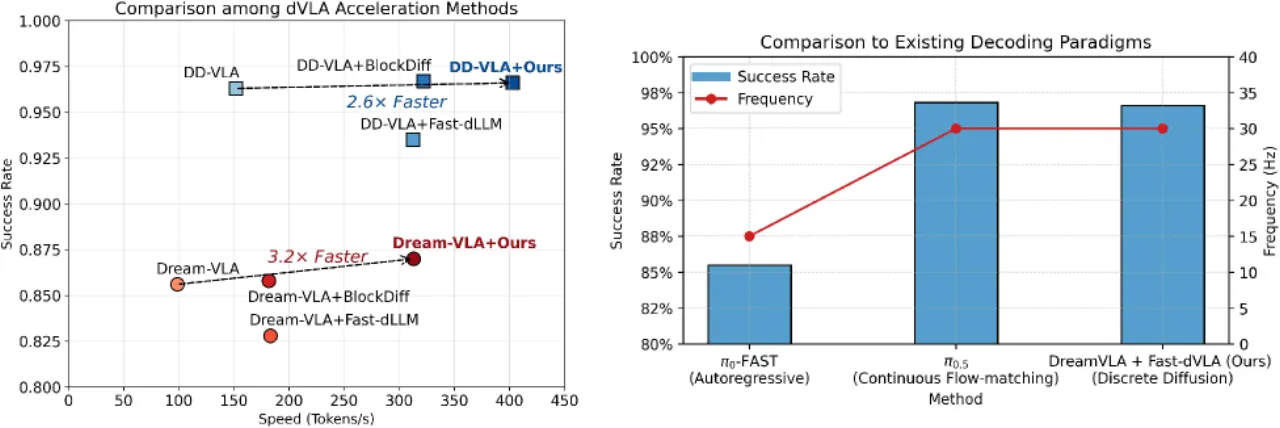
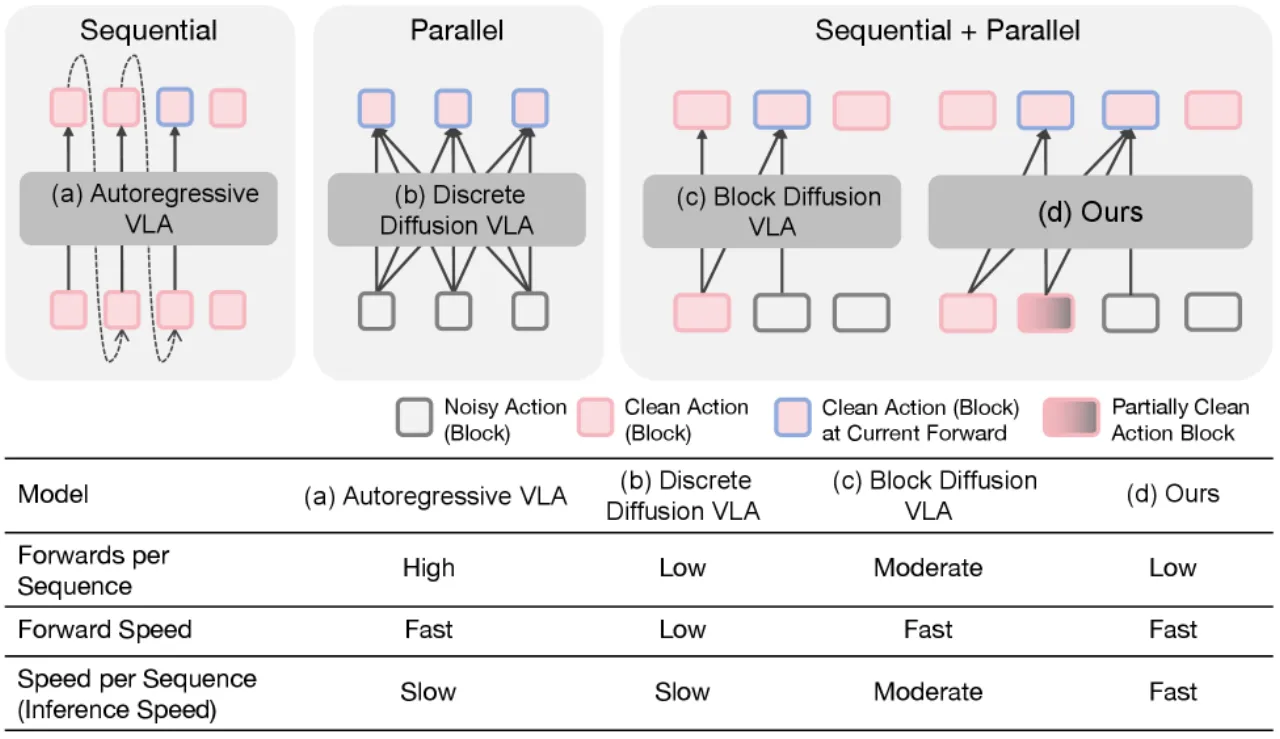
02 MethodFast-dVLA 的核心是将全序列双向注意力替换为分块因果注意力 (block-wise causal attention),并结合扩散强迫 (diffusion forcing)实现块间并行解码。训练时采用非对称蒸馏从已微调的双向 dVLA 高效迁移能力;推理时设计流水线并行调度算法,平衡解码可靠性与吞吐量。
3.1 隐式块级自回归趋势的发现
通过可视化 Dream-VLA 在不同去噪步骤中各 token 位置的解码概率(Figure 3),作者发现:尽管 dVLA 使用双向注意力,其解码过程在宏观上仍呈现从左到右的块级自回归模式 ——时间序列中靠前的动作块倾向于在更早的去噪迭代中被解码。这一观察源于两个原因:①dVLA 骨干初始化自自回归 VLM,天然保留了自回归特性;②不同时间步的动作存在固有的时序依赖。该发现表明,经过微调的双向 dVLA 可被直接"强制"遵循分块扩散解码方式 。
3.2 分块注意力与 KV 缓存复用
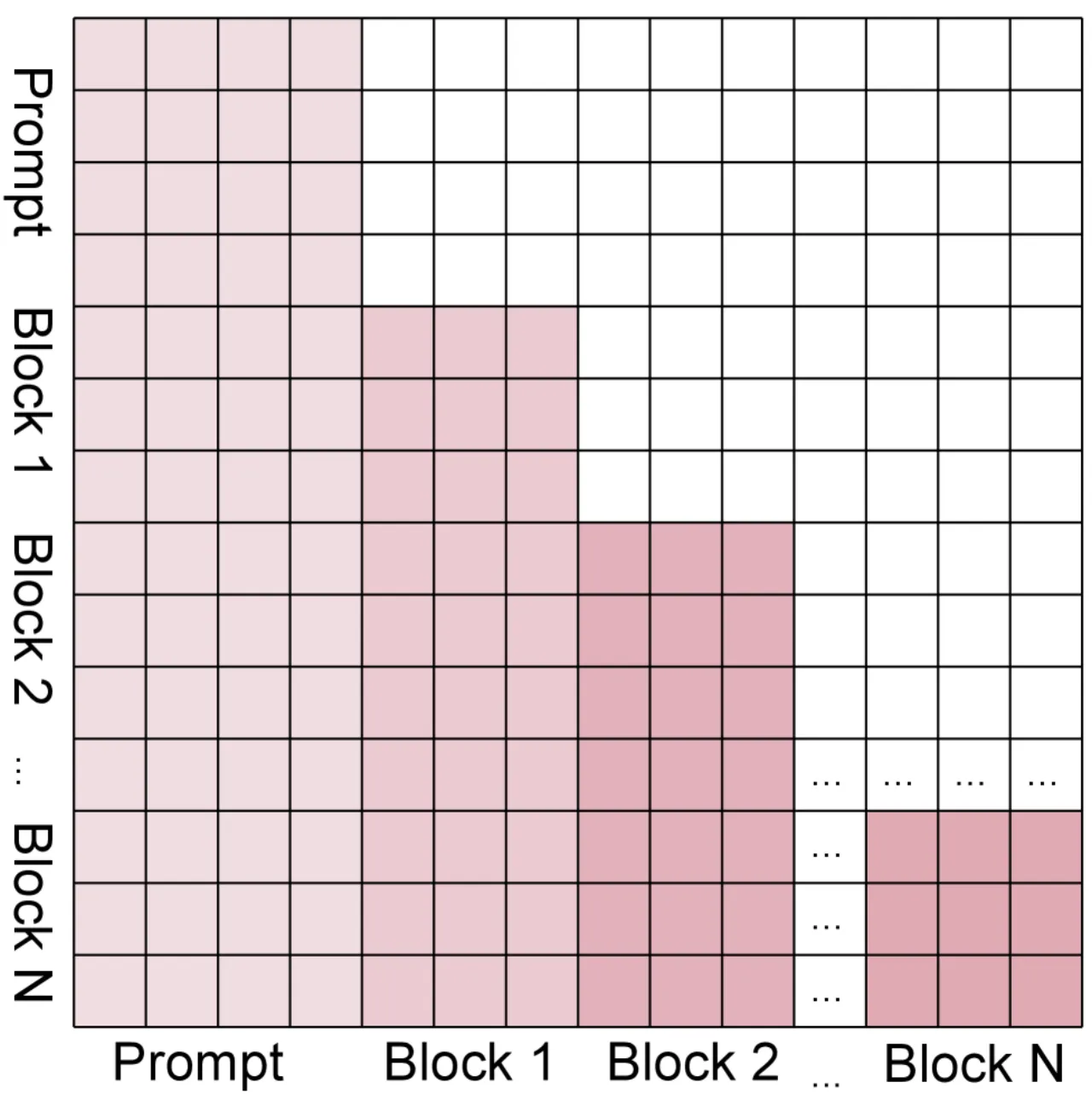
将长度为 L 的动作 token 序列划分为 N 个等大小的块,每个块仅能 attend 到其之前所有块的 token(因果限制),同一块内 token 可互相 attend(块内双向)。一旦某块解码完成,其 KV 状态即固定不变 ,后续解码步骤可直接复用缓存的 KV,无需重新计算,彻底解决了双向注意力下 KV 随去噪步变化的问题(Figure 4b 验证了缓存相似度接近 1.0)。
为实现块间并行解码,论文借鉴扩散强迫思想,对不同块赋予单调递增的噪声水平(t₁ < t₂ < ⋯ < tₙ):靠前的块噪声更少(信息更完整),靠后的块仍高度遮蔽,从而允许模型在精化前序块的同时并发去噪后续块,实现块间并行而不损害时序一致性。
3.3 非对称蒸馏(Asymmetric Distillation)
直接从头训练代价高昂。论文提出从已任务微调的双向 dVLA(教师)蒸馏 Fast-dVLA(学生):教师以全局视角 (bidirectional attention,看到所有块)预测目标,学生以块因果视角 (causal block attention,仅看到前缀块)逼近教师输出,二者结构共享但注意力模式不同——这种"不对称"使蒸馏损失 ℒ_AD 能高效传递教师的整体规划能力。实验显示,ℒ_AD 仅需约 2,000 步 即可收敛,是从头训练所需步骤的约 1/10(Figure 8)。蒸馏采用 LoRA(rank=32),仅训练 LoRA 分支以保留骨干的视觉语言预训练知识。
3.4 流水线并行解码(Pipelined Parallel Decoding)
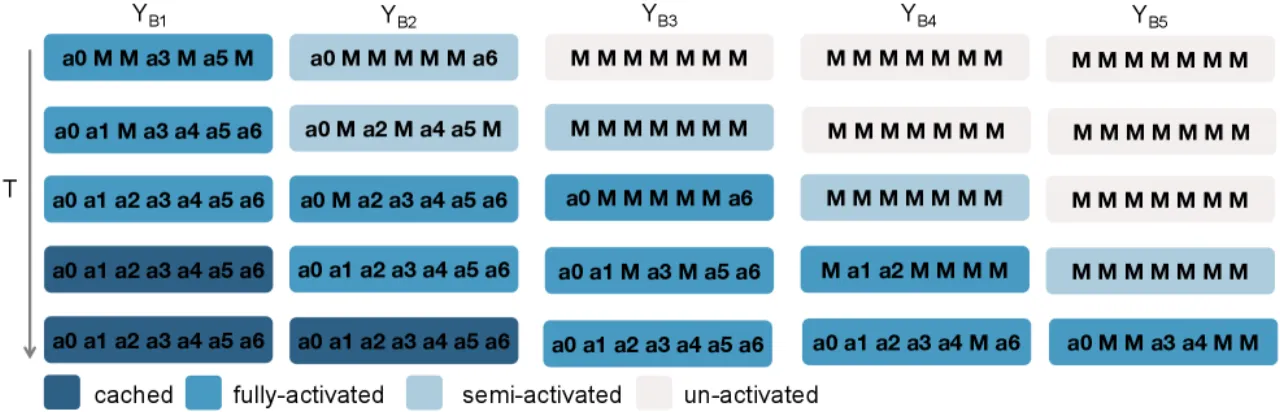
推理时维护一条动态增长的块流水线(Figure 6),区分"半激活"与"全激活"两种状态:当前一块的解码完成比例超过阈值 τ_add 时,新块被引入为半激活状态;当前一块完成比例超过 τ_act 时,新块升为全激活状态。全激活块采用置信度自适应的激进解码 策略(按置信度排名,每步至少解码 ⌊剩余 token/n⌋ 个),兼顾吞吐与可靠性。
图 6 Fast-dVLA 流水线并行解码示意。 各列代表一个动作块,各行代表一个解码时步 T(从下到上)。深色=已缓存,蓝色=全激活,浅色=半激活,白色=未激活。新块在前驱完成比例超 τ_add = 2/7 时引入,在超 τ_act = 4/7 时升级为全激活。块间并行推进使整体 KV 缓存利用率最大化。