01 动机 Motivation
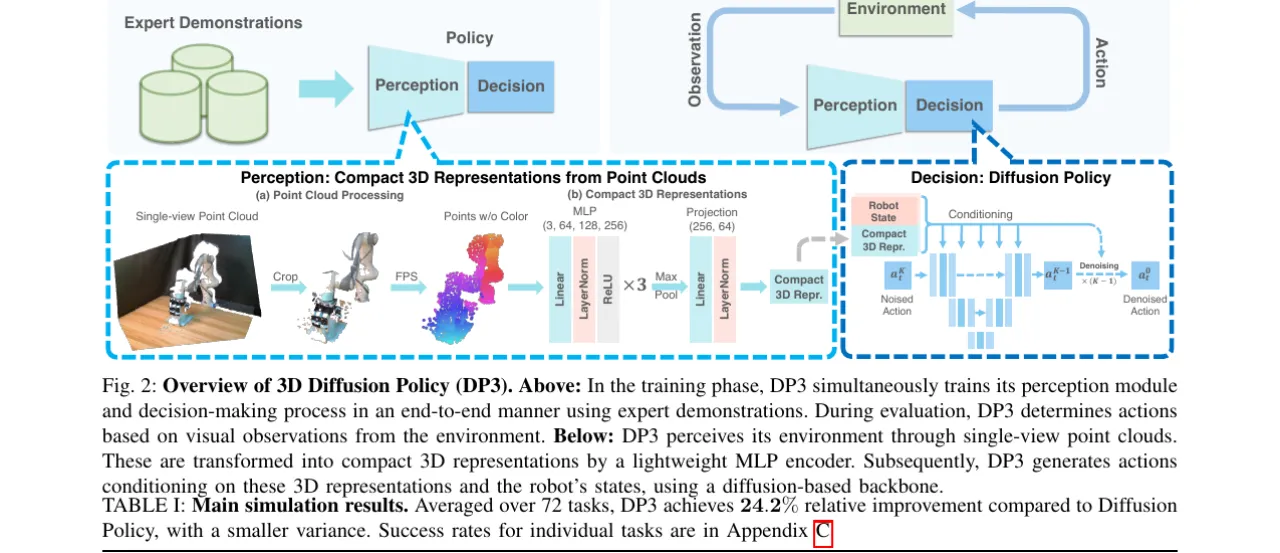
模仿学习为机器人提供了一条习得复杂技能的有效路径,但现有方法主要依赖 2D 图像或深度图作为视觉输入,在处理空间理解、视角变化与实例泛化等问题时存在明显局限。如何以最简单的方式引入 3D 信息,同时保持策略学习的高效性与泛化性,是本文要解决的核心问题。
"Enabling robots to dexterous manipulation of objects is a longstanding challenge for roboticists, primarily due to the necessity to manage a broader spectrum of motor skills… Visual imitation learning, which takes high-dimensional visual observations such as images or depth maps, eases the need for task-specific state estimation and thus gains its popularity."
现有方法(如 Diffusion Policy)以 2D RGB 图像为输入,面临两大核心挑战:
- 空间感知不足:2D 图像缺乏深度信息,难以精确理解物体在三维空间中的位置与形状,对灵巧操作(如倒液、卷薄片)尤为不利。
- 泛化能力有限:基于图像的策略对视角变化、光照变化和目标外观变化高度敏感,往往需要大量多样化的演示数据才能泛化。
本文核心假设:稀疏点云提供的紧凑 3D 表征天然具备几何一致性,无需颜色通道即可实现优越的泛化,且单视角点云(仅一台 RealSense L515 相机)已足够。

72仿真任务总数
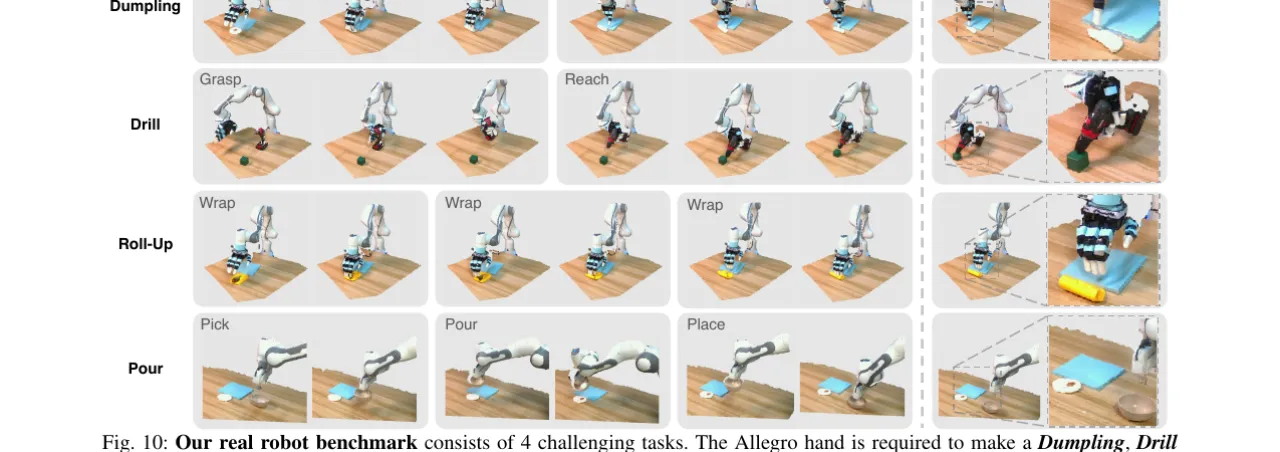
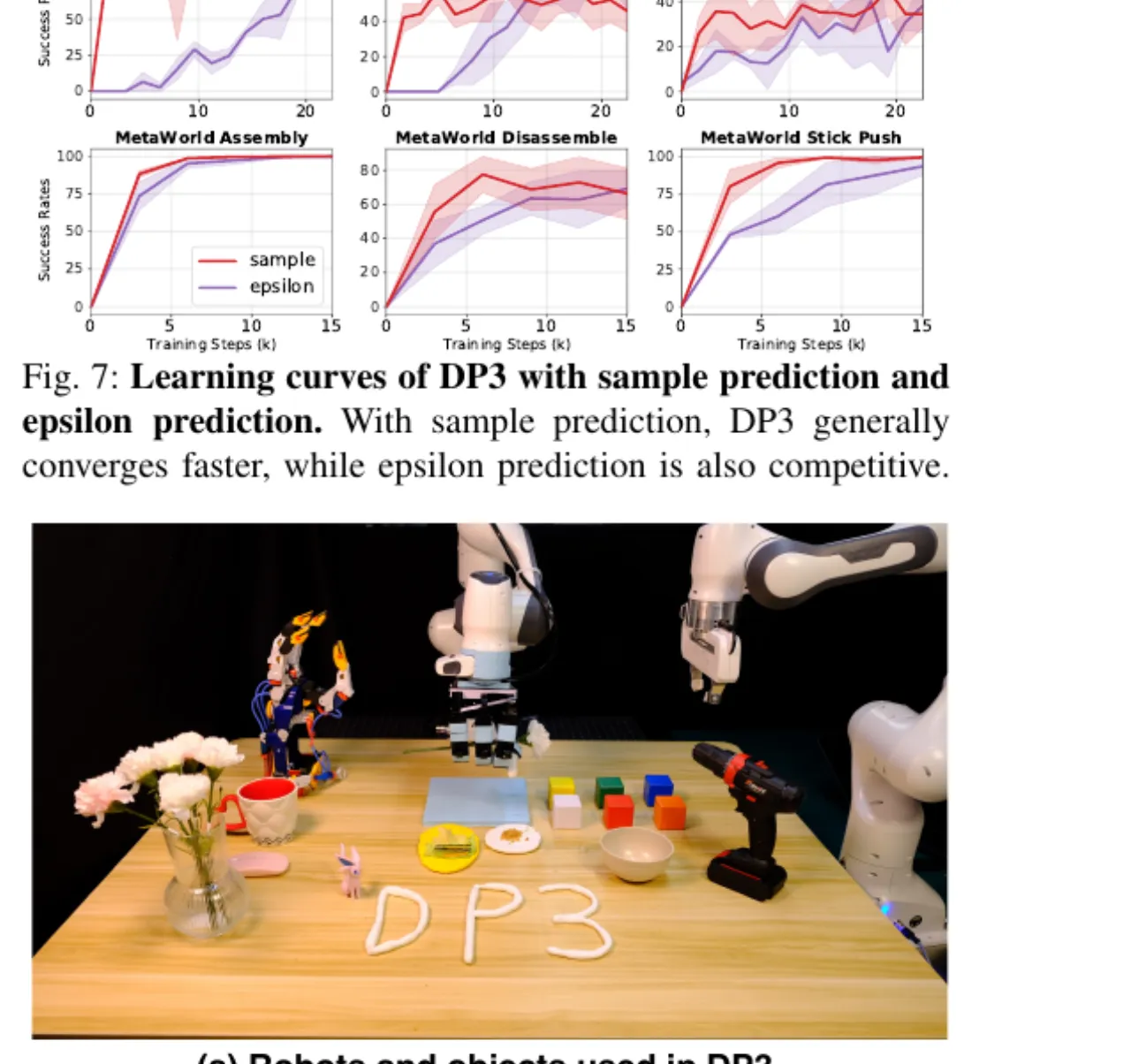
85%真实机器人平均成功率
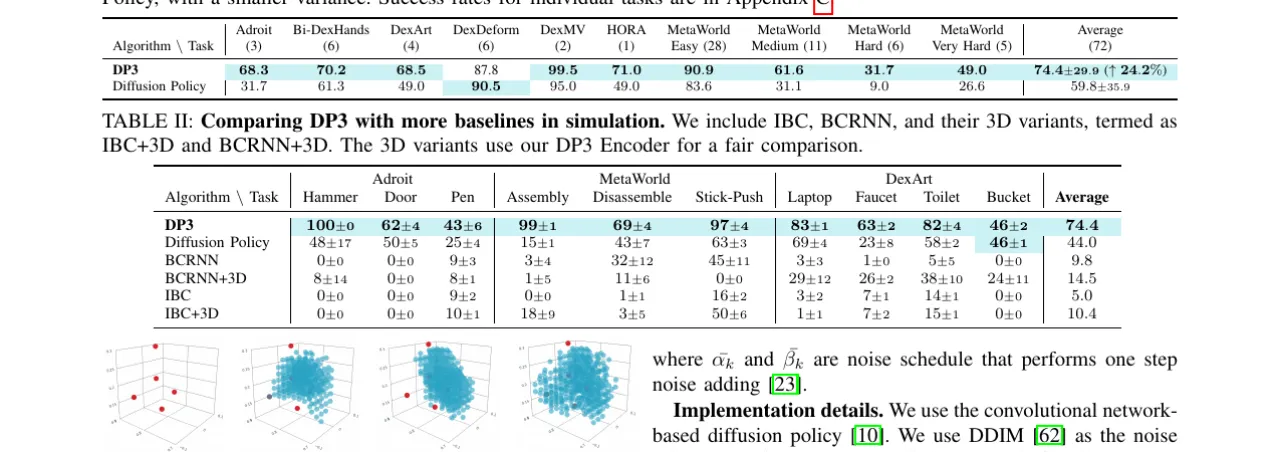
74.4仿真平均成功率(DP3)vs 59.8(Diffusion Policy)
24.2%相对提升(vs Diffusion Policy)