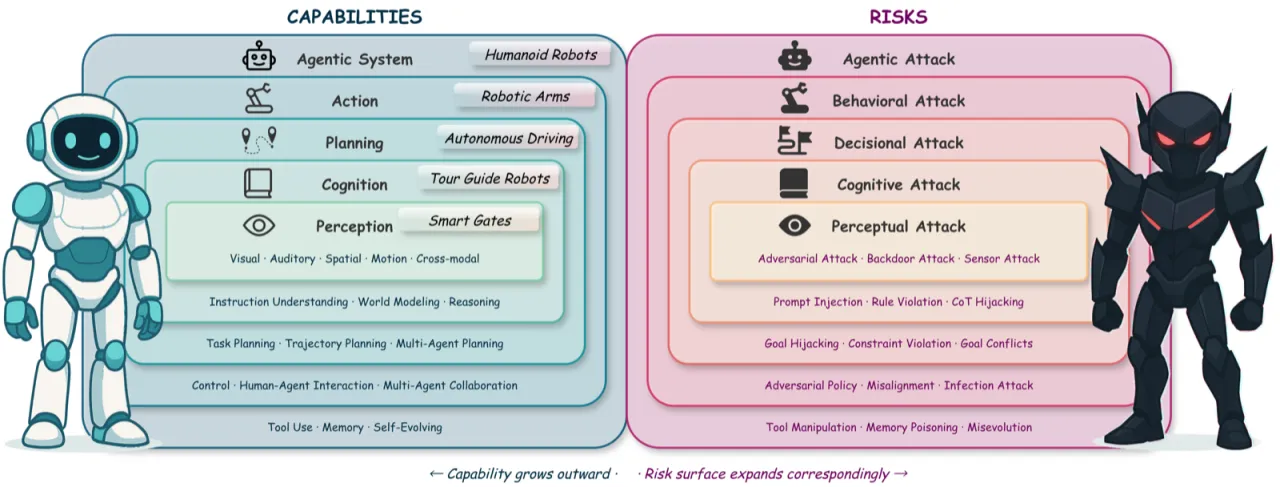
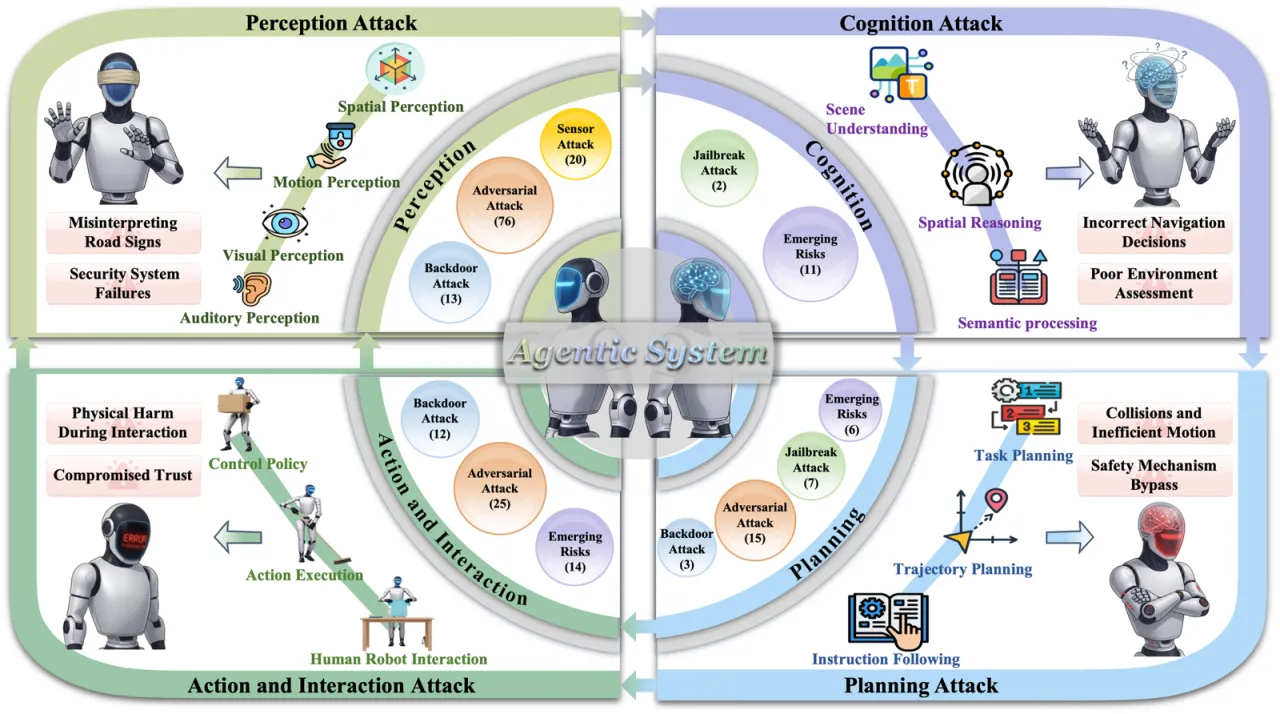
"Unlike digital AI systems, embodied agents must act under uncertain sensing, incomplete knowledge, and dynamic human-robot interactions, where failures can directly lead to physical harm."
此层聚焦机器人控制(robot control)、人机交互(human-agent interaction)和协作(collaboration)安全。
开放场景下的人机交互可信度问题(trustworthiness of human-agent interaction in open-ended scenarios)是当前最紧迫的研究缺口之一。
"The fragility of multimodal perception fusion, the instability of planning under jailbreak attacks, and the trustworthiness of human–agent interaction in open-ended scenarios."