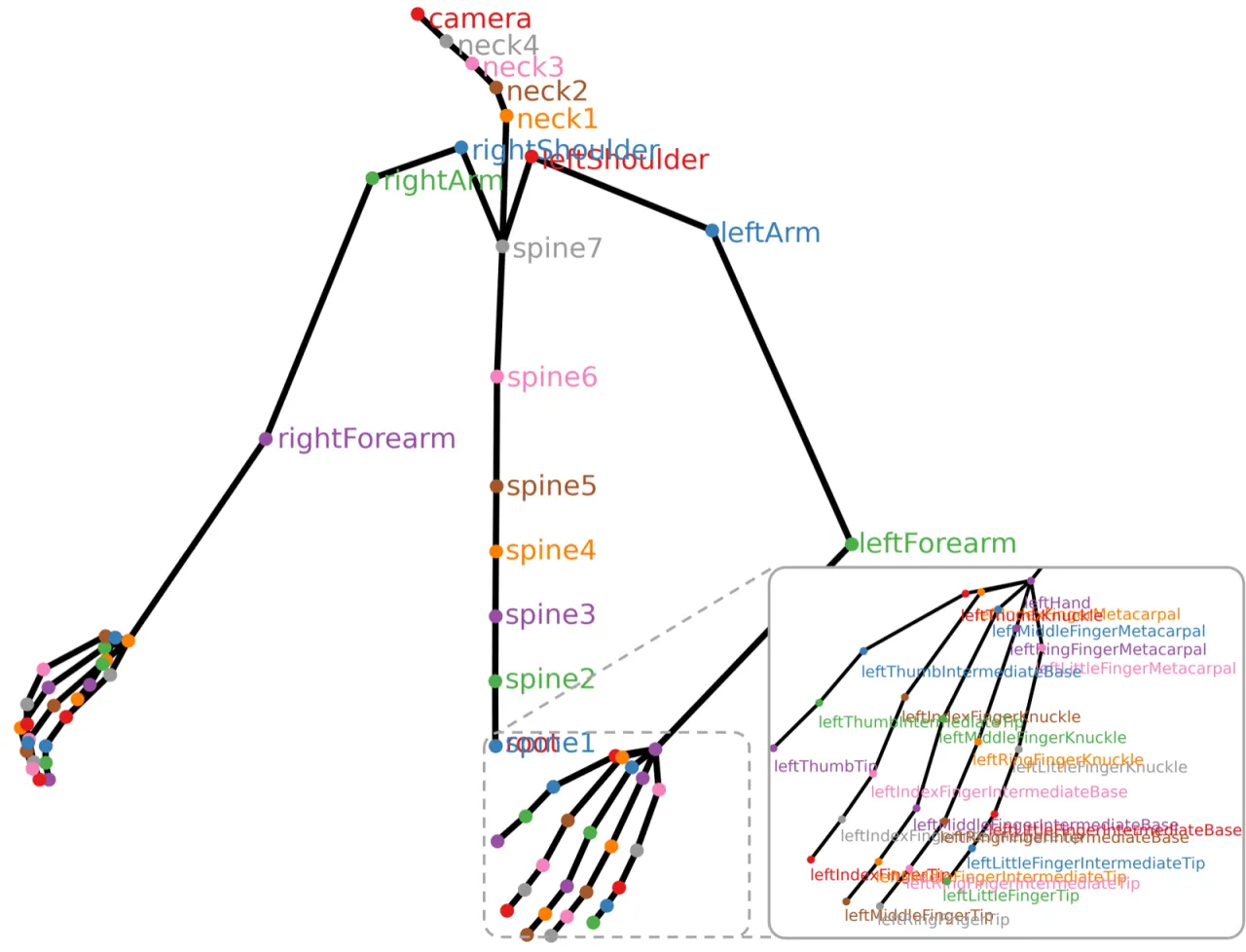
01 动机
机器人灵巧操作长期受限于高质量演示数据的匮乏。现有数据集要么规模小、任务单一,要么缺乏精细的手指级追踪信息,难以支持泛化能力强的策略学习。人类每天进行大量灵巧的手部操作,如何高效捕捉这些数据并用于机器人学习,是该领域的核心挑战。
"EgoDex contains 829 hours of egocentric video with paired 3D hand and finger tracking data, covering 194 tabletop manipulation tasks with household objects."

829hegocentric 视频时长
338K任务演示数量
194桌面操作任务种类
90M视频总帧数
与现有数据集的对比
EgoDex 在规模和标注质量上均大幅超越现有的机器人操作与人类手部交互数据集:
| 数据集 | 演示数量 | 任务数 | 帧数 | 灵巧手标注 |
|---|---|---|---|---|
| DROID | 76k | 86 | 19M | 否 |
| Ego4D (HOI) | 89k | n/a | 21M | 否 |
| EgoDex | 338k | 194 | 90M | 是 |
在动词多样性上,"most verbs in EgoDex are above the 10³ mark",而 DROID 中"many verbs are below the 10¹ mark"。