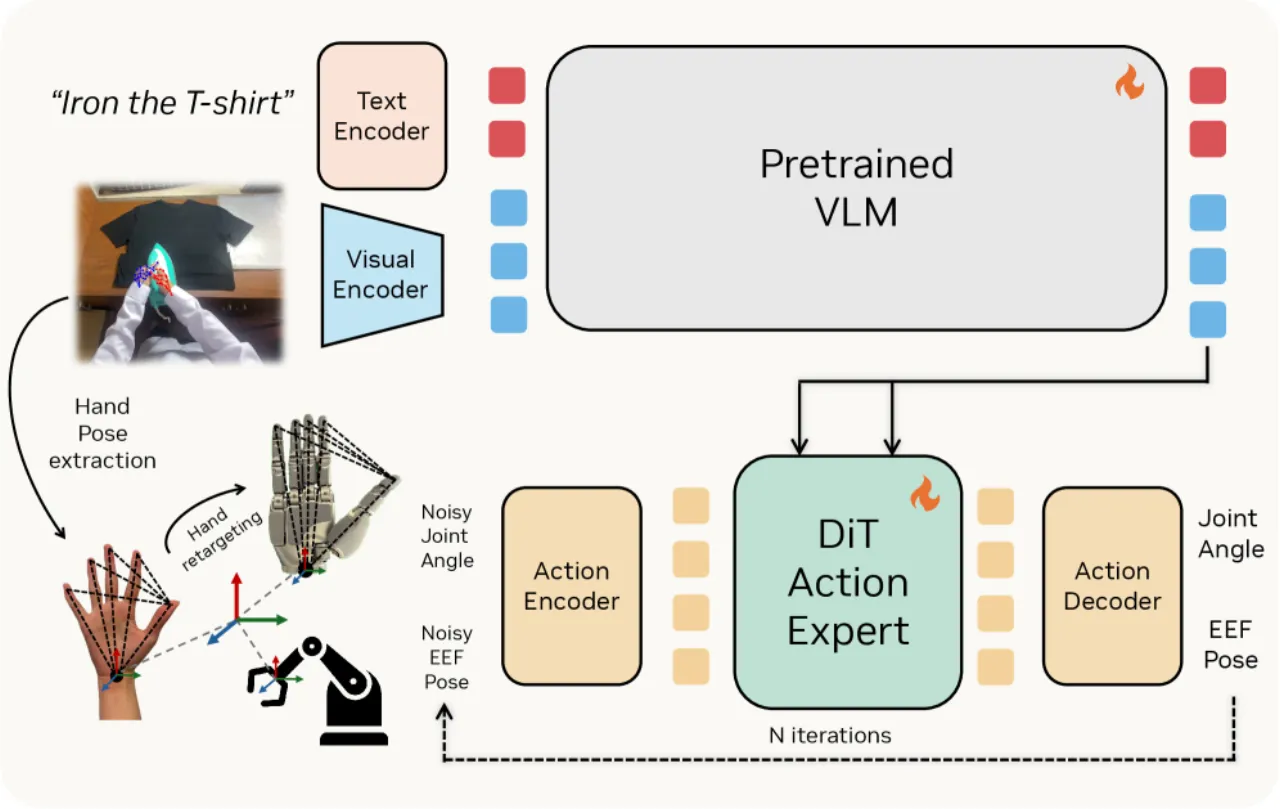
01 动机
机器人灵巧操作的核心瓶颈在于高质量训练数据的匮乏——遥操作采集成本极高,而人类每天都在无约束环境中自然产生数以万计小时的第一视角操作视频。如何让机器人从这些「免费」的人类行为数据中学习?
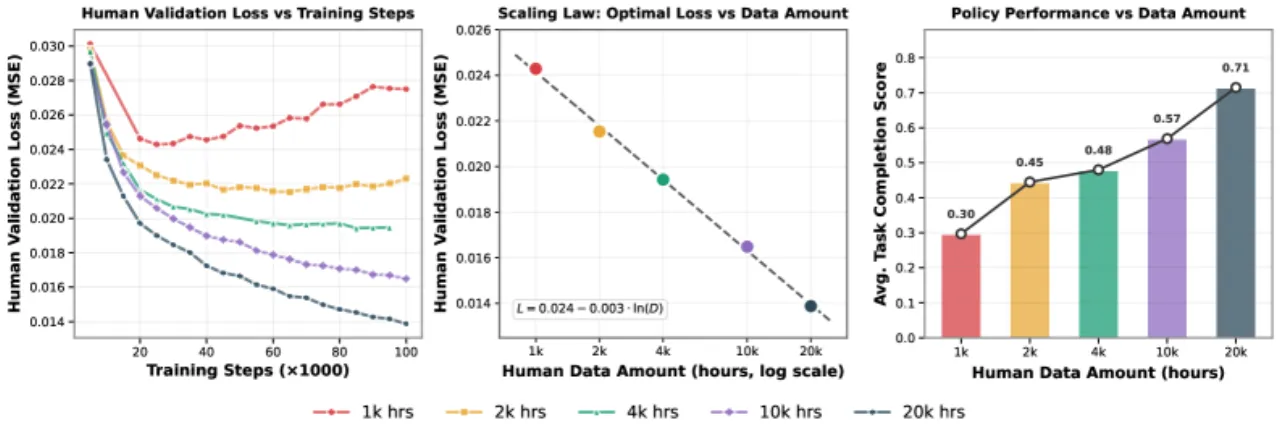
"We ask: can large-scale human data meaningfully support complex, dexterous manipulation at scale? … We find that effective transfer is fundamentally a scaling phenomenon."
现有人类-机器人迁移研究普遍存在两大局限:
- 数据规模不足:先前工作通常依赖"相对较小的人类数据集,数量级约为数十至数百小时"(relatively small human datasets, typically on the order of tens to hundreds of hours),远不足以揭示规模效应。
- 自由度局限:主流方法聚焦低 DoF 系统,对 22 自由度灵巧手等高 DoF 本体的迁移未有充分研究。

20,854 h第一视角人类操作视频(比先前工作多 20×)
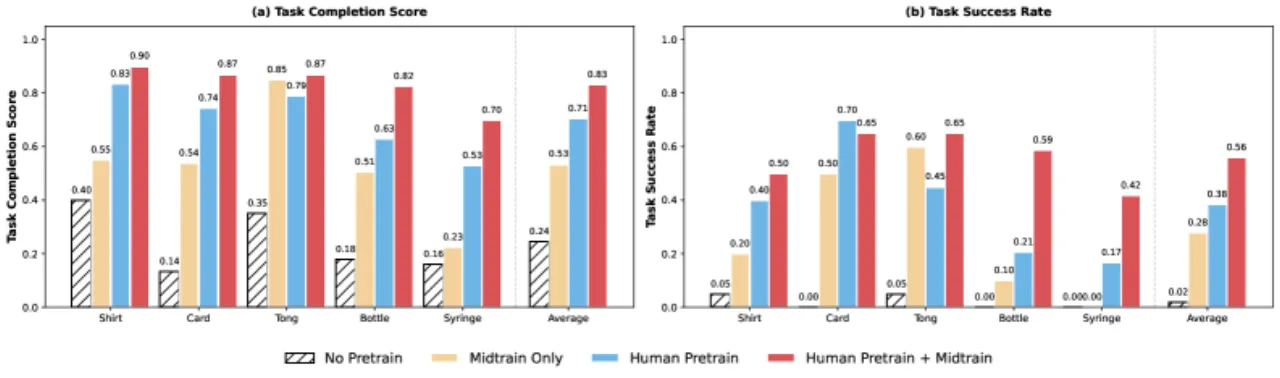
+54%相对 no-pretraining 基线的成功率提升(22-DoF 灵巧手)
R²=0.9983scaling law 拟合优度
88%单样本(one-shot)衬衫折叠成功率