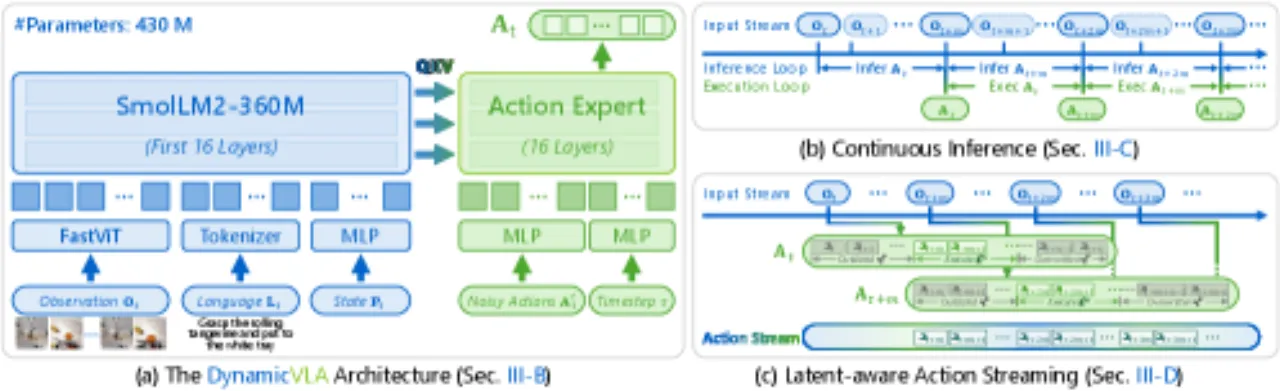
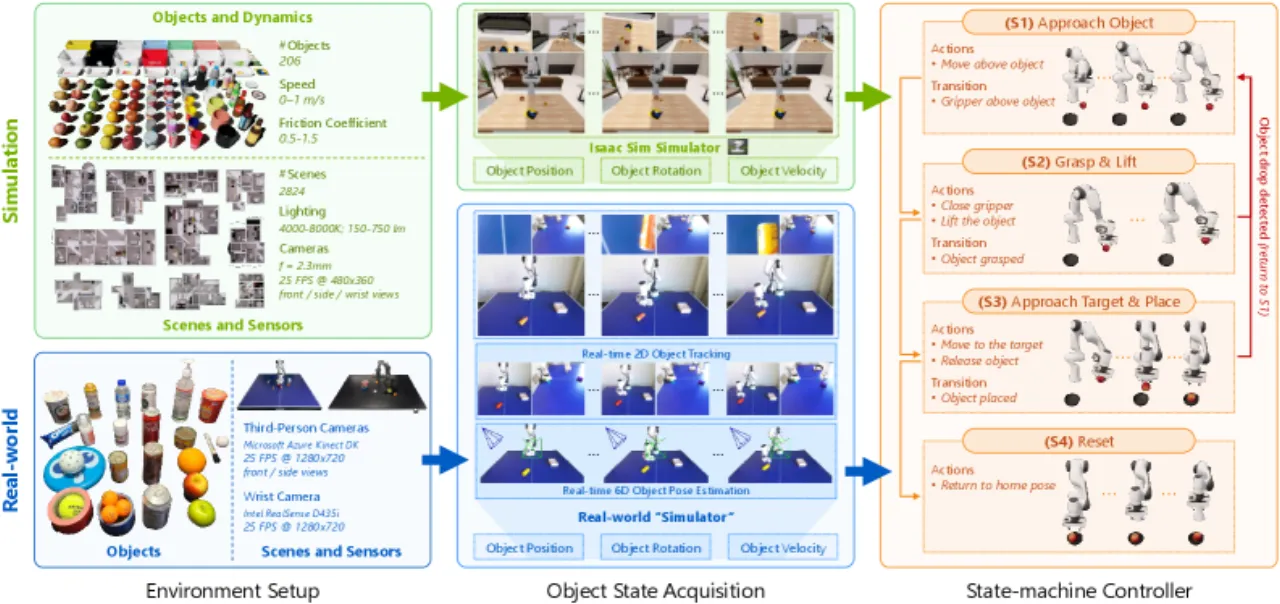
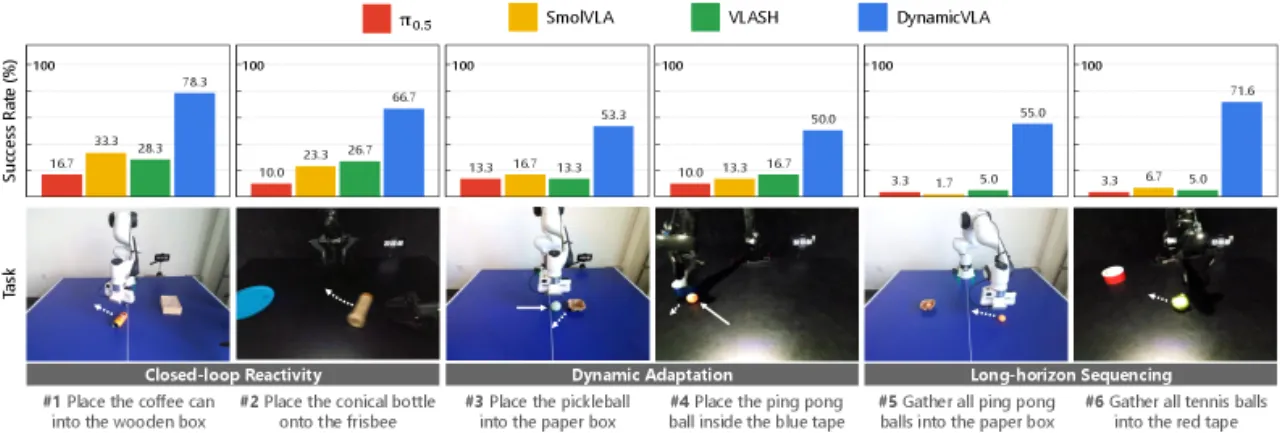
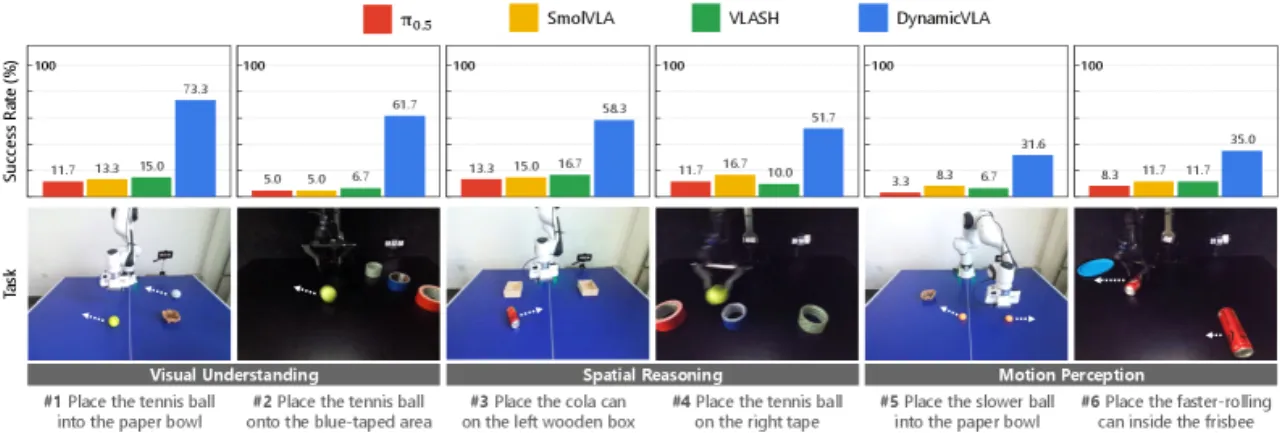
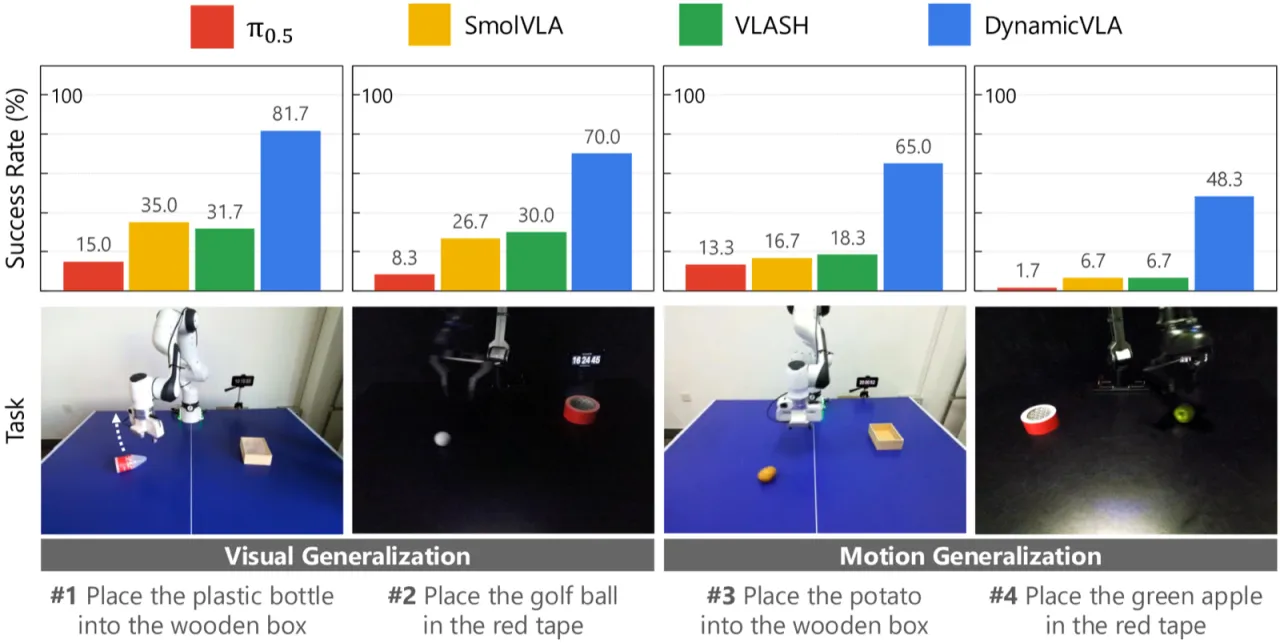
"Dynamic object manipulation remains an open challenge for Vision-Language-Action (VLA) models, which…struggle in dynamic scenarios requiring rapid perception, temporal anticipation, and continuous control."
传统方案在执行完一个 action chunk 后才触发下一次推理,造成不可避免的等待间隙。CI 改为:
"triggers inference cycles as soon as the previous inference finishes, independent of whether the previously predicted action sequence has been exhausted."
推理与执行全程流水线并行,消除 inter-chunk waiting,使机器人始终在执行动作的同时完成下一轮感知与预测。
消融实验显示,CI 将成功率从 36.11% 提升至 47.06%(+30.4%)。
Latent-aware Action Streaming (LAAS)
CI 引入新的时序问题:某一推理周期预测的 action 序列,在执行时目标物体已移动到新位置,导致旧 action 作用于"幽灵轨迹"。
LAAS 的解决方案:"Actions in At corresponding to timesteps earlier than t+m are discarded as outdated",
始终优先执行最新 chunk 中的动作。消融实验显示,在 CI 基础上叠加 LAAS 进一步将成功率从 39.72% 提升至 47.06%(+18.5%)。