world modellanguage grounding多模态世界模型reinforcement learningembodied AIDynalangDreamerV3vision-language navigation
01 动机
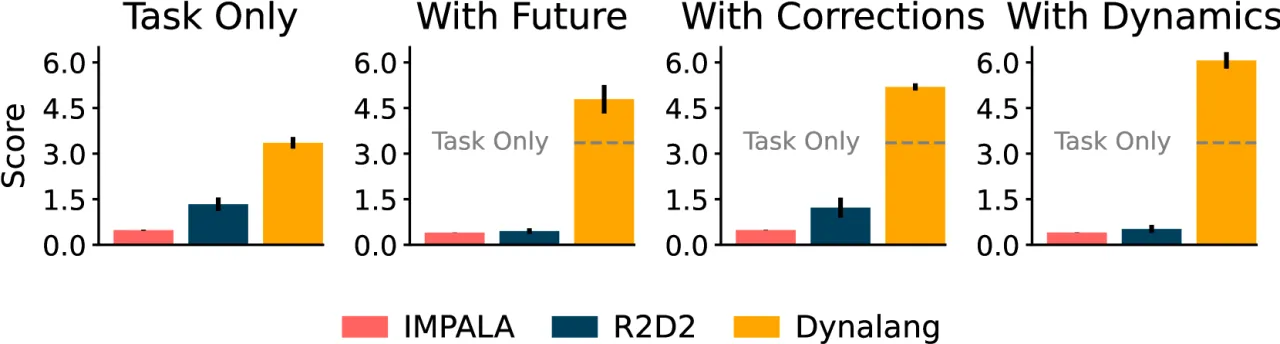
现有具身 AI 智能体在处理语言时存在严重局限——它们往往只能接受简单的任务指令(如"拿起苹果"),却无法利用更丰富的语言形式:状态描述("碗在厨房里")、动态解释("这个按钮会关掉电视")、以及纠错反馈。当这些多样化语言信号涌入时,model-free 的基线方法(如 R2D2)甚至会出现性能退化的现象。
"We argue that agents should interpret such diverse language as a signal that helps them predict the future — what they will observe and what reward they will receive — rather than as a direct command to execute."