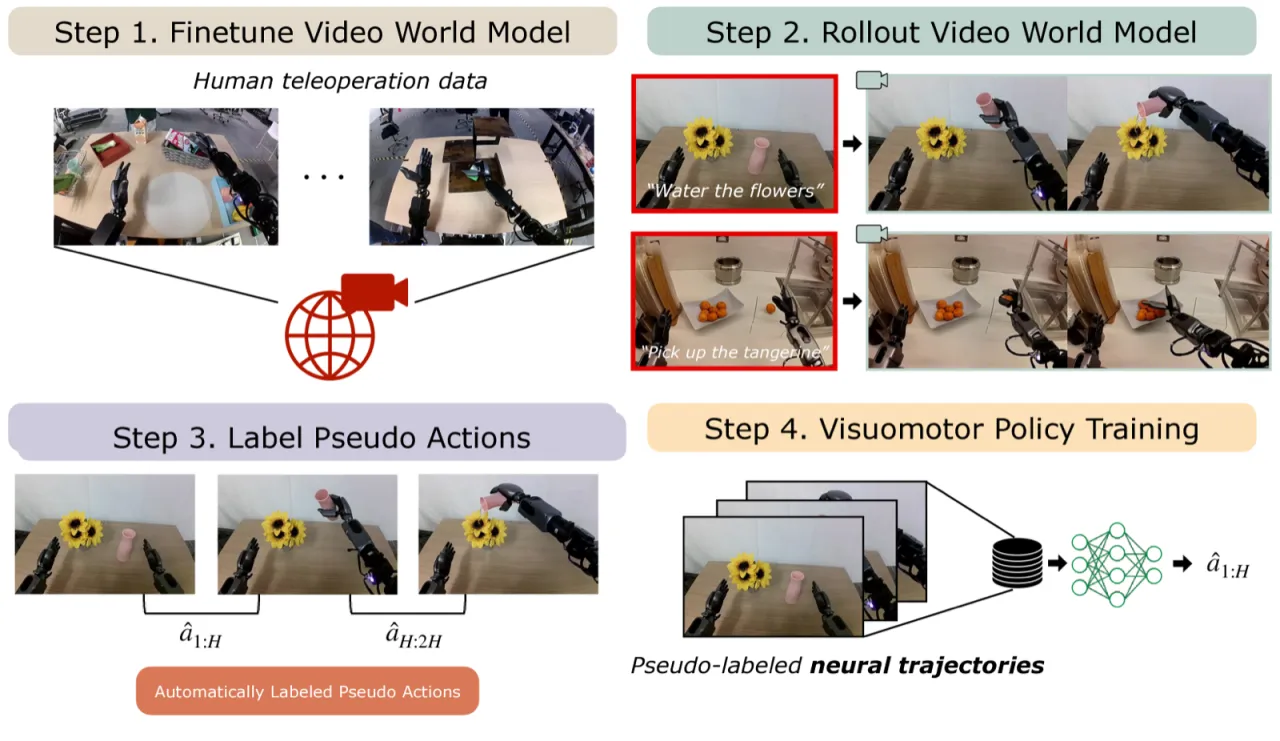
01 动机
机器人策略的泛化能力长期受限于数据匮乏:遥操作采集成本高昂,且单一场景的数据难以覆盖多样行为与陌生环境。如何在极少真实数据的前提下,让策略跨行为、跨环境迁移,是领域核心难题。
"DreamGen, a simple yet highly effective 4-stage pipeline for training robot policies that generalize across behaviors and environments through neural trajectories—synthetic robot data generated from video world models."
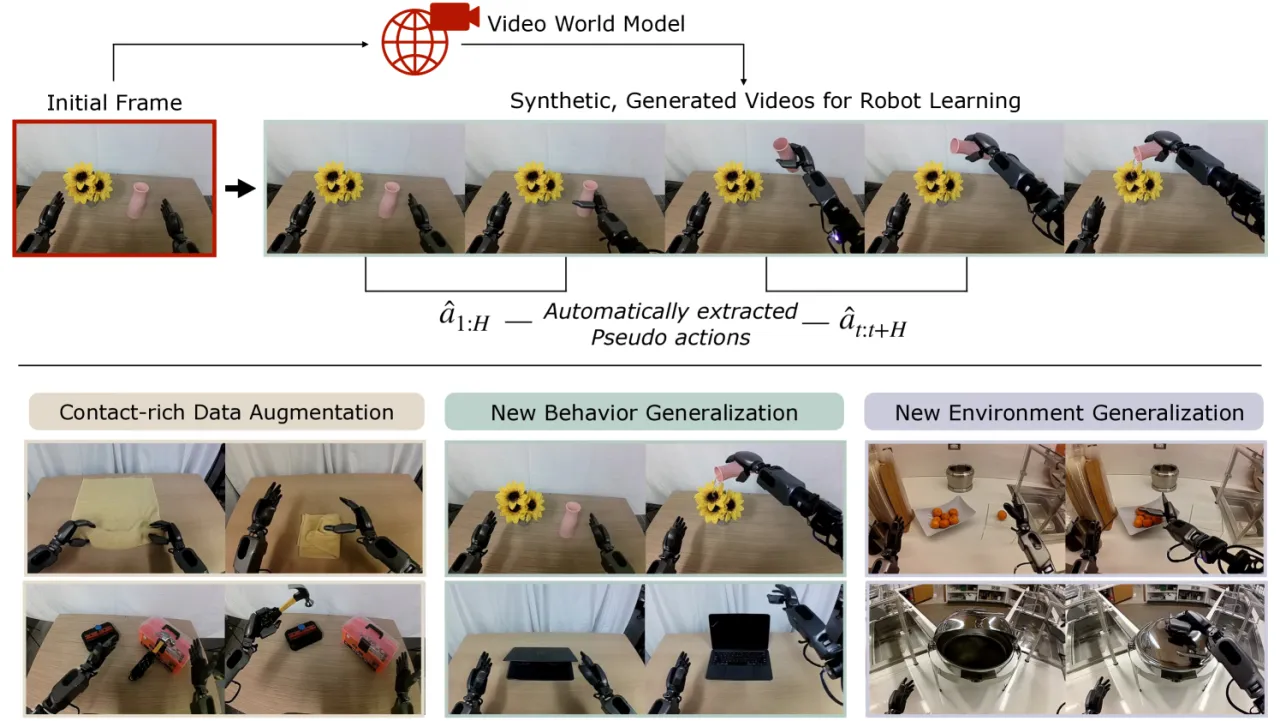
22新行为泛化(zero-shot novel behaviors)
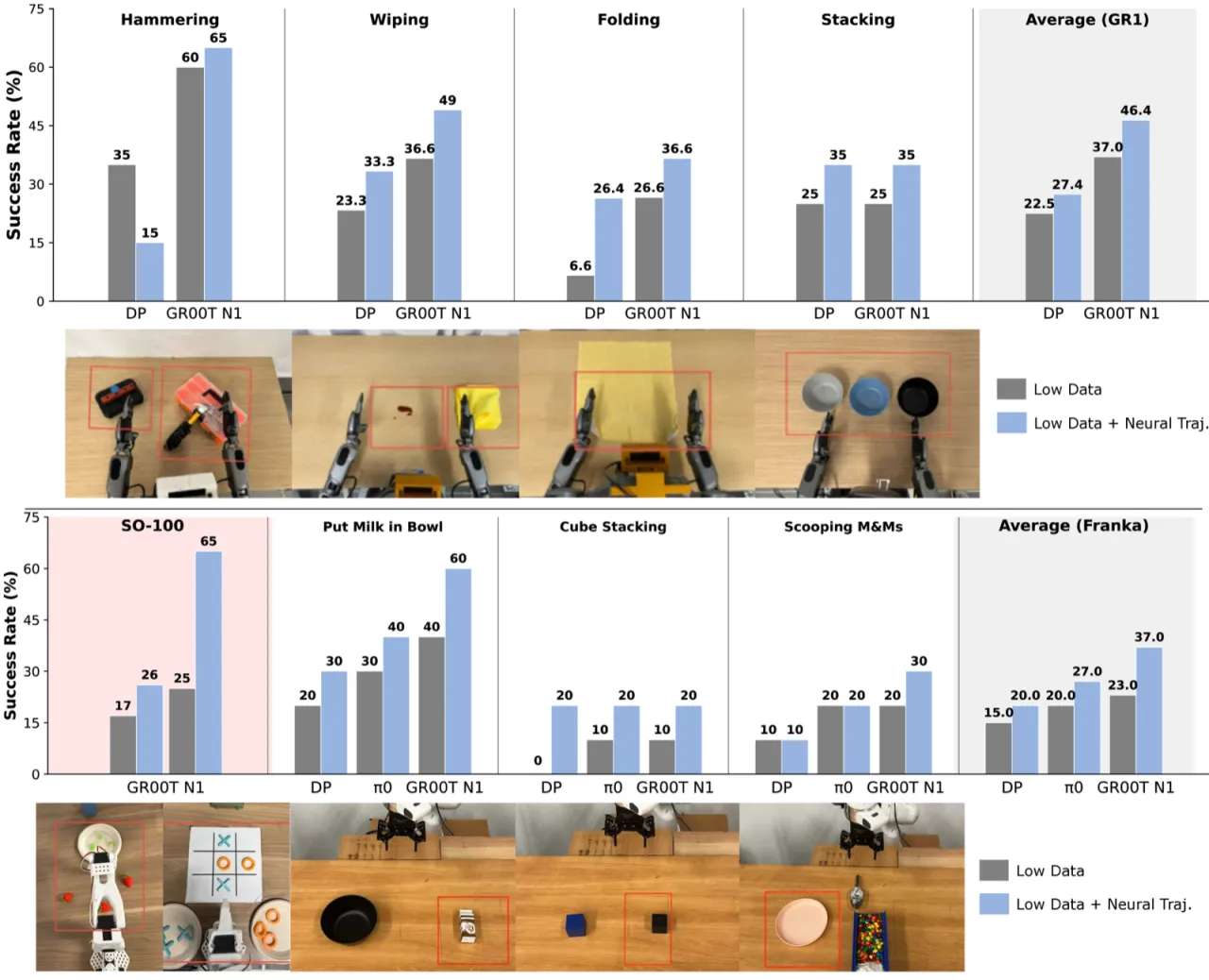
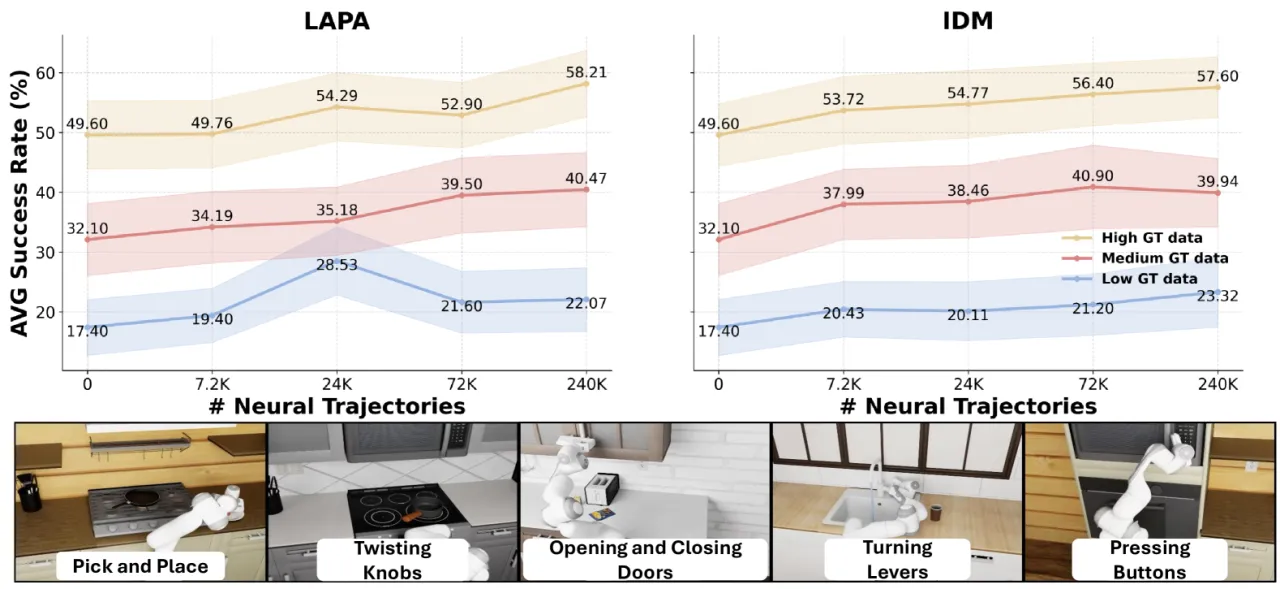
43.2%DreamGen 在 14 新行为上的平均成功率(vs. baseline 11.2%)
28.5%在未见环境+新行为的平均成功率(baseline 为 0%)
10–13每任务真实轨迹数(极少数据即可显著提升)