01 动机
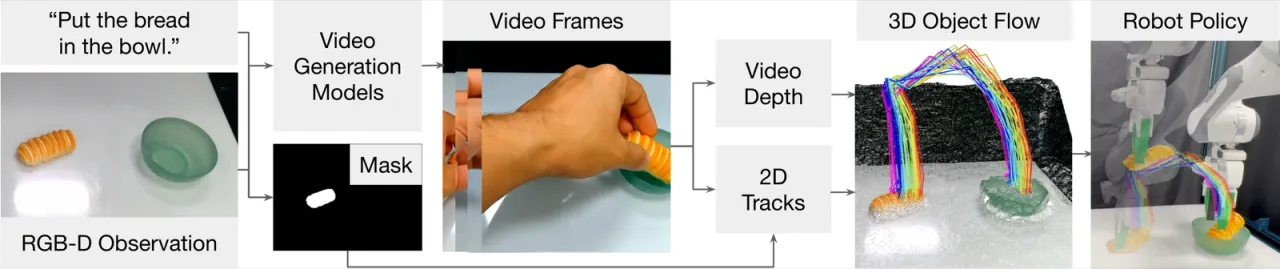
前沿视频生成模型已能合成逼真的人类操作场景,但如何将其中蕴含的物理知识转化为机器人可执行的指令,仍是一个开放难题。核心挑战在于:视频描述的是物体状态变化,而机器人需要的是驱动这些变化的执行器动作——两者之间存在巨大的 embodiment gap。
"Generative video modeling has emerged as a compelling tool to zero-shot reason about plausible physical interactions for open-world manipulation. Yet, it remains a challenge to translate such human-led motions into the low-level actions demanded by robotic systems."
现有方法通常试图直接从视频帧预测关节角度,但视频模型对具身细节(手型、关节构型)的模拟往往失真,导致难以直接跟随。Dream2Flow 的洞察是:物体的运动轨迹比执行器动作更稳定、更可迁移——无论使用哪种机器人,"把面包放进碗里"这一动作都要求面包沿相似的 3D 路径运动。

60真实世界总评估试验次数
80%端到端任务成功率(40/44 成功流)
4支持物体类别:刚性 / 关节 / 可变形 / 颗粒
3测试机器人平台(Franka、Spot、GR1)