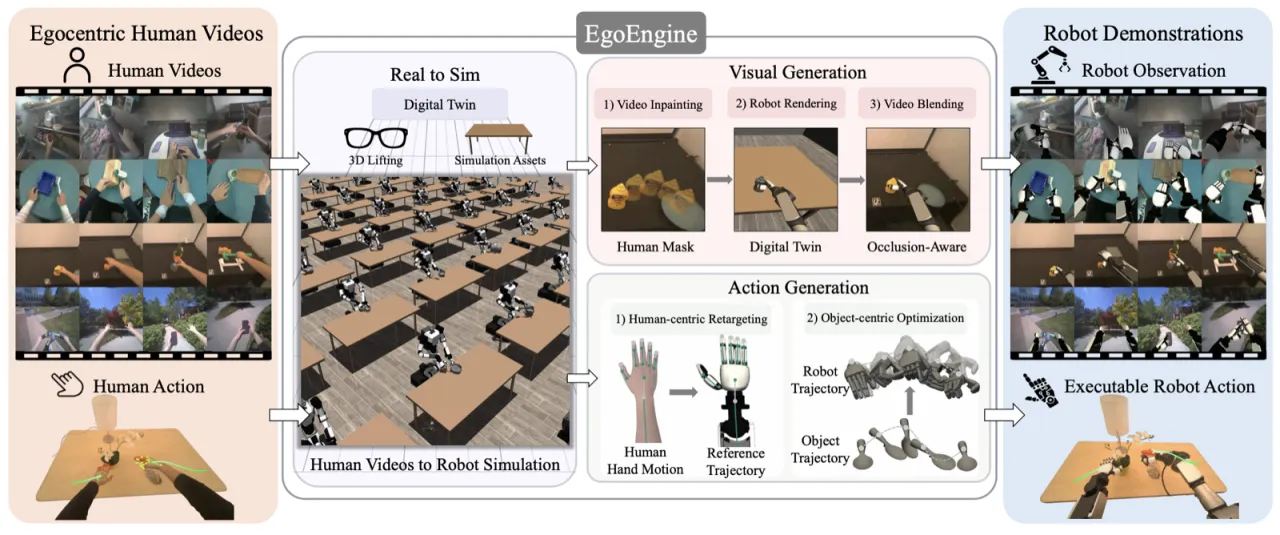
"Human videos are not robot demonstrations. The challenge is twofold: visually, human arms and hands occlude the scene and differ substantially from the robot embodiment; on the action side, differences in morphology, kinematics, actuation, and contact dynamics make directly retargeted robot trajectories physically infeasible."
重定向轨迹在形态学与接触动力学不匹配下往往不可执行。EgoEngine 在仿真中以物体中心目标对轨迹进行细化——用人类视频提取的物体运动 Tot 作为任务级目标,定义物体姿态跟踪误差 et(平移欧式距离 + SO(3) 测地距离的加权组合),超过阈值 C 则提前终止,奖励为 rtobj = C − et。