01 动机 Motivation
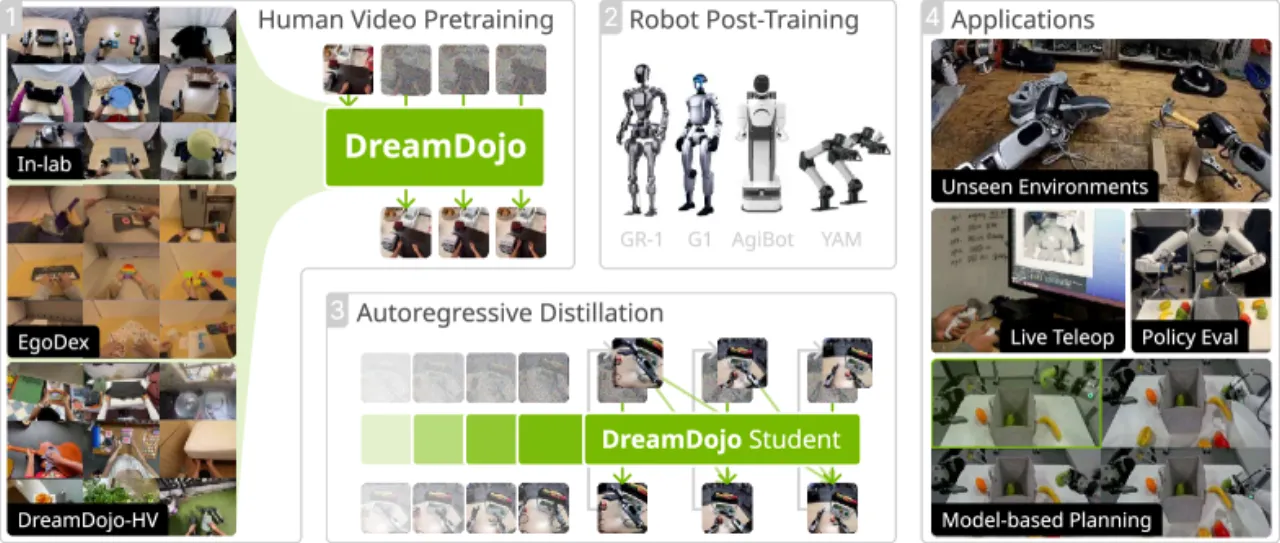
机器人操作任务面临两大核心瓶颈:现有世界模型训练数据极度匮乏,而视频中动作标注又极为稀缺。如何从海量无标注的人类日常视频中高效提取交互知识,是构建通用机器人世界模型的关键难题。
"Being able to simulate the outcomes of actions in varied environments will revolutionize the development of generalist agents at scale. However, modeling these world dynamics, especially for dexterous robotics tasks, poses significant challenges due to limited data coverage and scarce action labels."
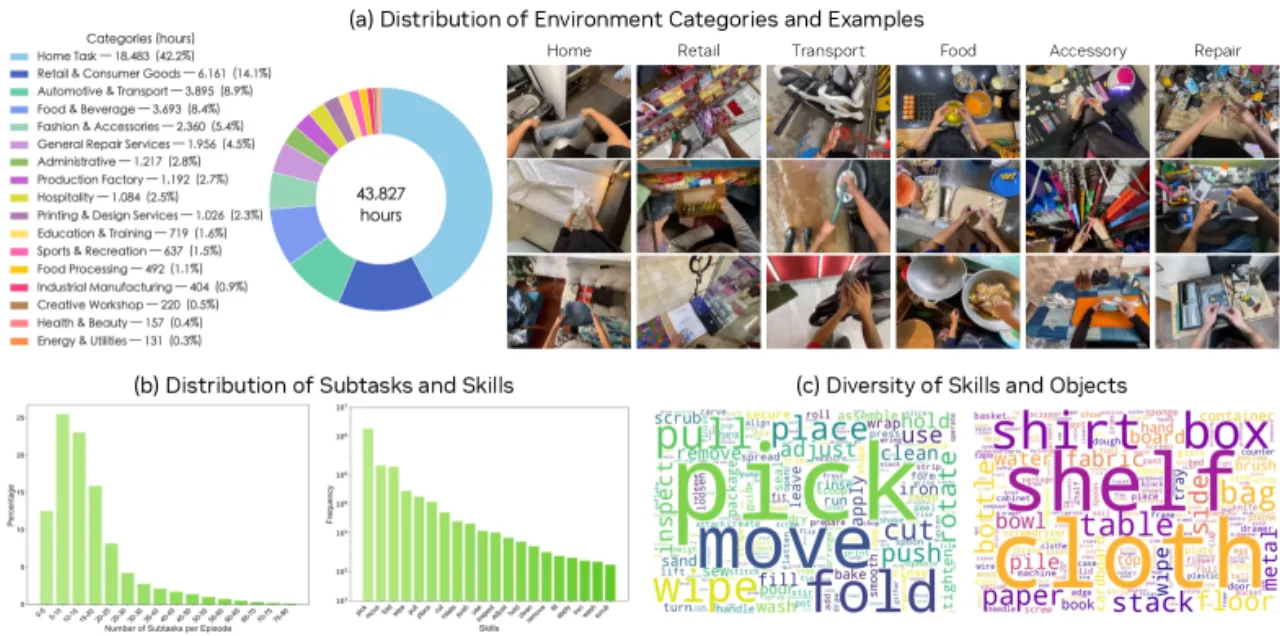
44k小时 egocentric 人类视频(史上最大世界模型预训练数据集)
1,179k轨迹数量
≥6,015unique 技能种类
10.81 FPS蒸馏后实时推理速度(较 teacher 提升近 4×)
与已有机器人世界模型数据相比,DreamDojo 数据集在规模上具有压倒性优势:视频时长长 15×,技能种类多 96×,场景数量多 2,000×。