01 动机
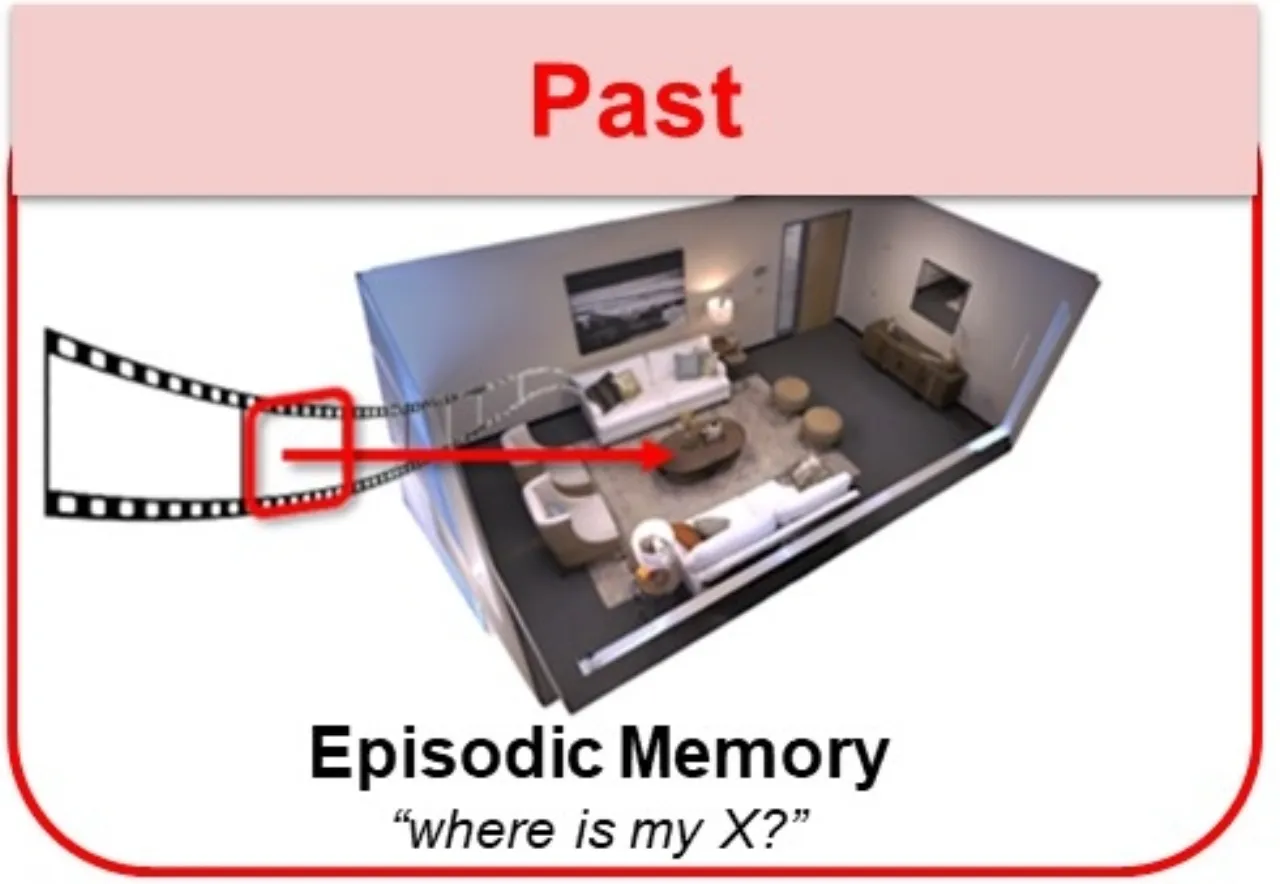
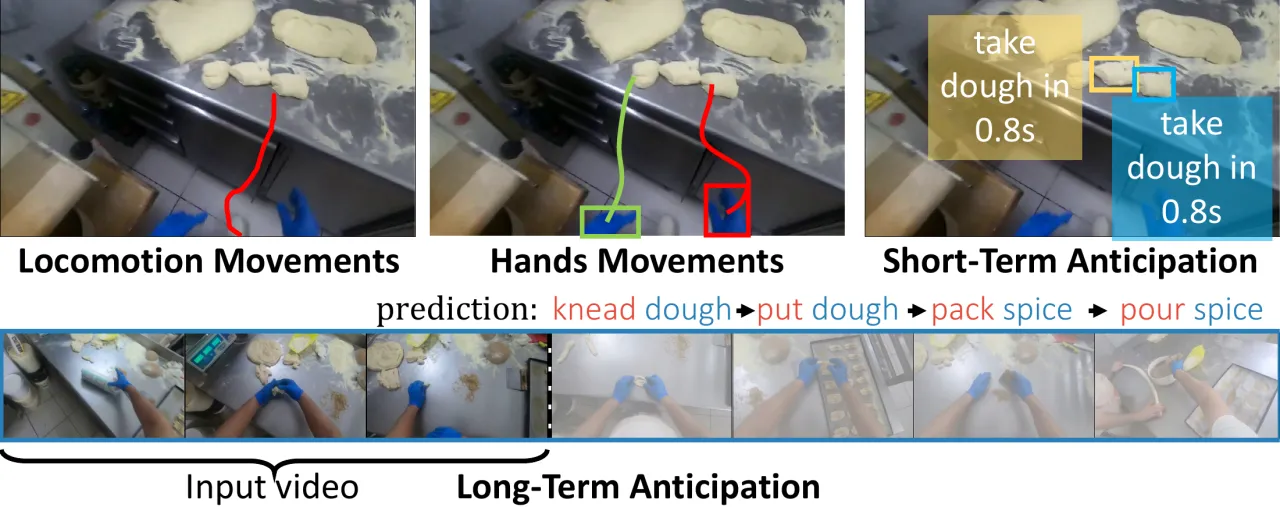
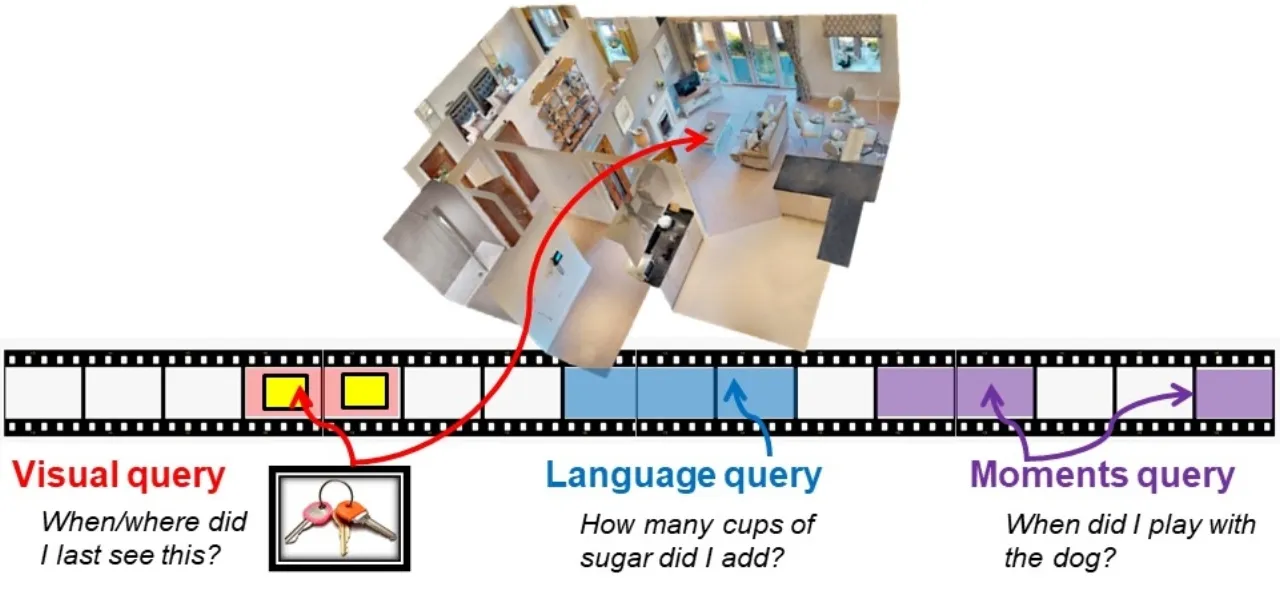
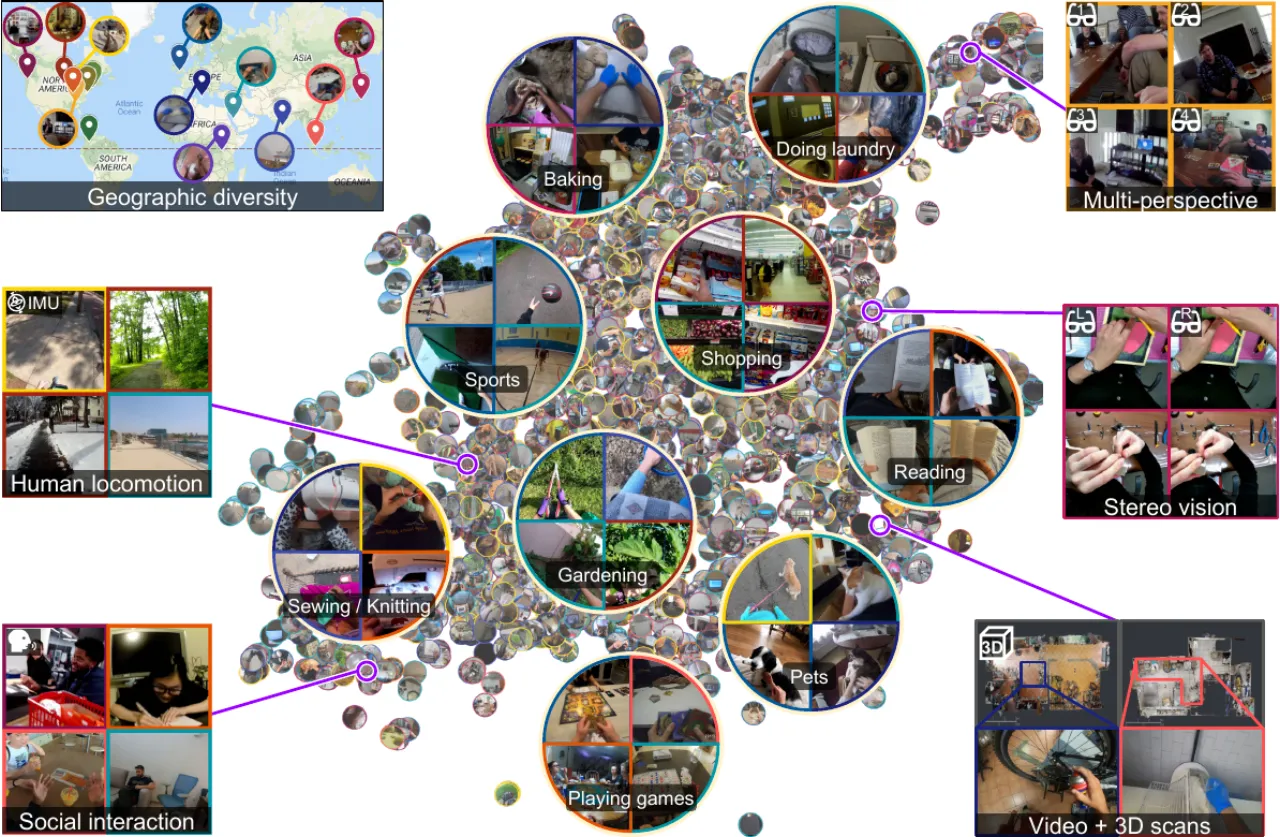
当前计算机视觉系统高度依赖「第三人称」互联网图像数据集,善于识别孤立的短片段对象与动作。然而,增强现实(AR)与机器人技术中的核心输入是第一视角(egocentric)的长流式视频——摄像头戴在人身上,实时记录日常互动、物体操作与社交行为。现有数据集在规模、多样性与真实性上均无法满足这一需求。
"Today's influential Internet datasets capture brief, isolated moments in time from a third-person 'spectator' view. However, in both robotics and augmented reality, the input is a long, fluid video stream from the first-person or 'egocentric' point of view — where we see the world through the eyes of an agent actively engaged with its environment."
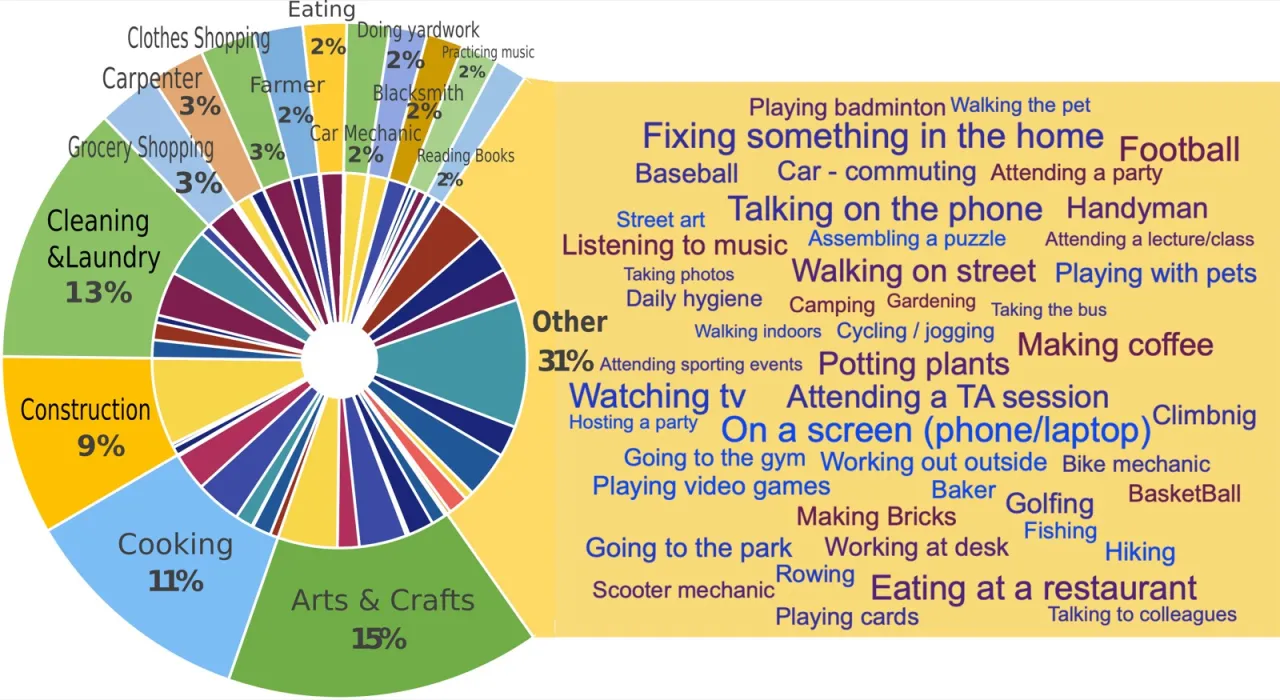
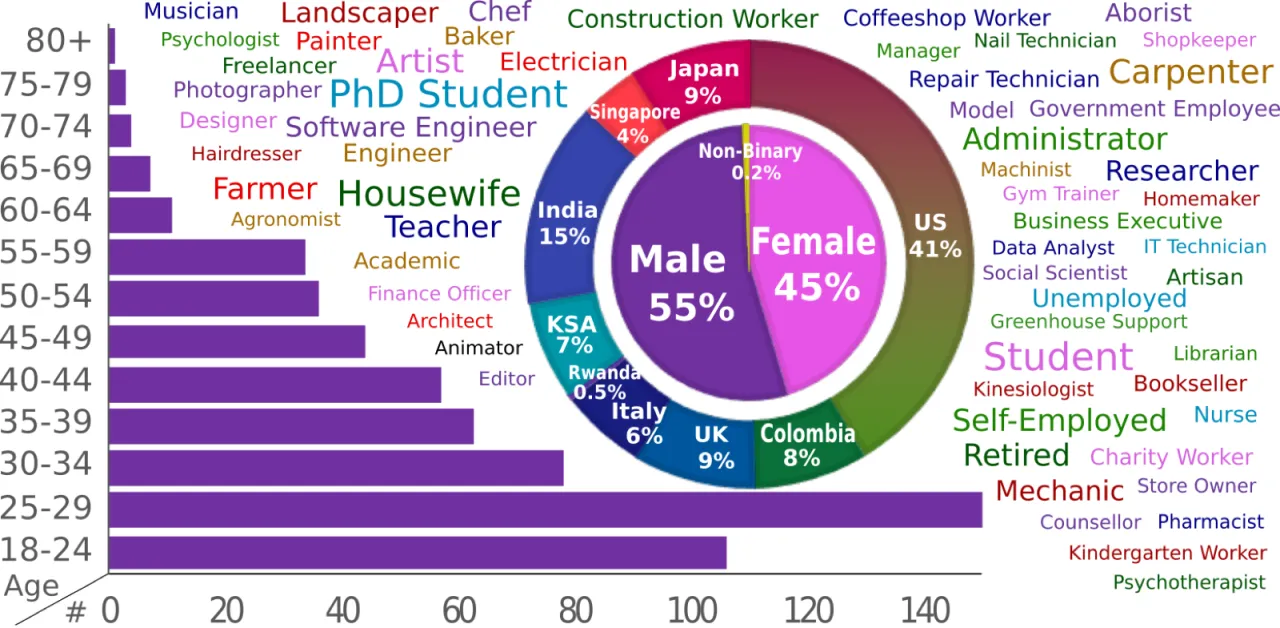
3,670小时视频(hours of video)
931独立拍摄者(unique camera wearers)
74全球地点(worldwide locations)
20×超越此前最大 egocentric 数据集
Ego4D 名称来源:Ego 代表 egocentric(第一视角),4D 代表三维空间加时间维度。数据集由来自 9 个国家、5 大洲的 14 个机构历时两年联合采集,历经逾 250,000 小时的标注工作,产出数百万条时序、空间与语义标注。