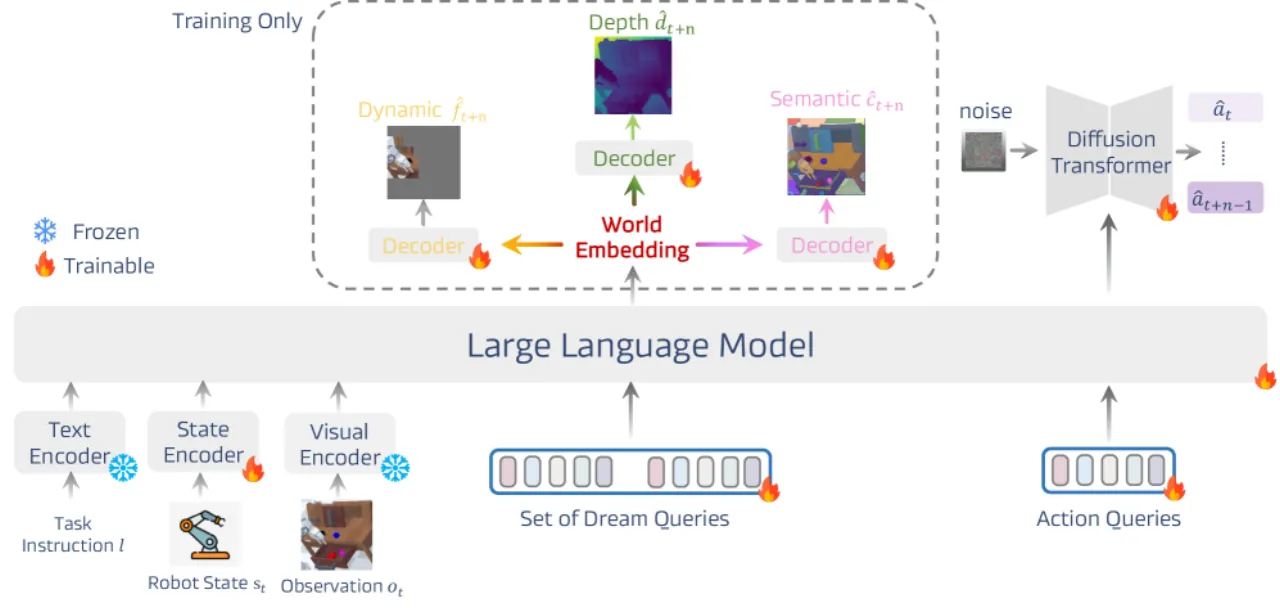
01 动机
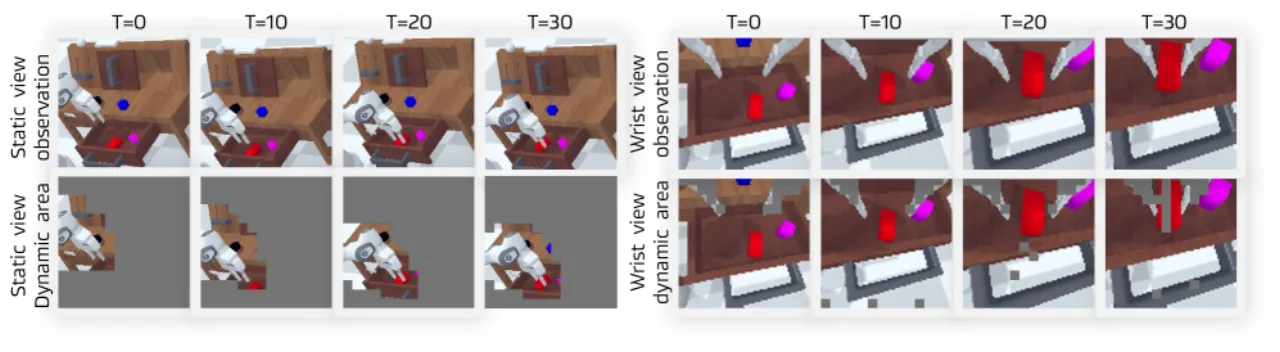
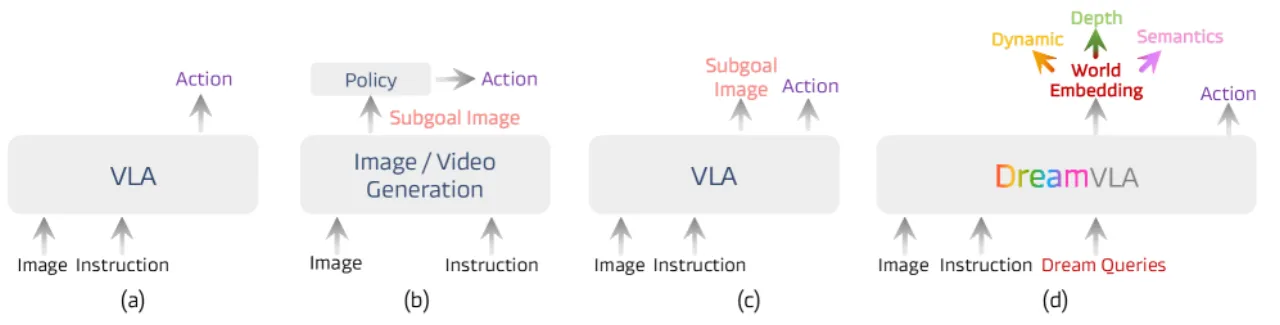
当前 VLA 模型大多直接将视觉观测与语言指令映射为动作序列,缺乏对"未来会发生什么"的显式推理。已有研究尝试通过预测整帧图像或生成子目标来引入前瞻性,但这类方法引入了大量冗余像素信息、缺少显式 3D 知识,且对未来状态的高层理解十分有限,导致泛化能力不足。
"Prior work relies on redundant pixel information, lacks explicit 3D knowledge, and fails to capture high-level understanding of future states."
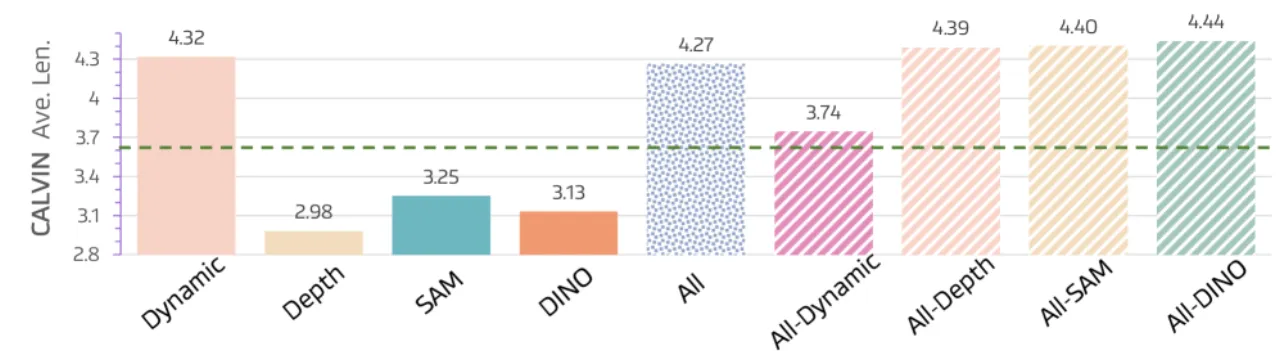
4.44CALVIN ABC-D 平均长度(SOTA)
92.6%LIBERO 综合成功率
76.7%真实 Franka 机器人成功率
3×世界知识类型(动态 + 深度 + 语义)