01 动机
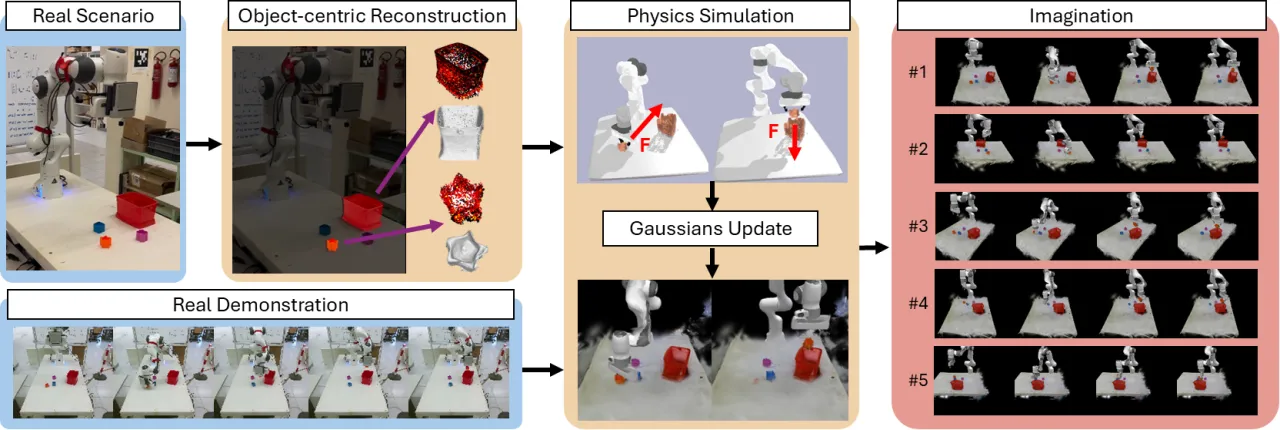
机器人操控策略学习面临一个根本性挑战:如何从极少量的示范中泛化到未见过的物体配置?现有世界模型往往在训练分布之外产生不真实的"幻觉",无法提供可靠的数据增广。
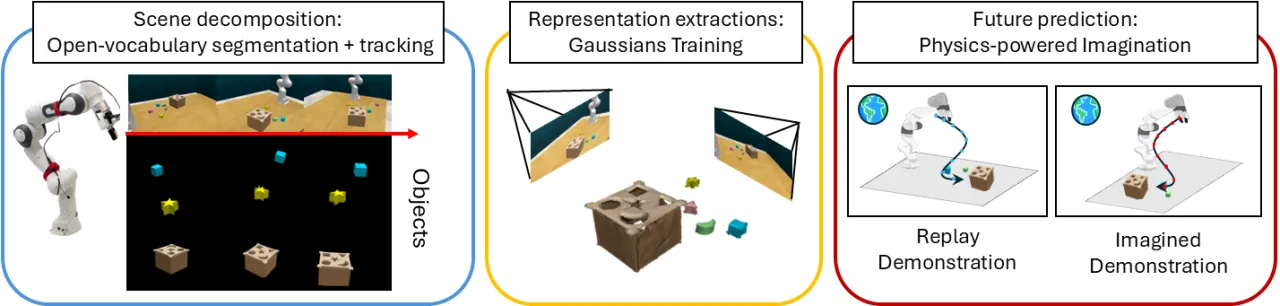
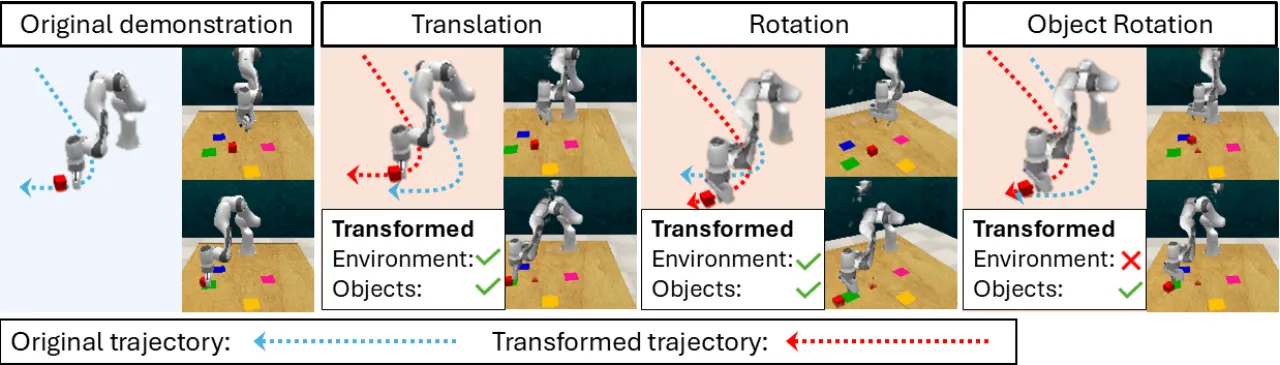
"We present DreMa, which builds a compositional manipulation world model, treated as a learnable digital twin of the environment, that explicitly models the environment composing object assets, a robot agent model, world dynamics, and manipulation tasks."
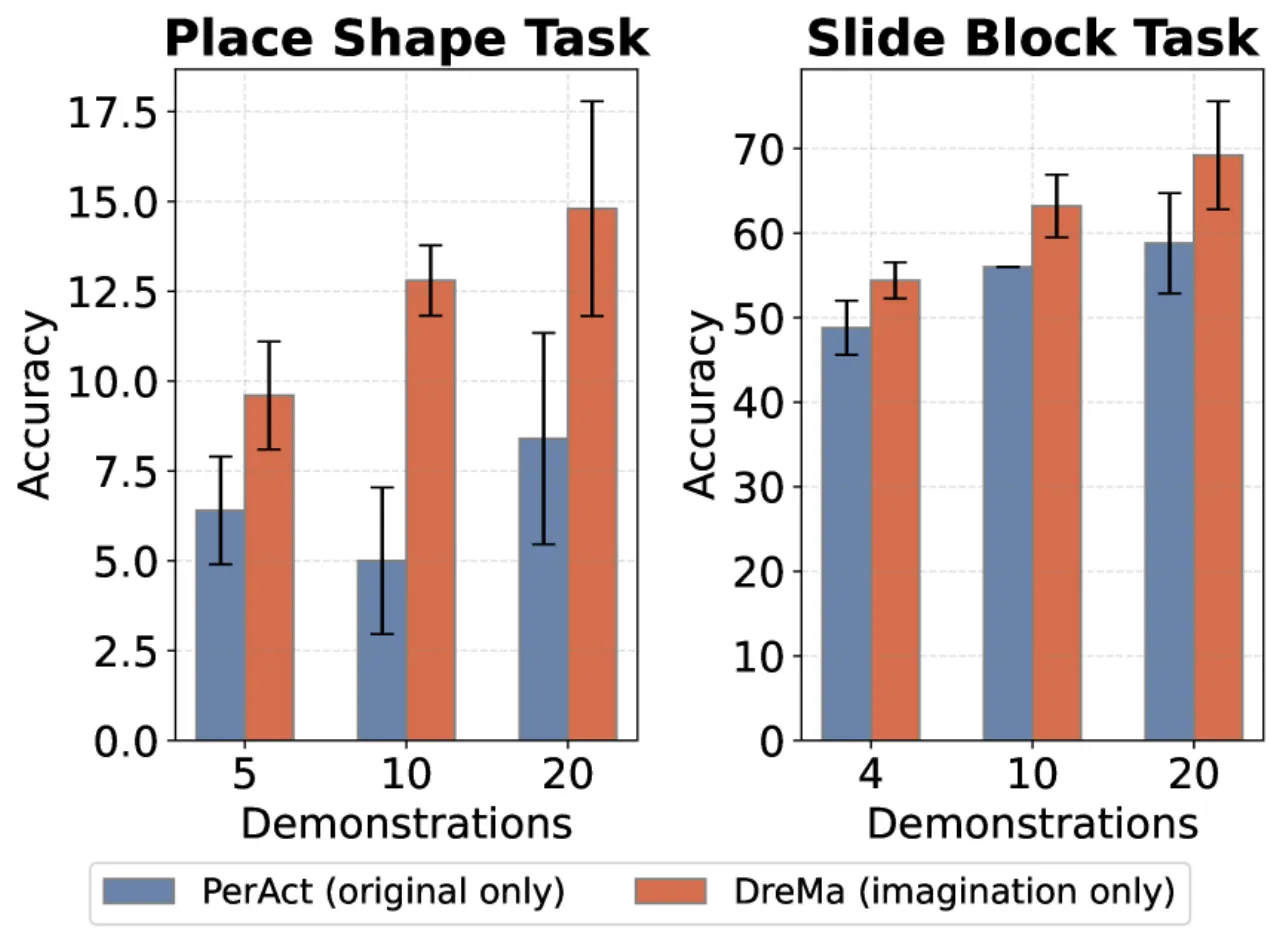
+9.1%单任务平均成功率提升(vs PerAct 基线,仿真)
+13.1%多任务平均成功率提升(vs PerAct 基线,仿真)
62.9%真实机器人分布内成功率(DreMa,5个任务均值)
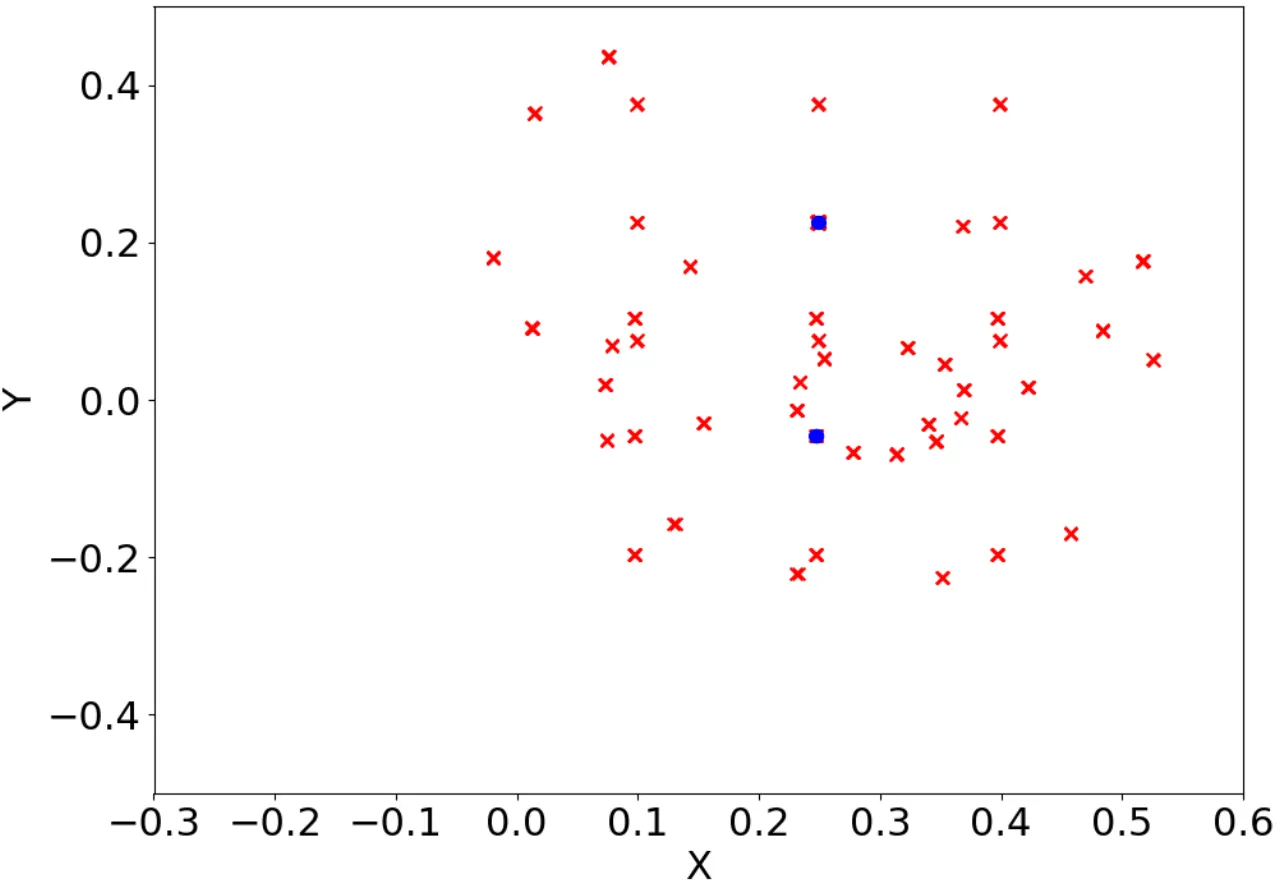
1-shot真实机器人每任务变体所需示范数