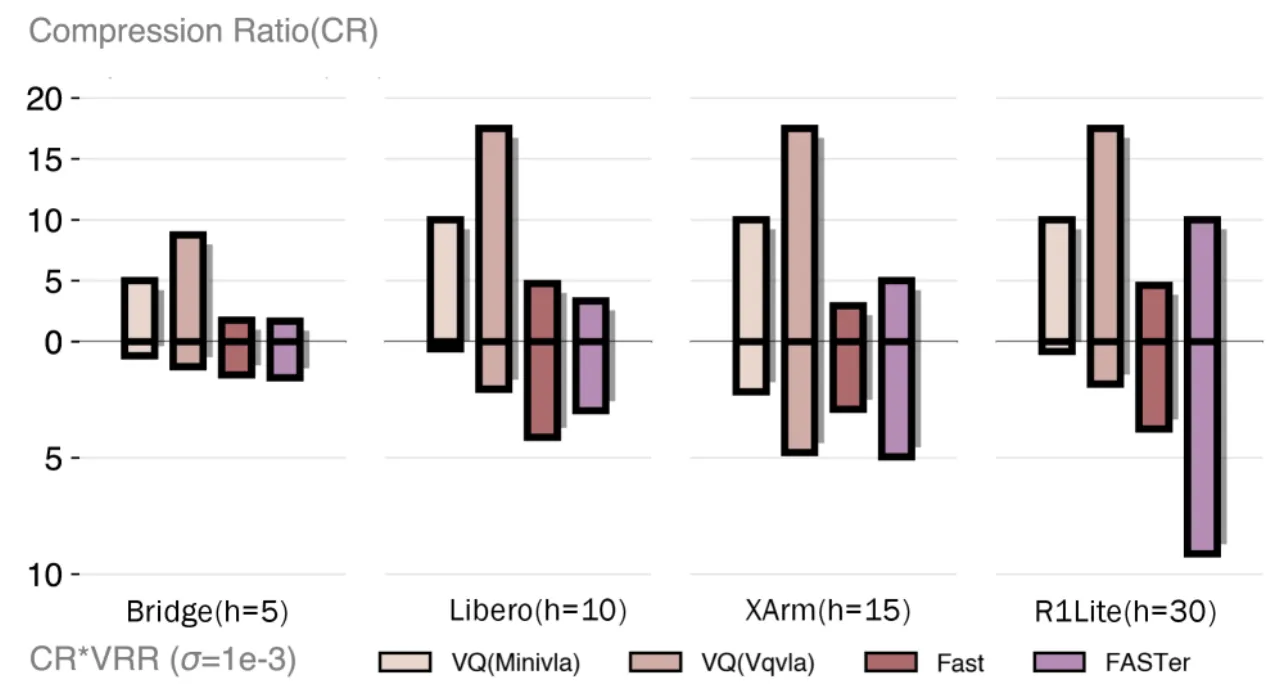
112 ms单臂推理延迟(vs. FAST 197–556 ms)
100%FASTerVQ codebook 利用率(vs. FAST 48.4%)