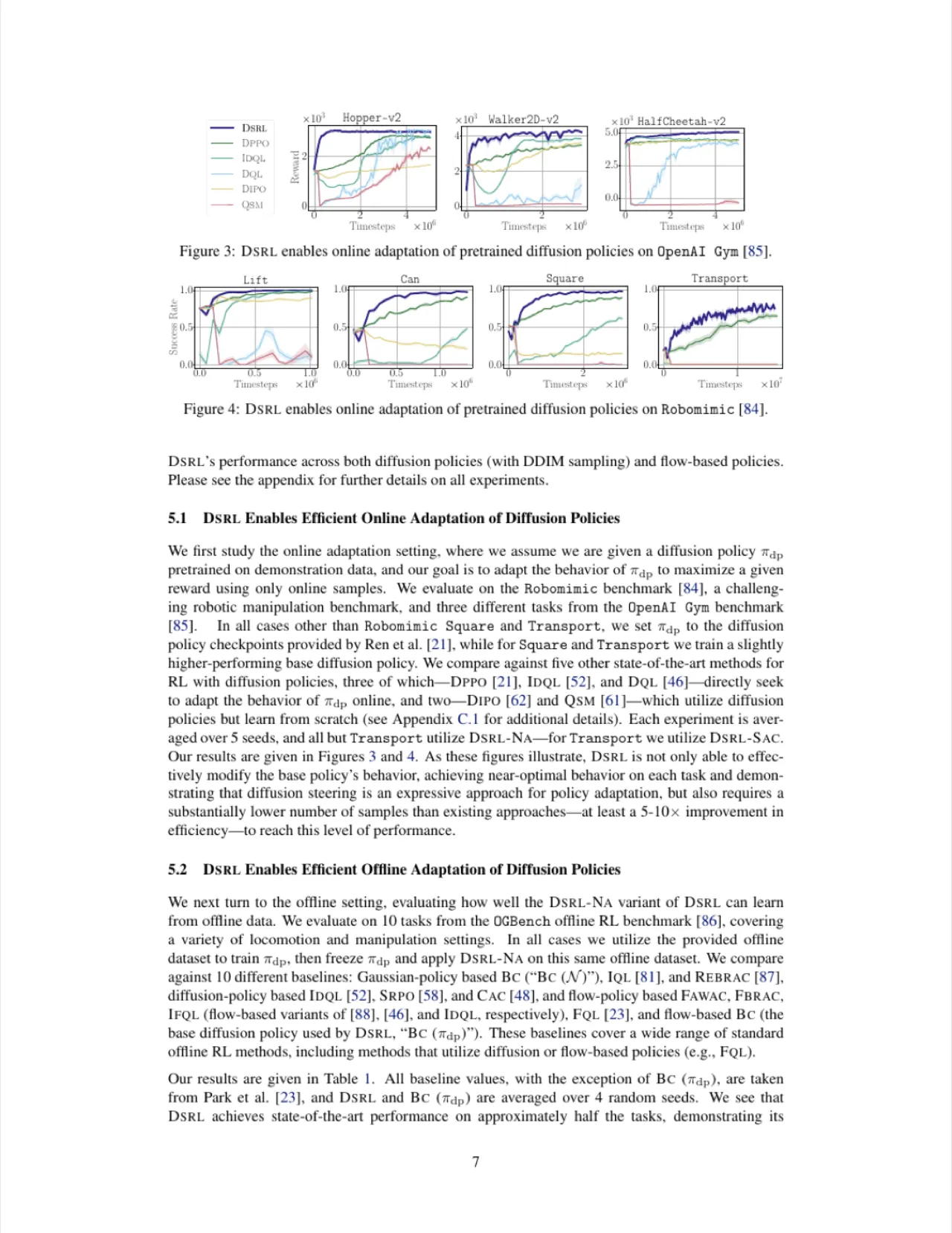
01 动机
扩散策略(diffusion policy)在机器人操控领域表现出色,但从 behavioral cloning(BC)训练所得的策略往往性能不足,且在真实场景中存在分布偏移。传统的强化学习微调需要对整个策略网络进行梯度更新,计算代价高昂,且在真实机器人上采集数据既危险又耗时。如何以极低成本、少量样本将预训练扩散策略适配到目标任务,是一个核心挑战。
"We propose to instead perform RL in the latent-noise space of diffusion policies, without modifying the diffusion policy weights themselves. This is simple, sample efficient, requires only black-box access to the BC policy, and enables effective real-world autonomous policy improvement."

黑盒仅需黑盒访问 BC 策略,无需修改权重
50 ep真实机器人上典型适配所需样本数量量级
5×+相比 fine-tuning 基线的相对成功率提升(部分任务)
全流程支持离线数据 / 在线自主改进 / 多任务策略
现有工作主要分为两类局限:
- 直接 RL 微调扩散权重(如 DPPO、SRPO 等):需要对整个神经网络做反向传播,计算量大,且梯度需穿越整个去噪链(通常 10–100 步),内存和时间成本极高。
- 引导(guidance)方法:依赖可微分奖励函数或分类器,在真实机器人场景中往往不可行,且通常只能用于 offline 设置。
DSRL 的关键洞察是:扩散策略的去噪过程完全由初始噪声 x_N 决定,只要找到合适的 x_N,就能控制最终生成的动作,而这一优化可以在远低维的潜在空间中高效完成。