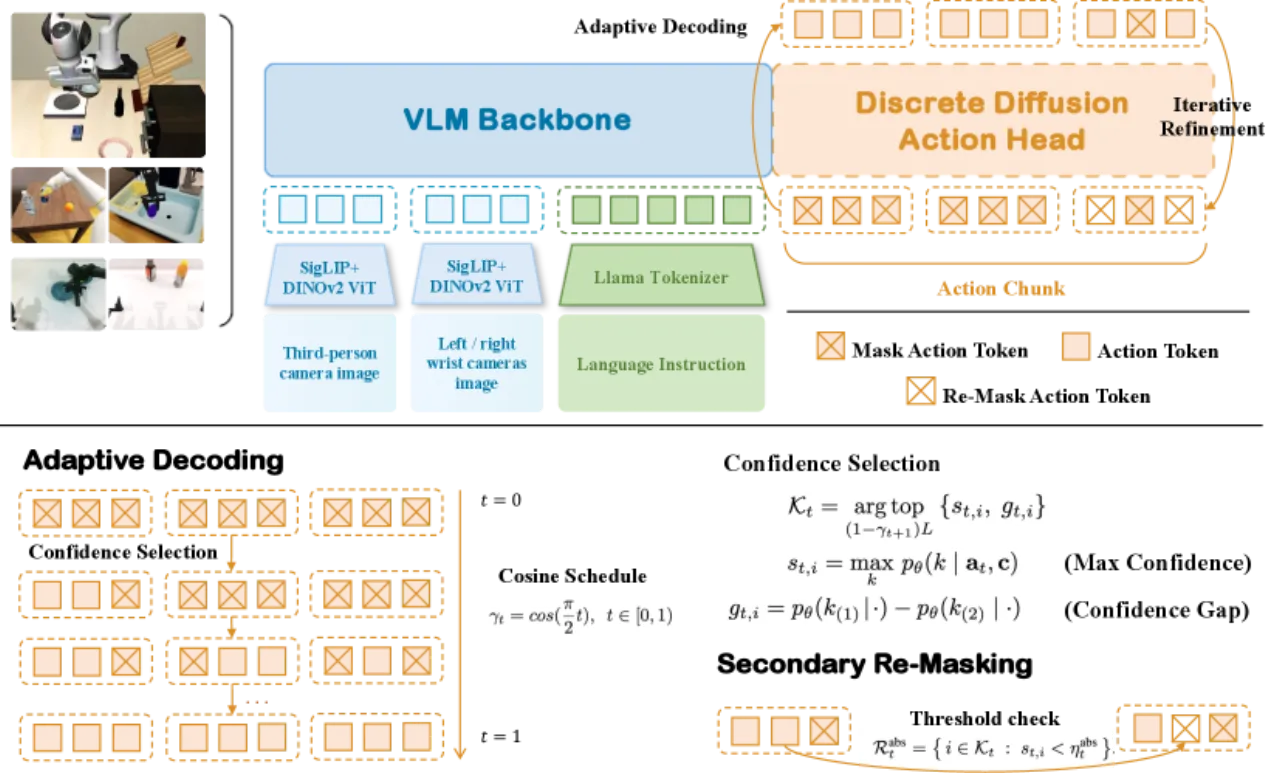
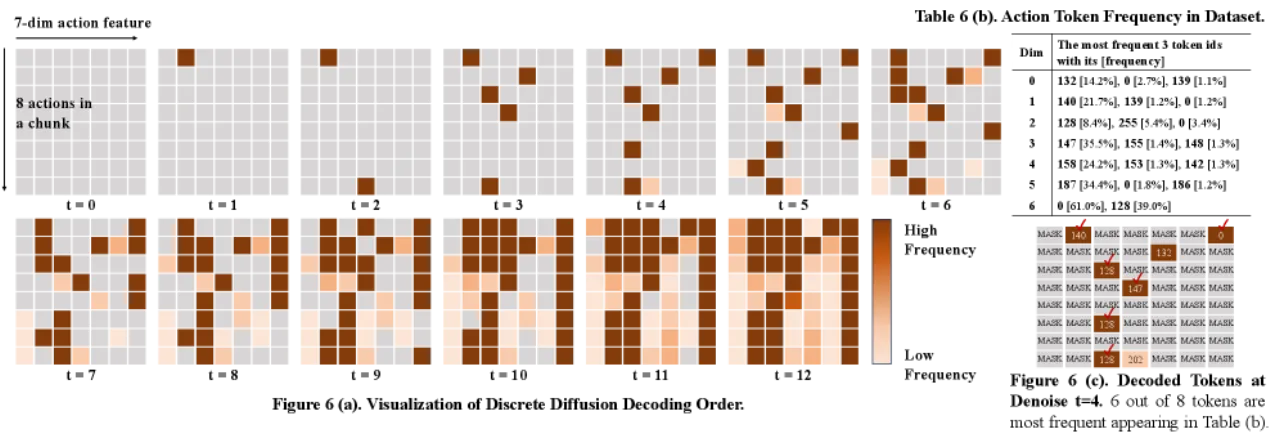01 动机
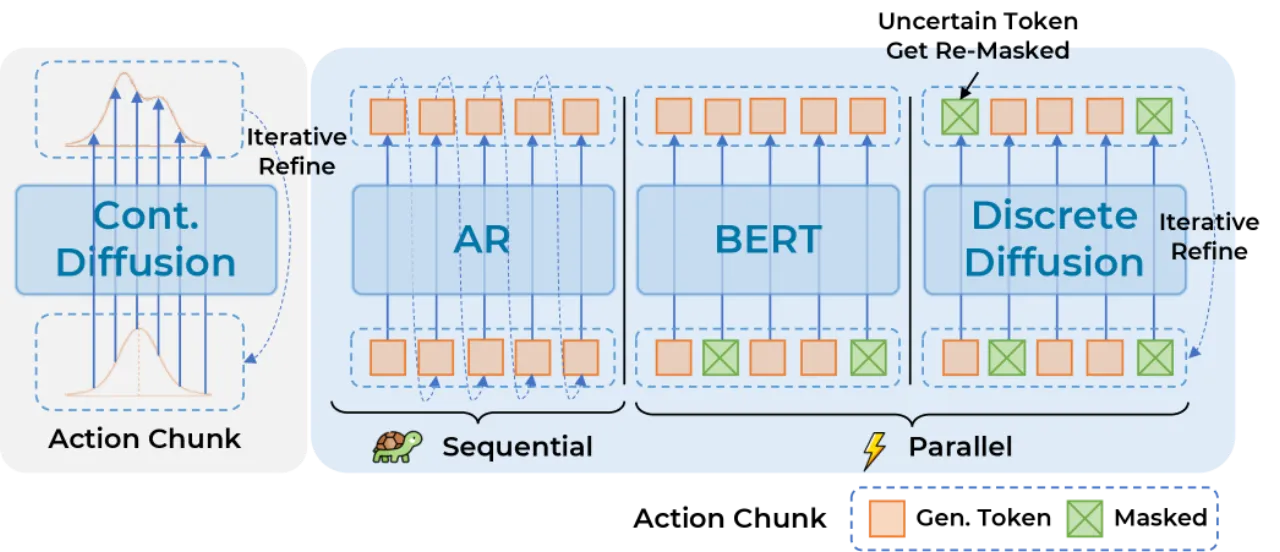
当前 VLA 动作解码范式面临两大根本性缺陷:自回归方法存在从左到右的累积误差与推理效率低下问题;而将独立扩散头附加于主干之外的方式,则割裂了信息通路,并损害了视觉语言预训练能力。
"This design not only complicates policy training but also degrades the pretrained vision-language capabilities, which represents a critical issue we address in this work."
96.4%LIBERO 平均成功率(离散方法最优)
71.2%SimplerEnv-Fractal Visual Matching
54.2%SimplerEnv-Bridge 整体成功率
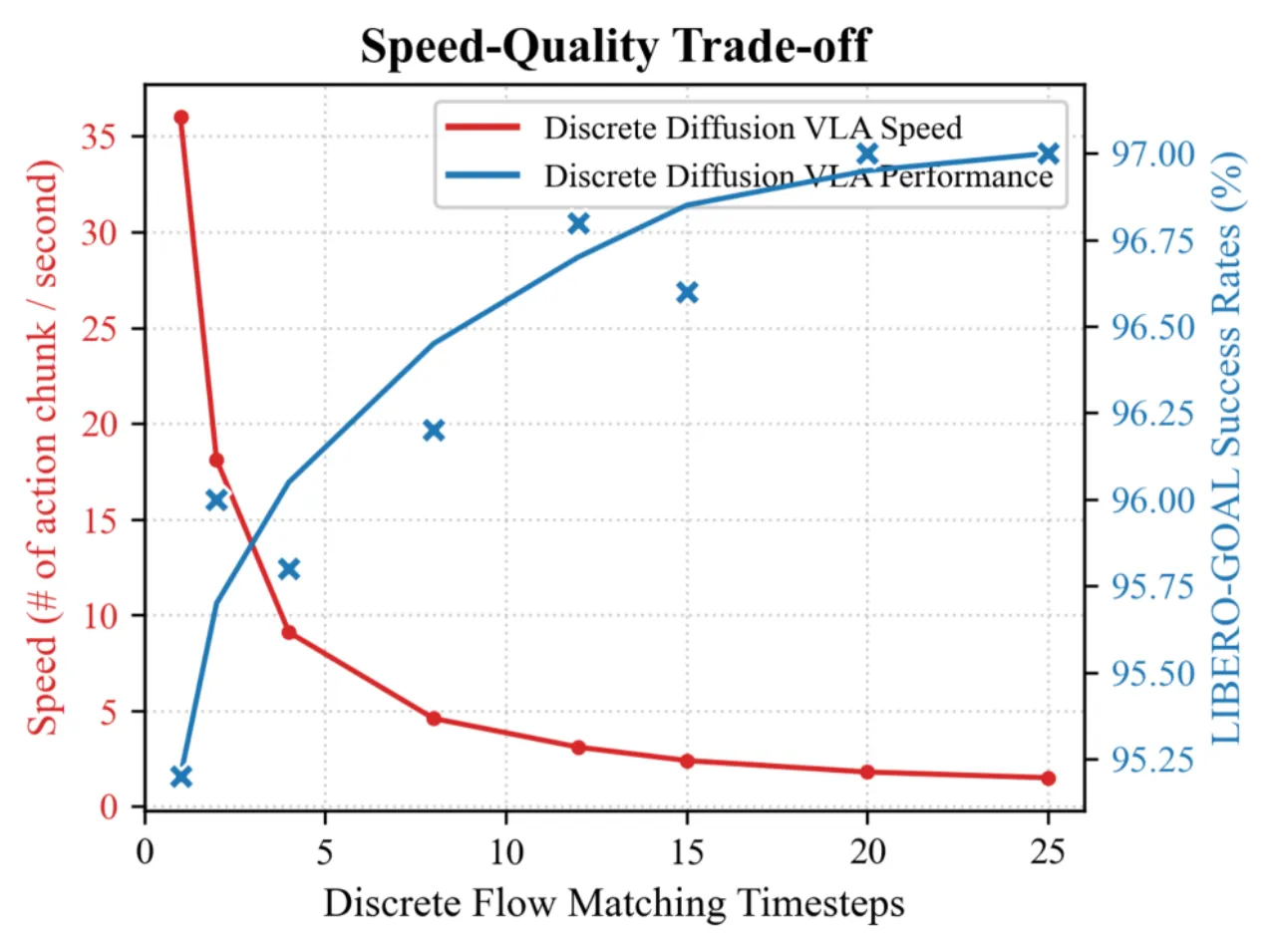
14.53 Hz实时控制频率(12 步去噪)
核心洞察在于:离散扩散与大语言模型的预训练目标(交叉熵)天然一致——训练时均以掩码 token 的预测为优化目标,因此不需要引入竞争性梯度信号,即可在同一主干内同时保留视觉语言推理能力和动作生成能力。