01 动机
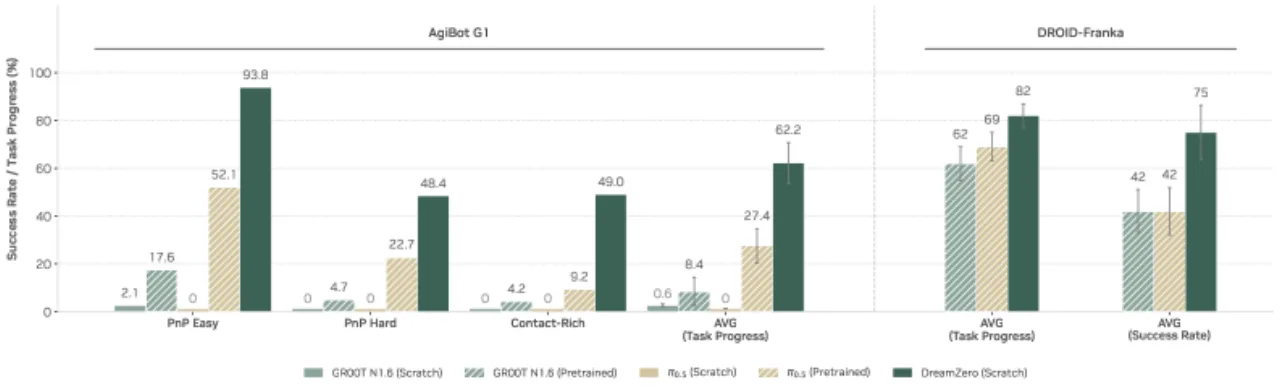
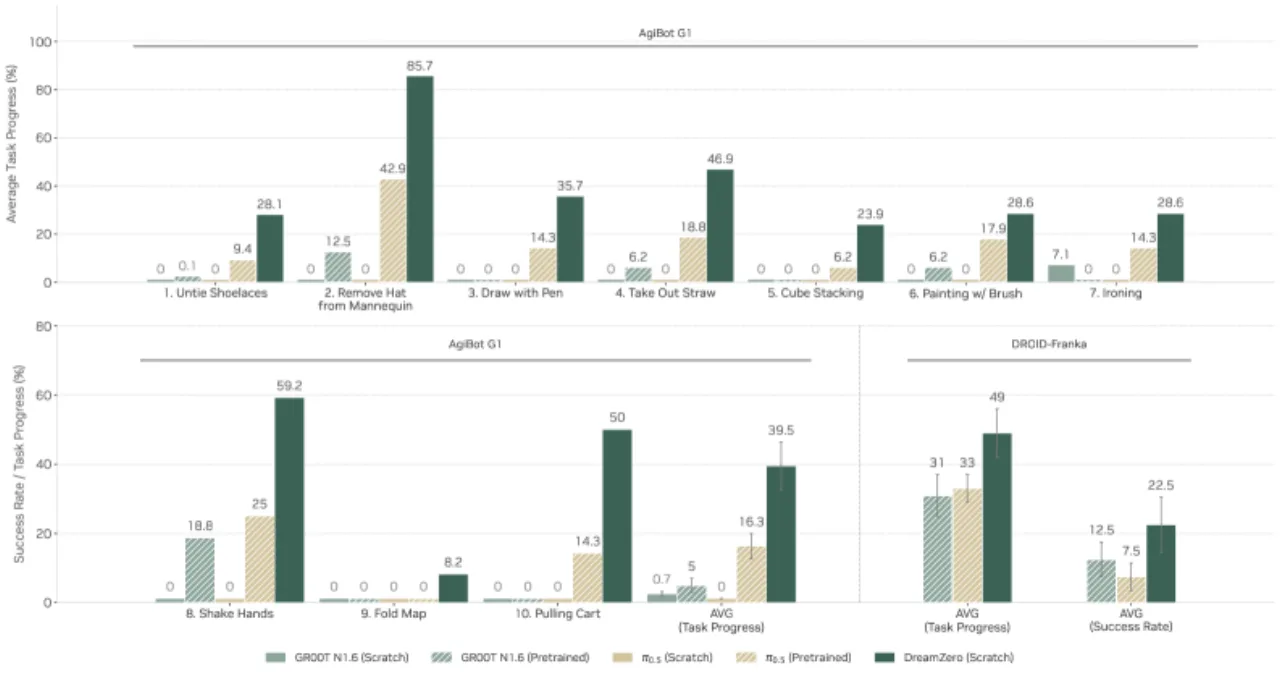
当前主流机器人策略(VLA)依赖大量重复性示范数据进行训练,对未见任务和环境的泛化能力极为有限;即便经过预训练,在多样化非重复数据上也几乎学不到任何有效行为。如何让机器人策略真正"理解"物理世界、实现开放世界零样本泛化,是本文的核心问题。
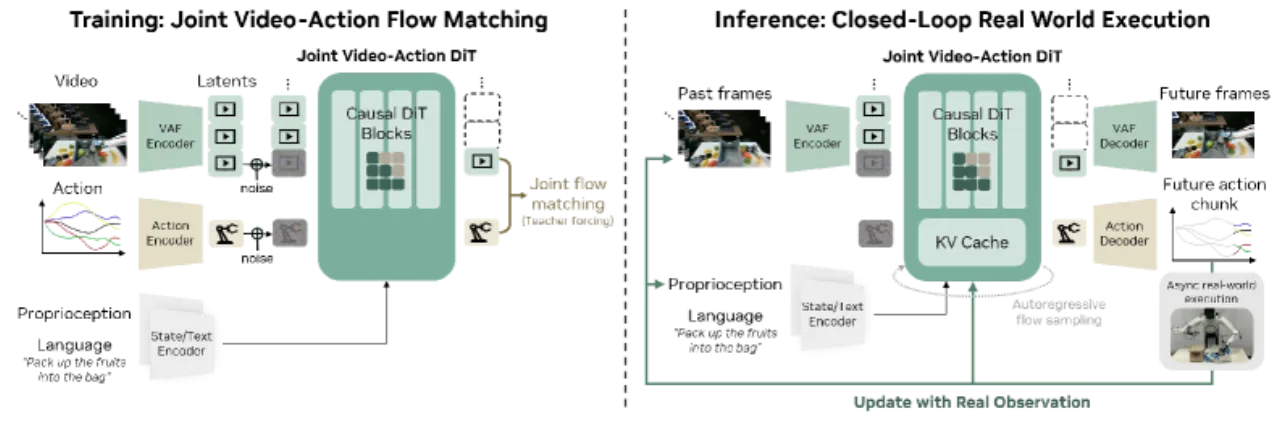
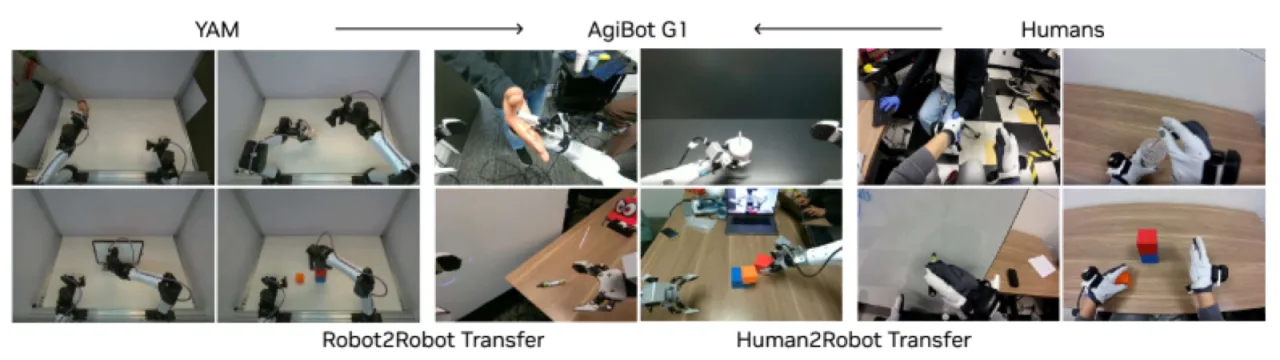
"By jointly predicting video and action, World Action Models (WAMs) inherit world physics priors that enable 1) effective learning from diverse, non-repetitive data, 2) open-world generalization, 3) cross-embodiment learning from video-only data, and 4) few-shot adaptation to new robots."
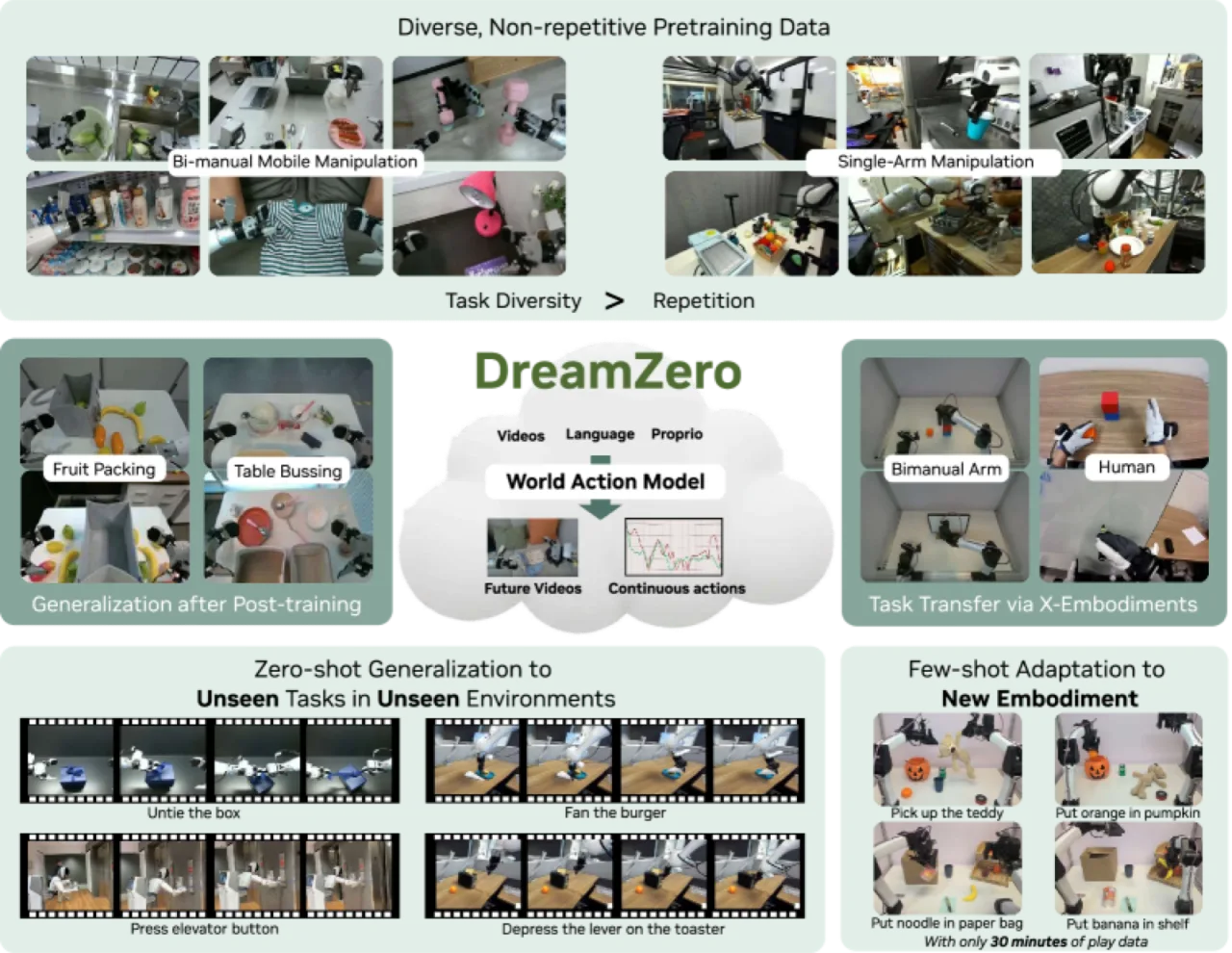
>2×零样本泛化提升
vs. SOTA VLA
vs. SOTA VLA
38×推理加速
(vs. 原始 DiT)
(vs. 原始 DiT)
7 Hz实时闭环控制
(150ms 延迟)
(150ms 延迟)
30 min少样本适配新机器人
仅需游玩数据
仅需游玩数据