01 动机
强化学习已在围棋、电子游戏等单一领域取得突破,但每换一个新任务就需要重新调参——这严重限制了 RL 的实用价值。作者提出的核心问题是:
"Developing a general algorithm that learns to solve tasks across a wide range of applications has been a fundamental challenge in artificial intelligence."
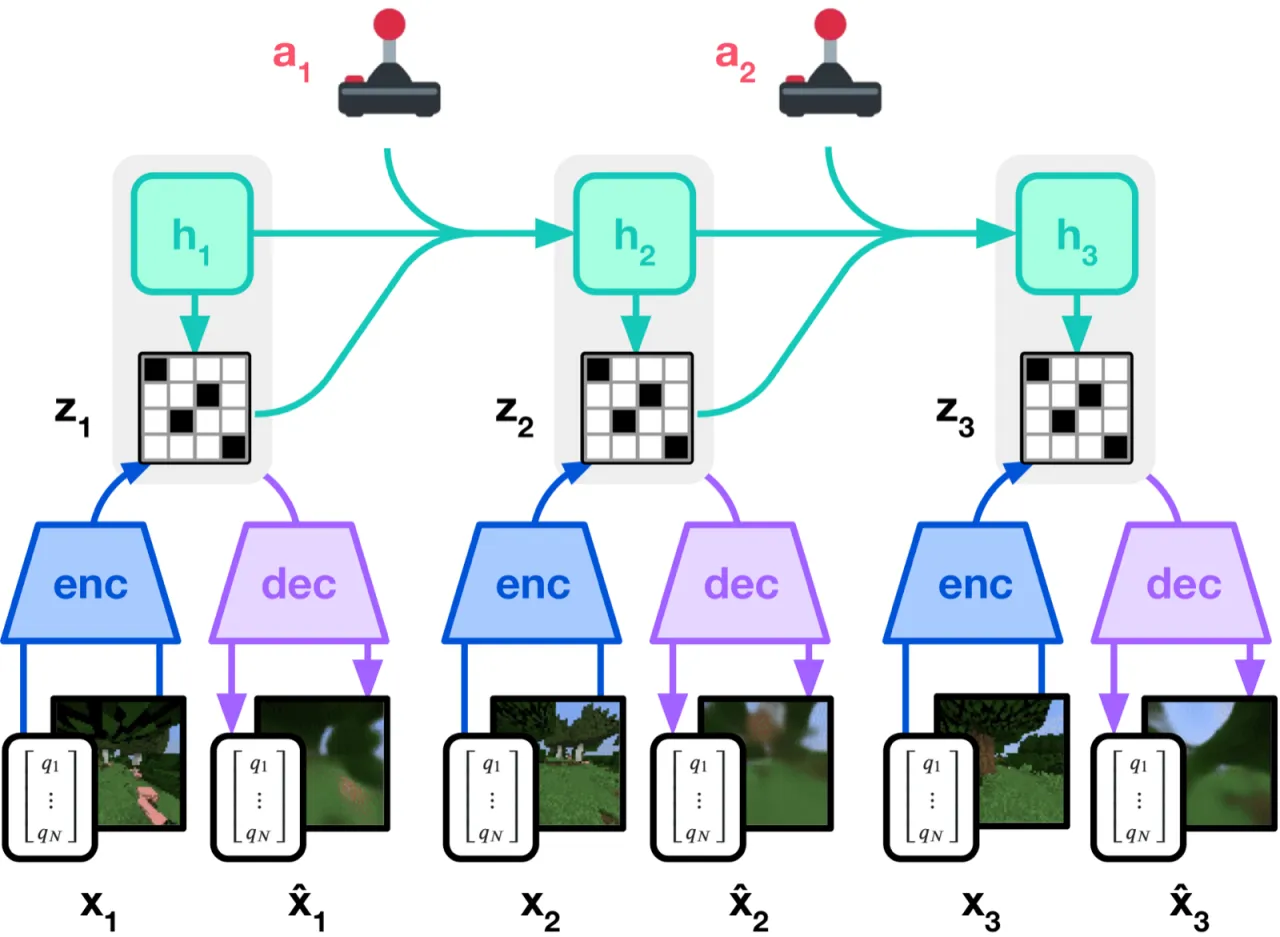
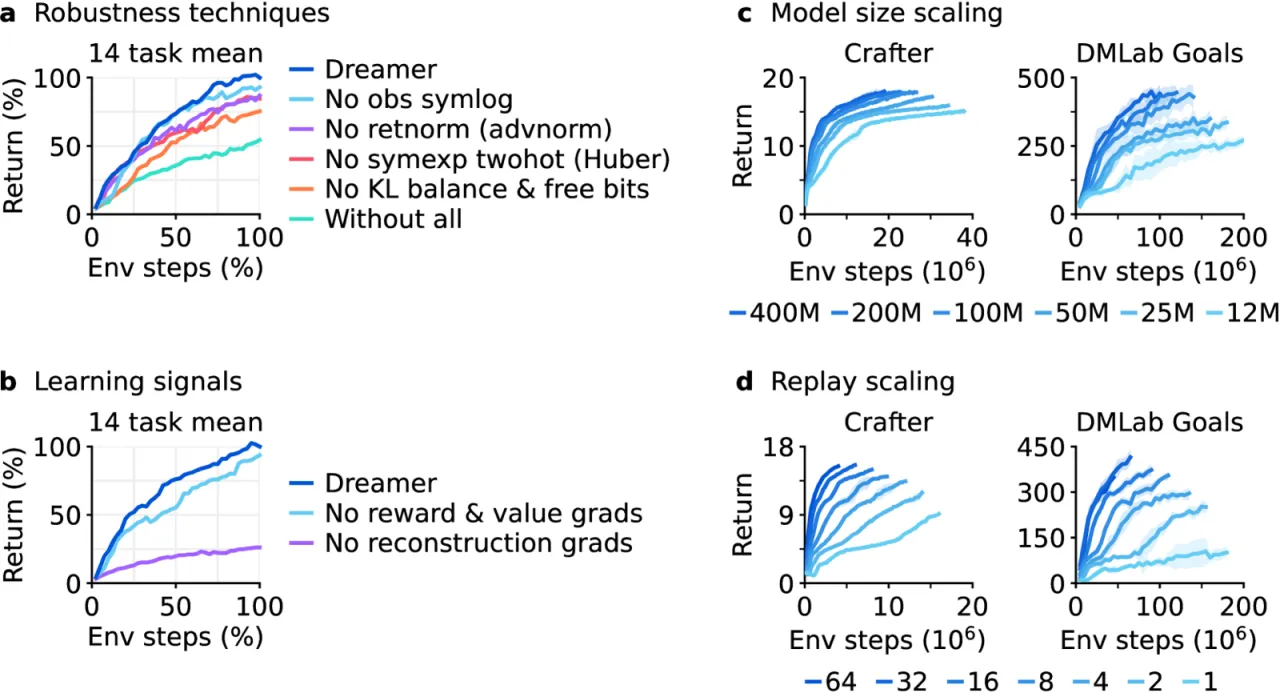
现有专用算法(MuZero、PPG、IMPALA 等)在各自领域表现优异,却无法直接迁移:不同任务的奖励量纲、观测模态(图像/本体感知/向量)、回报范围差异极大,导致相同的损失函数和归一化假设在跨域时崩溃。DreamerV3 的目标是用一套固定超参数覆盖连续控制、离散游戏、3D 导航、开放世界等所有场景。
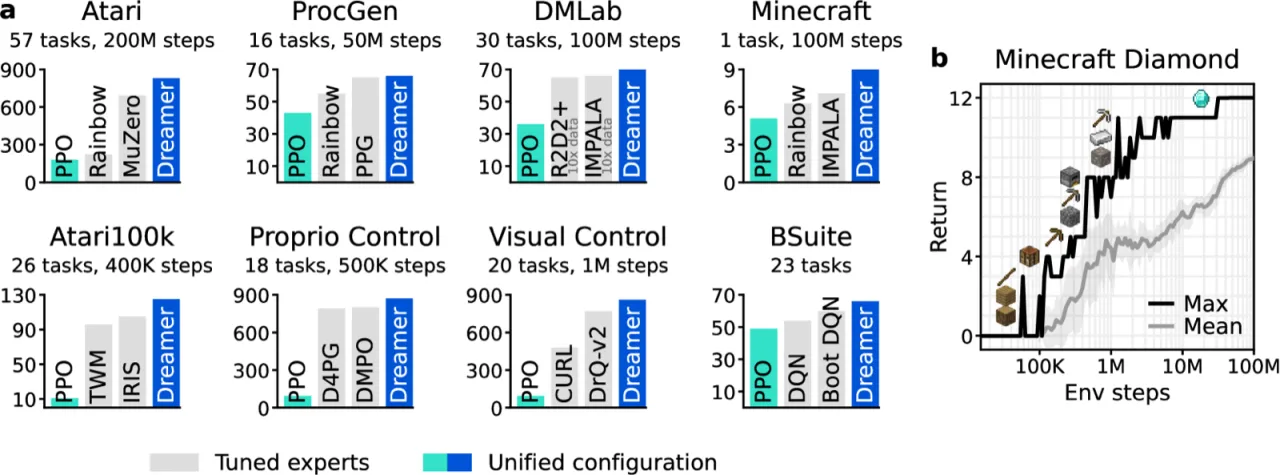
150+评测任务总数
1×超参数配置(无调参)
1 GPUMinecraft 训练仅需 1 张 A100 × 9 天
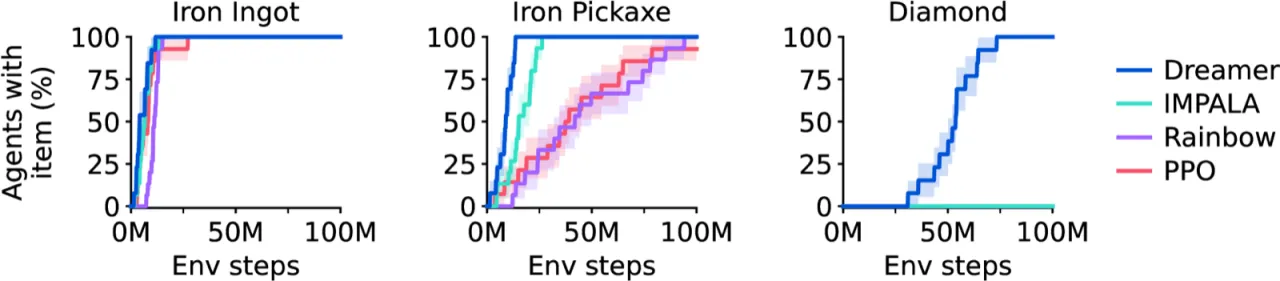
100%Dreamer 代理均发现 Minecraft 钻石