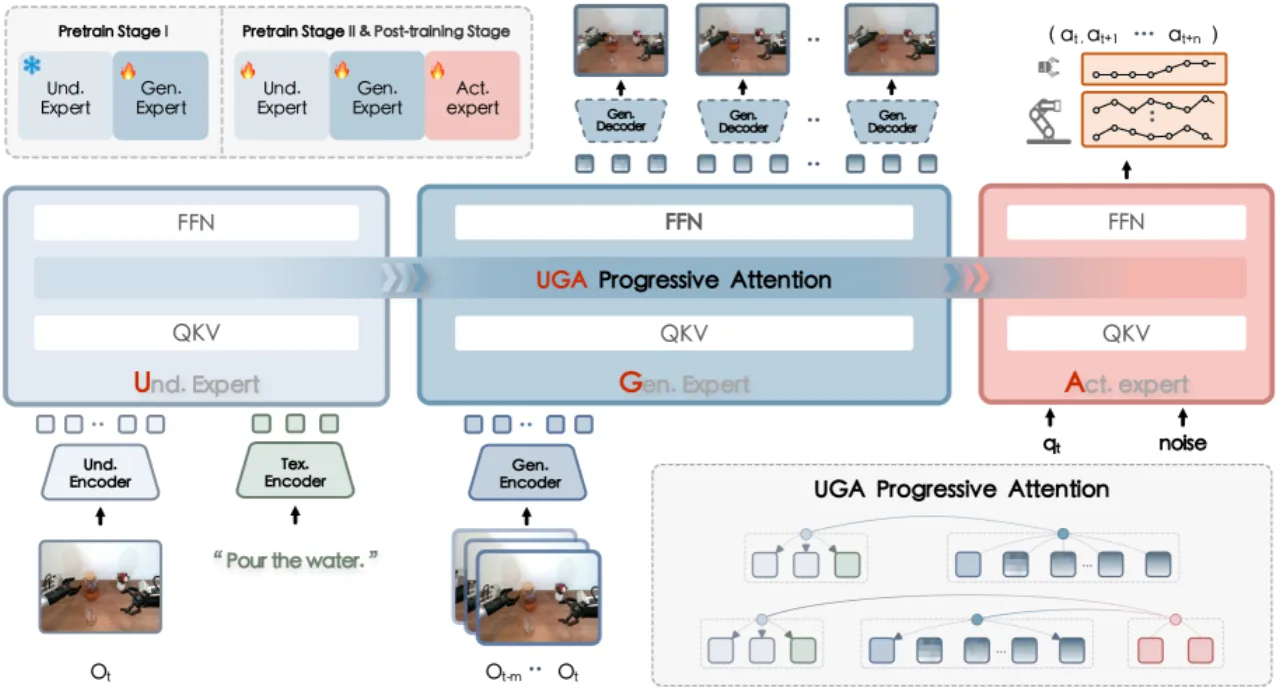
01 动机
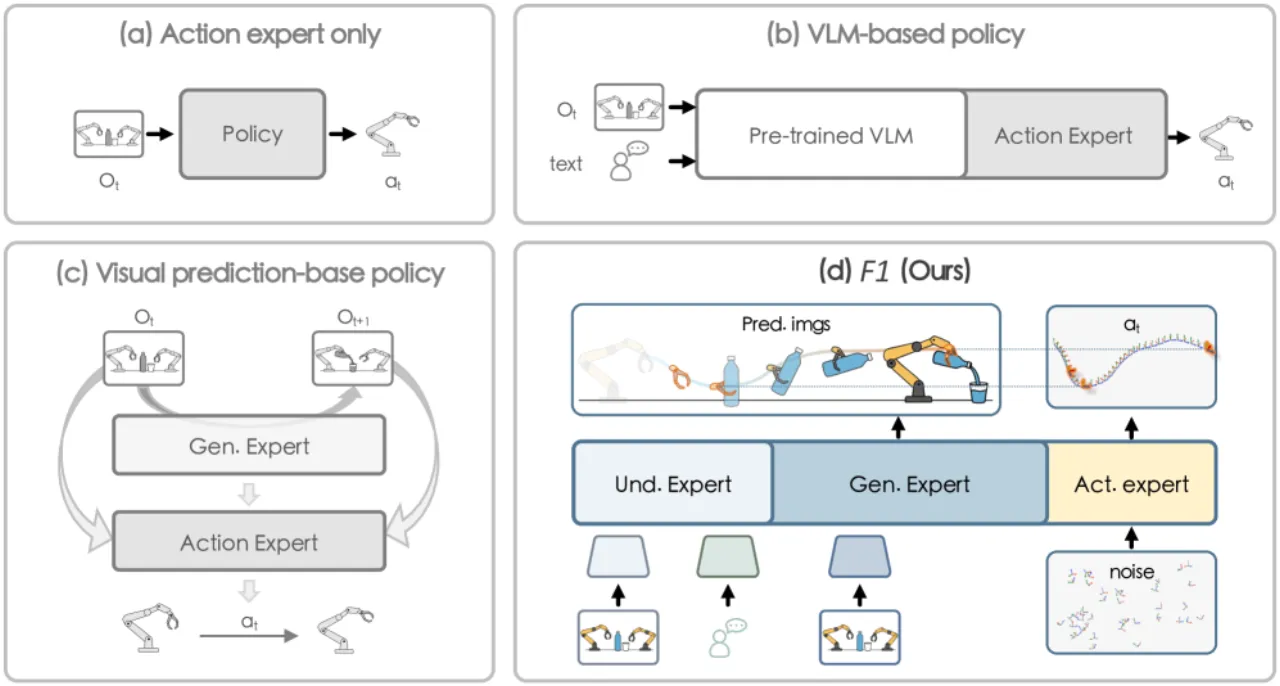
现有 VLA 模型主要依赖"被动的状态到动作映射(reactive state-to-action mappings)",缺乏对时间演化的建模,在动态场景和长时序任务中表现脆弱。F₁ 提出将视觉前瞻生成引入决策循环,让模型在执行动作前先"想象"未来的视觉状态,从而生成更具前瞻性的动作序列。
"Existing approaches primarily rely on reactive state-to-action mappings, often leading to short-sighted behaviors and poor robustness in dynamic scenes."
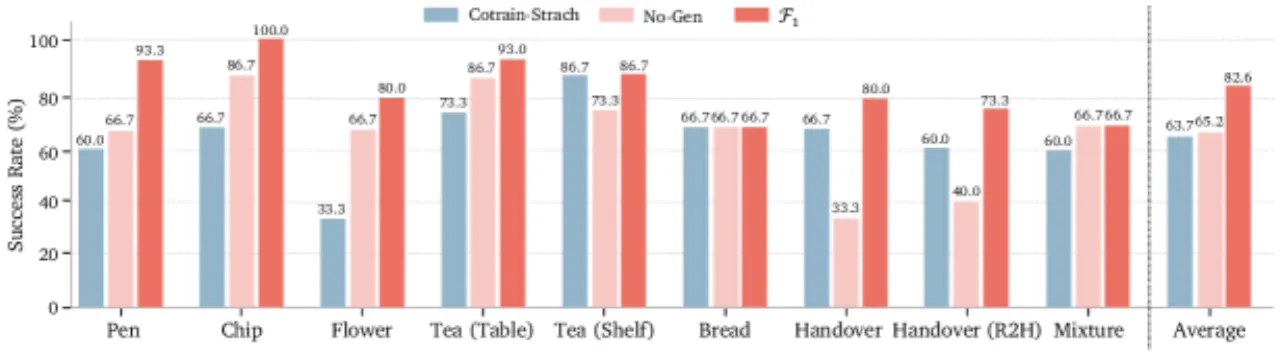
82.2%真实机器人任务平均成功率(vs. π₀ 65.2%)
95.7%LIBERO 平均成功率,全场景榜首
72.9%SimplerEnv Bridge 平均成功率
330k预训练轨迹数 · 136 任务 · 5 本体