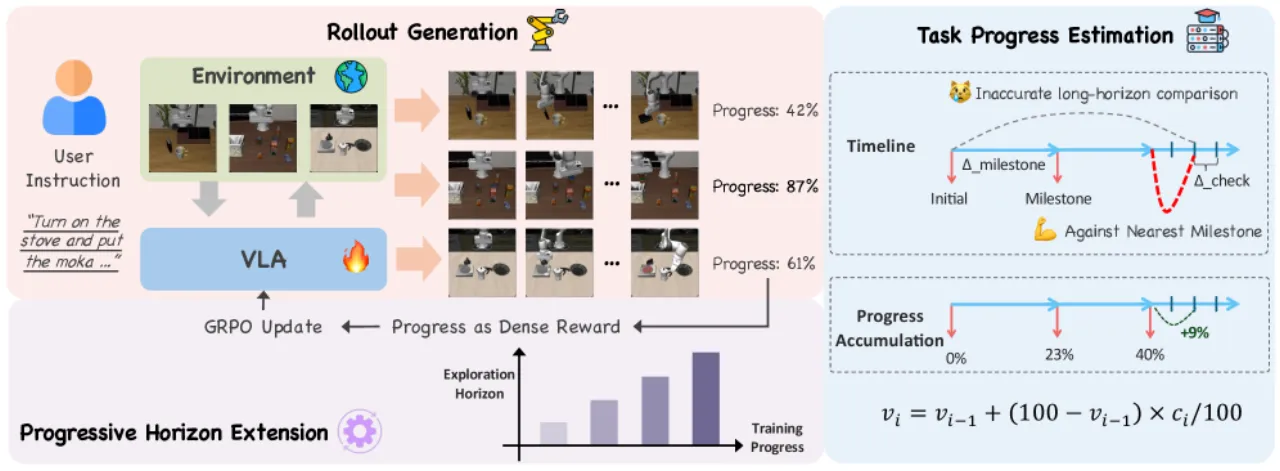
01 动机
当前的 VLA 模型依赖大规模的监督微调(SFT),这在实际部署中存在两大根本缺陷:高昂的数据采集成本以及脆弱的分布内记忆。模型在面对部署环境与训练分布的差异时几乎无法自适应恢复。
"How do humans develop manipulation skills? We do not simply watch an expert perform a task once and then flawlessly replicate it. Instead, we learn through practice: attempting the task repeatedly, making mistakes, receiving feedback from the environment, and gradually refining our movements through continued experience."
作者指出,现有 VLA 的两大核心瓶颈为:
- 高昂的数据成本:适应一个新任务往往需要收集数百条人工示范;
- 脆弱的记忆化泛化(brittle memorization):通过行为克隆训练的 VLA 仅能模仿示范,一旦执行偏差发生,便缺乏恢复能力,更无法泛化到训练分布之外。
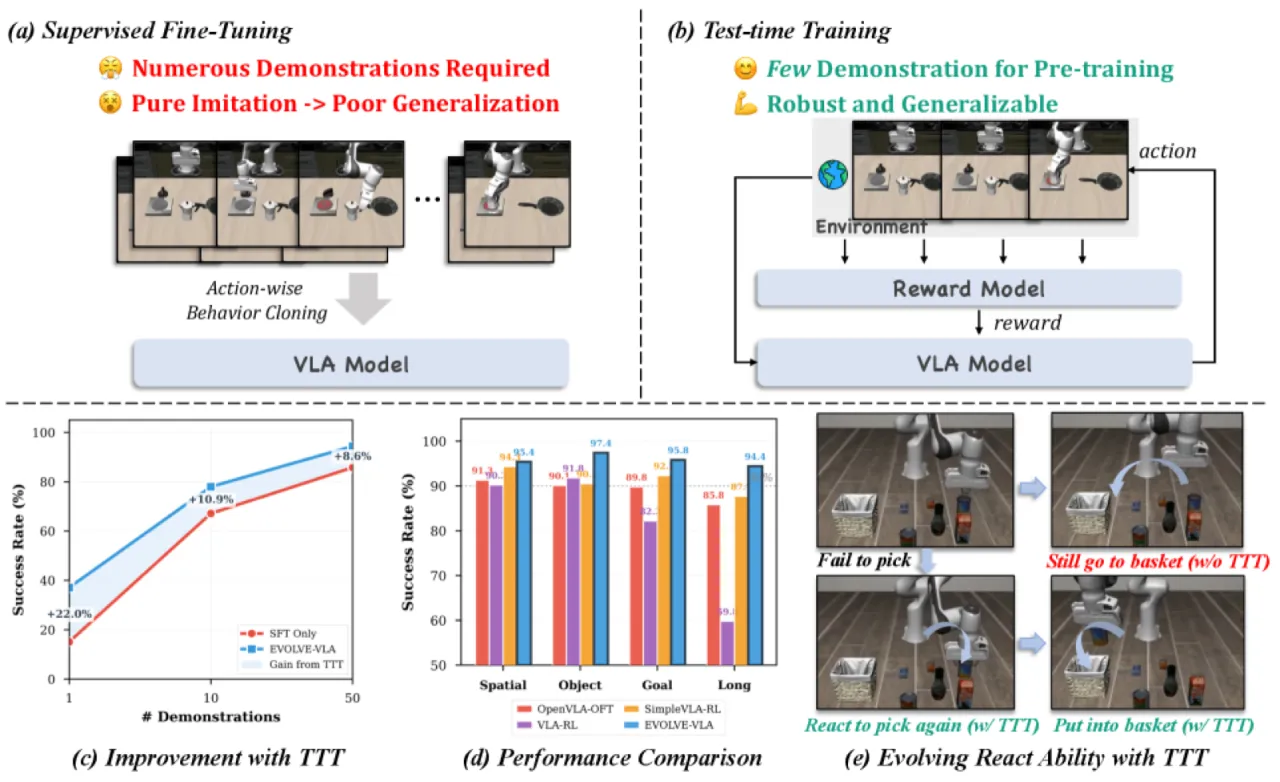
+8.6%LIBERO-Long 成功率提升
+17.7%1-shot 学习平均提升
20.8%跨任务泛化成功率(vs 0% SFT)
+6.5%LIBERO 整体平均提升