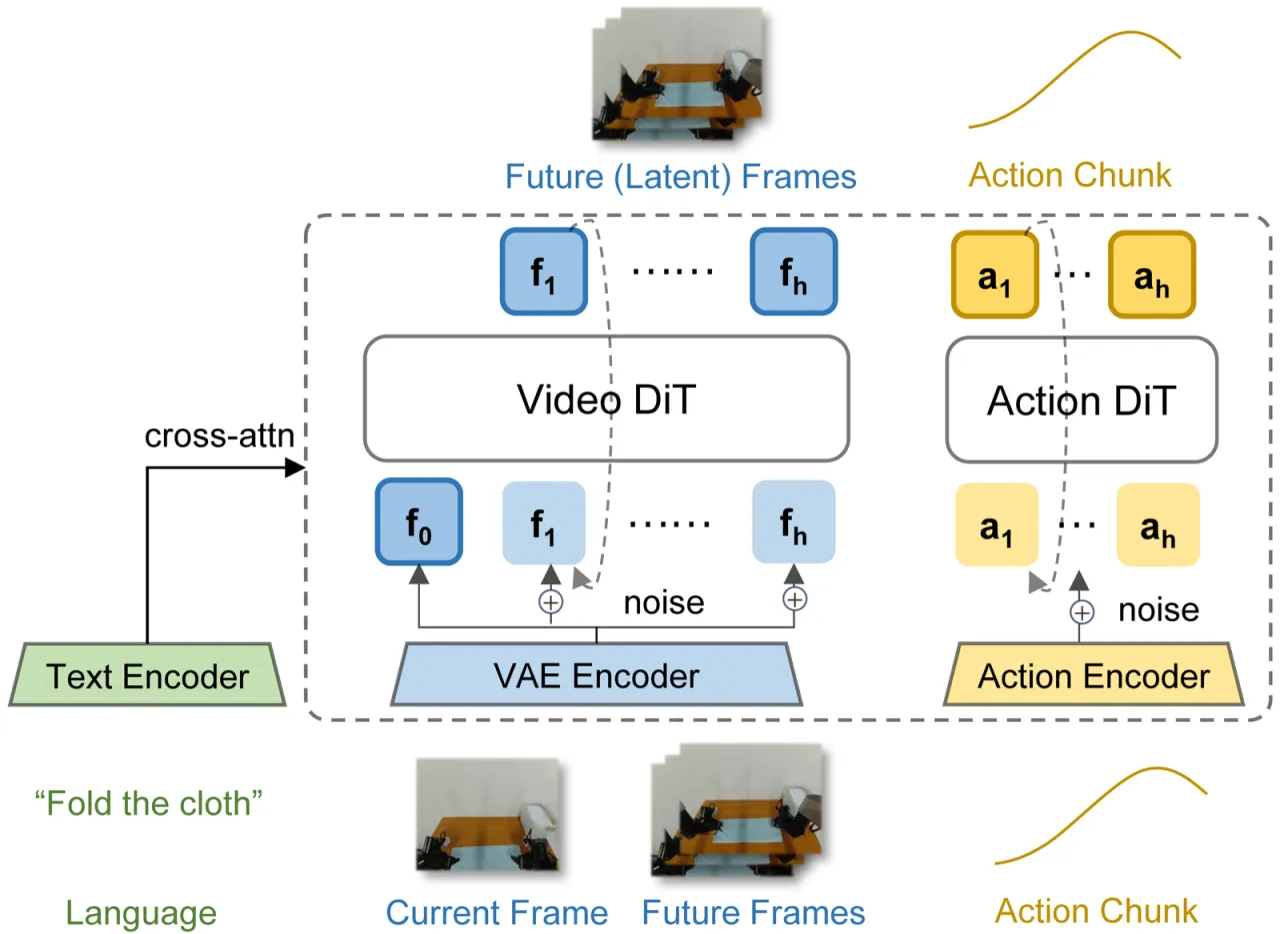
01 动机
现有 World Action Models 把训练时的视频预测目标与推理时的未来帧生成捆绑在一起,无法区分二者各自的贡献。推理时的迭代去噪带来极高延迟,阻碍了实际部署。
"It remains unclear whether explicit future imagination is actually necessary for strong action performance... existing WAM systems typically entangle these two factors, making it difficult to determine which one is actually responsible for the observed gains."
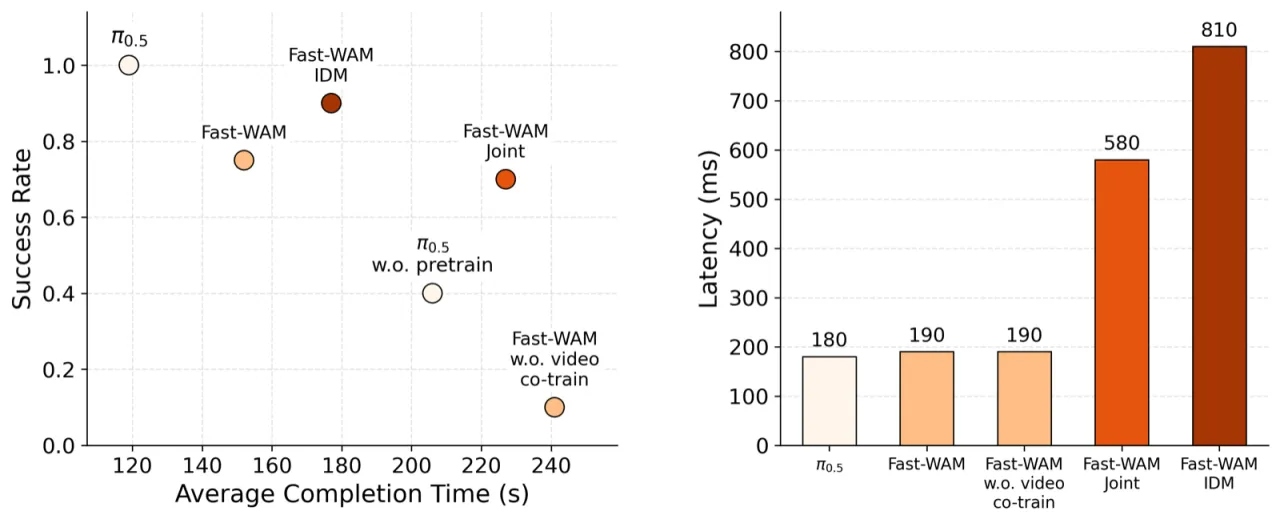
190msFast-WAM 推理延迟
4×+相比 imagine-then-execute 的速度提升
91.8%RoboTwin 2.0 平均成功率(无 embodied pretraining)
97.6%LIBERO 平均成功率(无 embodied pretraining)
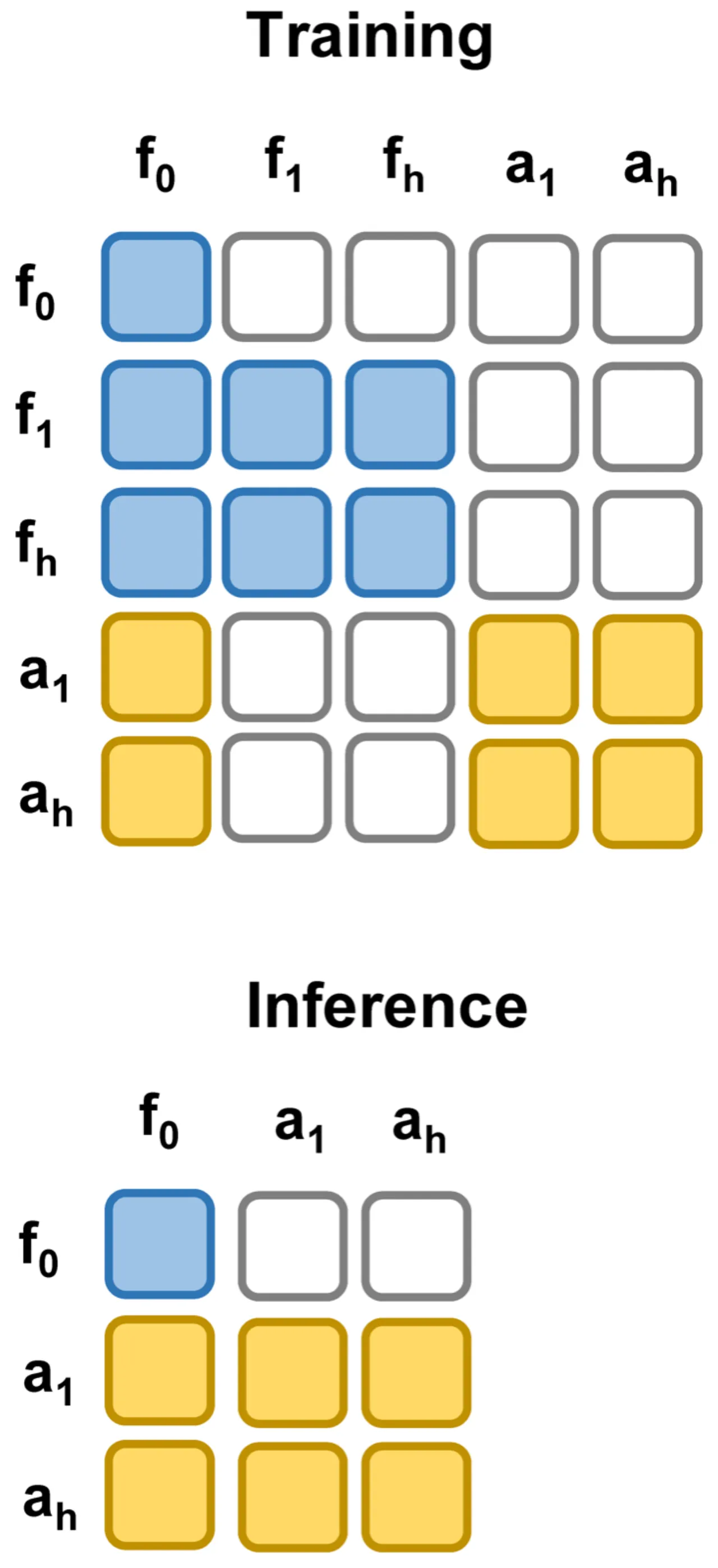
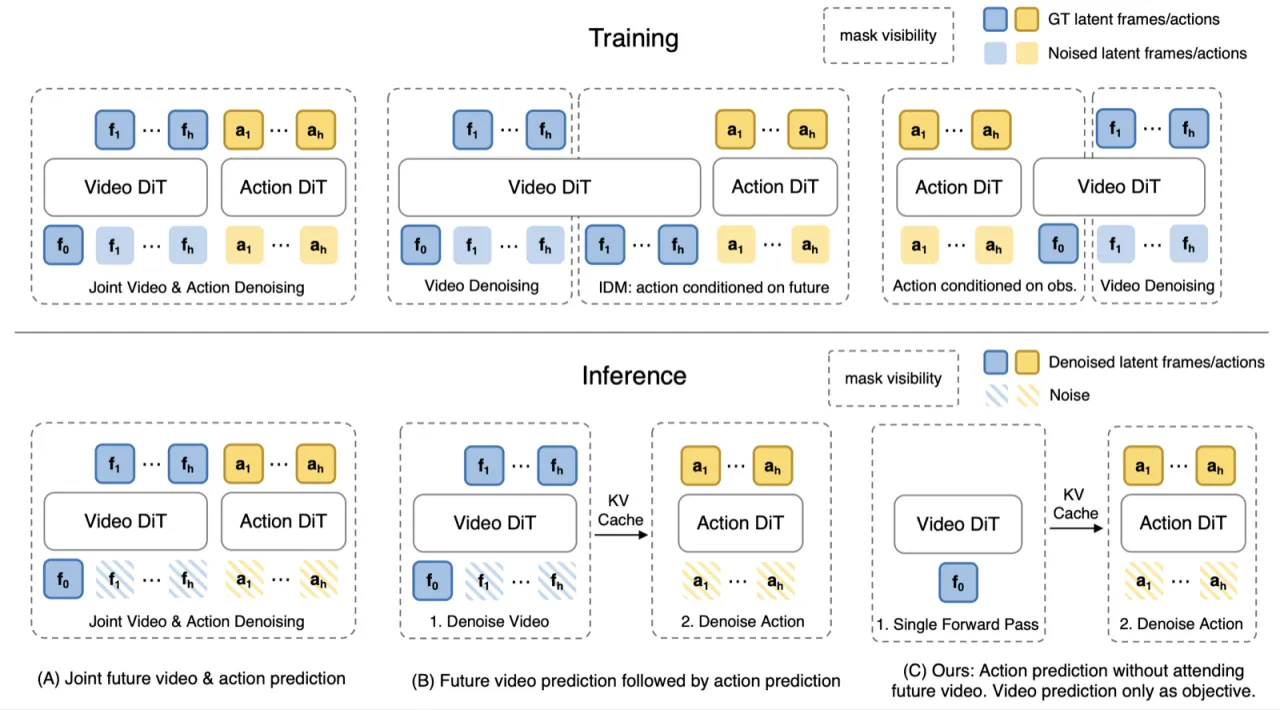
研究的核心假设是:视频预测在 WAM 中的主要价值来自训练时改善世界表征,而非推理时提供未来观测。为验证这一假设,作者构建了受控变体——Fast-WAM-Joint、Fast-WAM-IDM 以及移除视频联合训练的消融版本——进行系统对比。