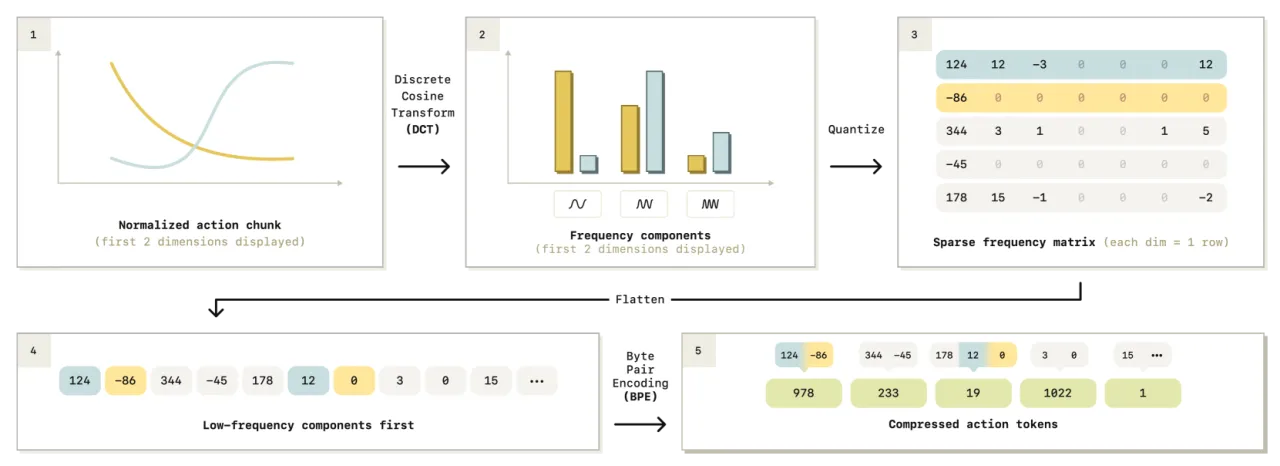
01 动机
现有 VLA 模型(如 OpenVLA)使用朴素的 per-dimension per-timestep binning 对连续动作离散化。当机器人控制频率升高(例如折叠衣物需要 50 Hz)或任务需要精细灵巧操作时,这种方案产生数百个高度相关 token,使得自回归 next-token prediction 形同虚设——模型退化为简单地复制最近一个动作 token。
"Highly correlated action tokens diminish the effectiveness of the next token prediction objective used in autoregressive VLAs."
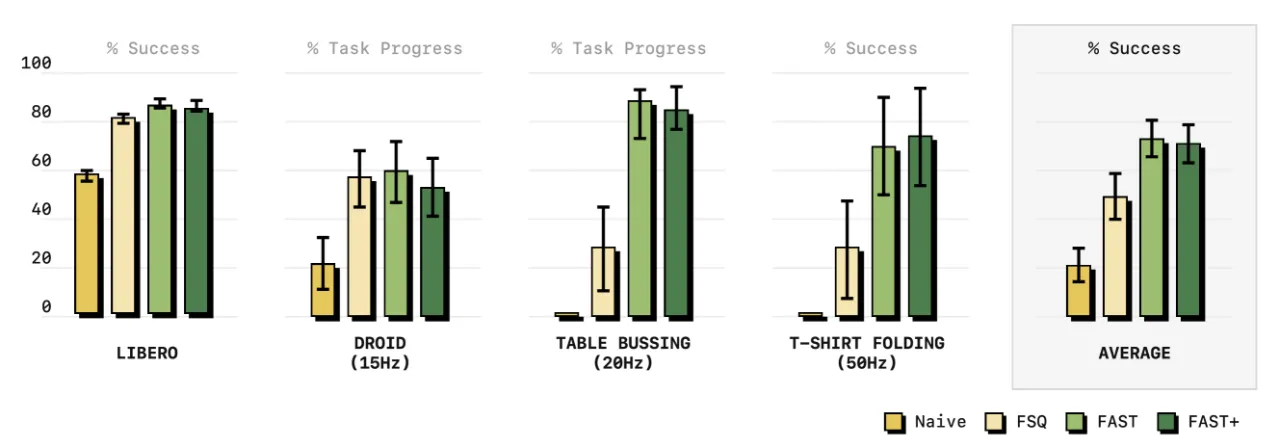
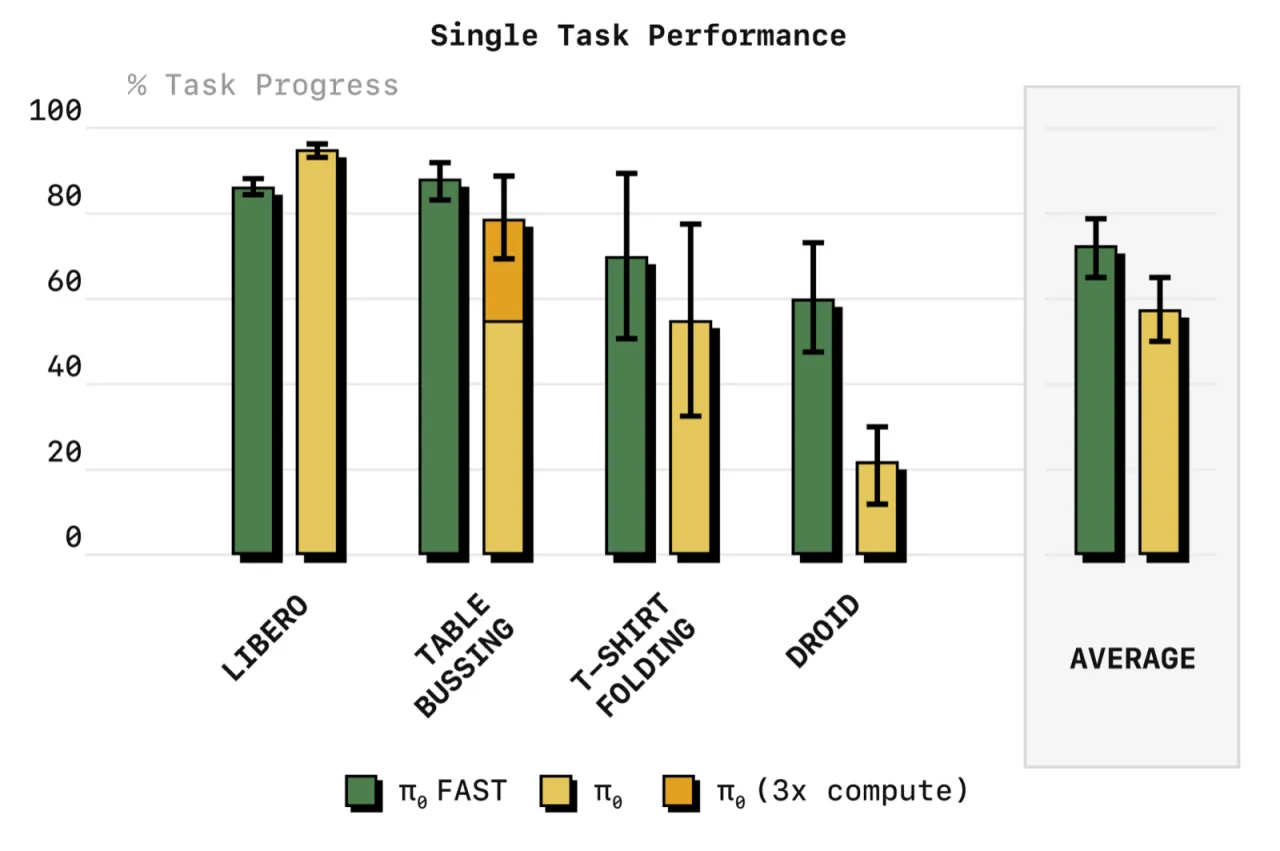
13.2×Shirt Fold (50 Hz) 上的 token 压缩率
5×相对扩散基线训练提速倍数
1MFAST+ 预训练所用真实机器人轨迹数
5 Hz→50 HzFAST 适用的控制频率范围
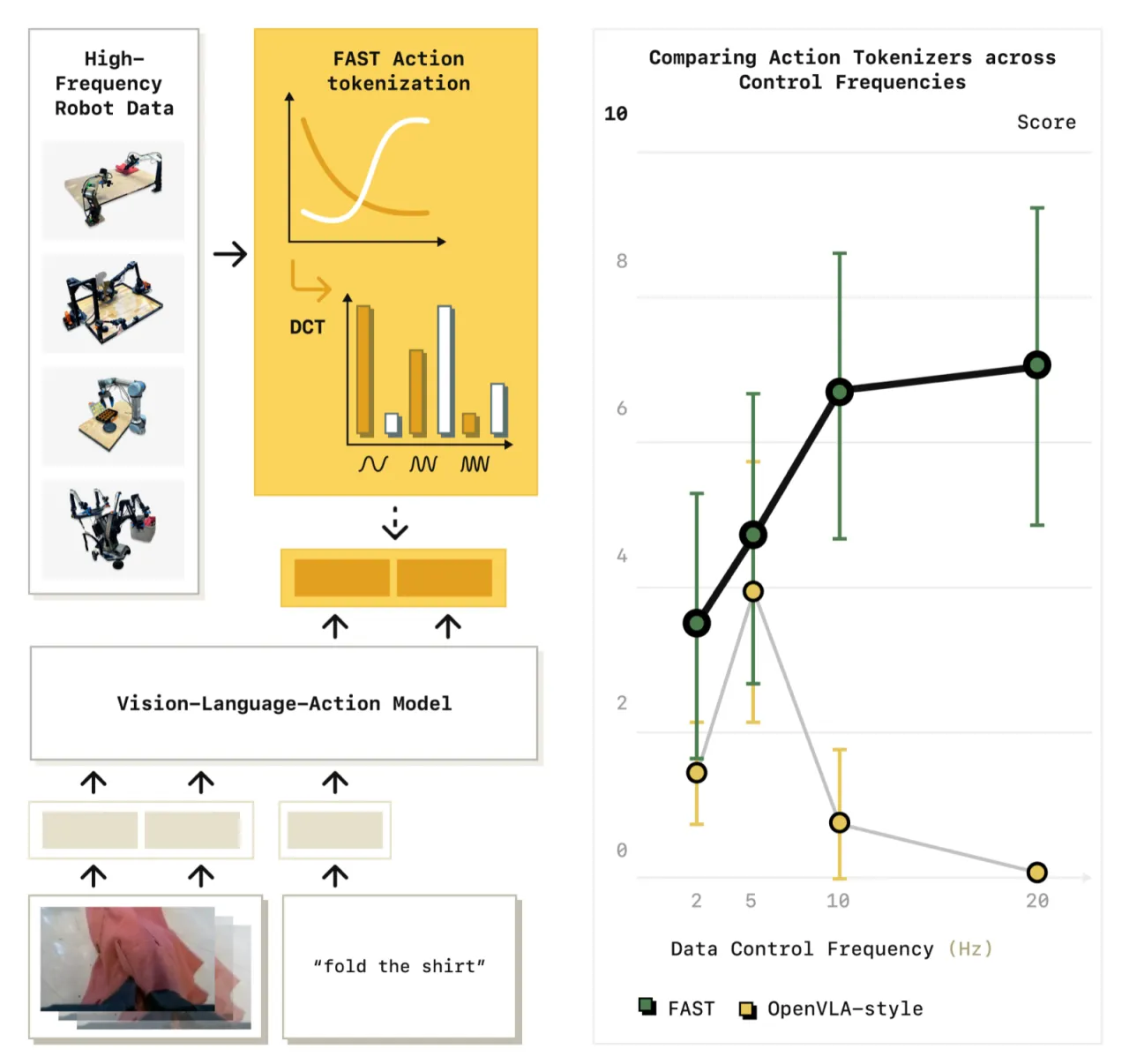
案例研究:采样率对 binning 的致命影响
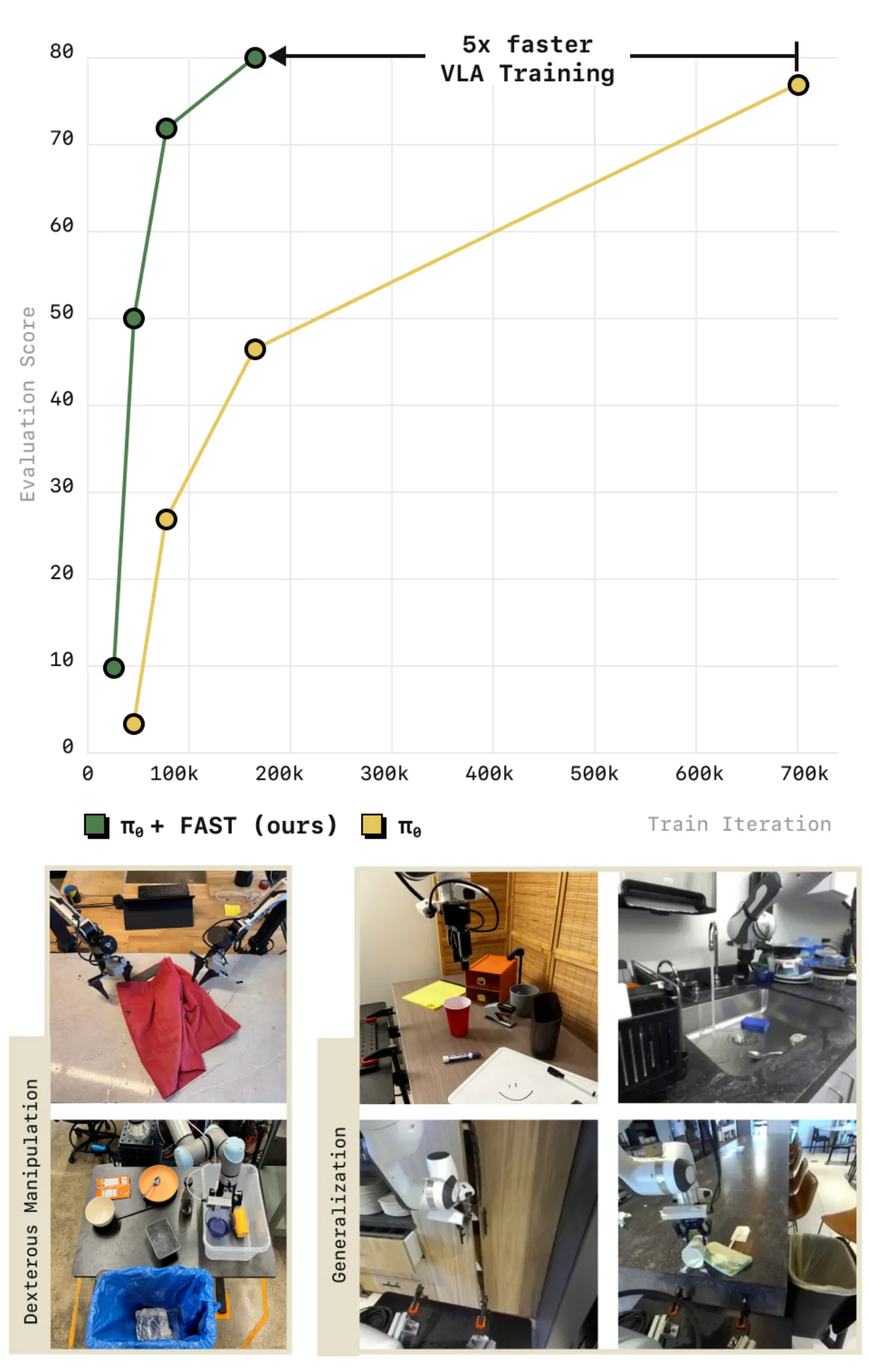
研究者在一个简单的 table-top manipulation 任务上系统研究了采样率对不同分词策略的影响。随着控制频率升高,使用 binning 分词训练的策略"produce increasingly poor predictions as we increase the sampling frequency",而基于 DCT 的 FAST 在各频率下均保持稳定表现。